人工智能之模式识别(二)
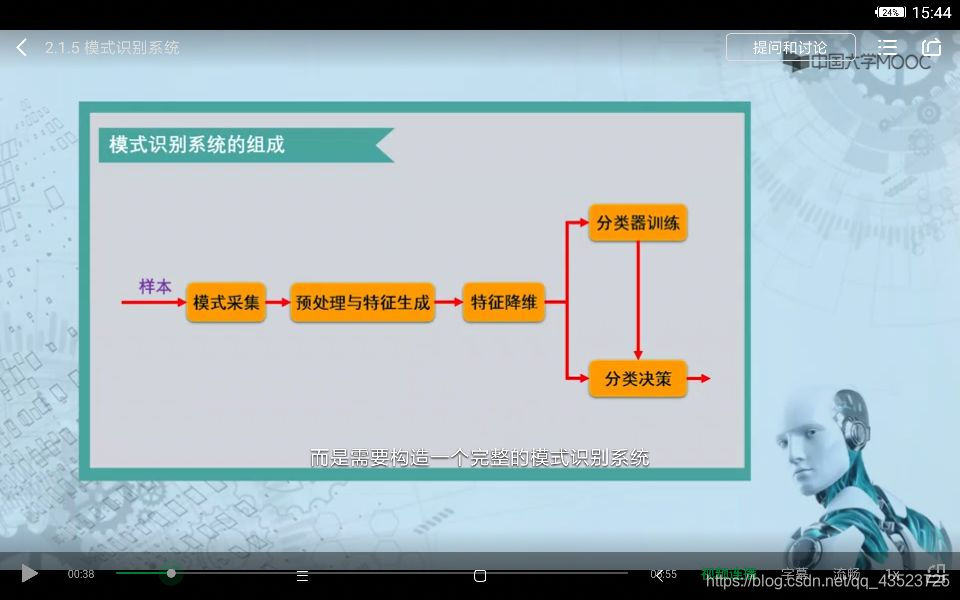
一、模式识别系统组成模式识别依赖于样本。1.样本采集首先,要采集样本,采集方式可能是从网上获取资源,如图片数据集,可能自行用传感器等设备采集;2.预处理与特征生成经过采集的数据一般都需要进行预处理,对图片进行矫正,或者将模拟信号转为数字信号,滤波降噪等等;预处理之后得到的特征维度一般都比较高,需要进行特征降维;3.特征降维特征降维一般采取两种方式,一种是特征选择,指的是从多维特征中选...
一、模式识别系统组成
模式识别依赖于样本。
1.样本采集
首先,要采集样本,采集方式可能是从网上获取资源,如图片数据集,可能自行用传感器等设备采集;
2.预处理与特征生成
经过采集的数据一般都需要进行预处理,对图片进行矫正,或者将模拟信号转为数字信号,滤波降噪等等;预处理之后得到的特征维度一般都比较高,需要进行特征降维;
3.特征降维
特征降维一般采取两种方式,一种是特征选择,指的是从多维特征中选择出一些特征代替原高维特征,保留对分类最有效的特征,比如mtcnn人脸识别中选择特征中的第一维作为最终获得的特征
还有一种方法是特征提取,将高维特征映射成较低维的特征,PCA应该是属于特征提取方法吧,经过降维的特征就可投入训练
(个人觉得,预处理操作之后得到的数据只能称为样本,还不能称为特征,要经过某种算法,提取了特征,然后再考虑降维,比如PCA等等。目前仅接触过一些深度学习算法,对全局还没有把握,不喜勿喷)
4.训练与决策
训练可以分为有监督训练和无监督训练
有监督训练指的是训练样本的类别由人来定义,
无监督训练指的是机器自行根据样本间相似度进行划分类别
无监督训练更具智能性,是未来发展重点
二、模式识别算法体系
模式识别算法大体可以分为两种:一种是统计模式识别,主流方法,另一种是结构模式识别
1.统计模式识别
1.1线性分类器:寻找线性最优分类边界(支持向量机是为了解决线性分类的局限性才被提出的)
1.2贝叶斯分类器:根据不同类的样本的概率分布,利用逆概率的贝叶斯分布进行分类
1.3最近邻分类器:将训练融于决策中,在测试时,从训练样本中寻找最相似的答案
1.4神经网络分类器:目前比较火的,比如深度学习,高度非线性
1.5统计聚类分类器:无监督学习。我的理解是将相似的样本聚集在一起,测试时计算与每个类之间的“距离”,与哪个类距离最近,就是哪个类,也有输出n个结果,像累计分数一样地累计各类别结果数,看哪个类别的数量最多,就归到哪个类
2.结构模式识别:以结构相似度作为类别划分的关键
2.1结构聚类算法
2.2句法模式识别


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)