
简单的mongoDB数据库搭建及使用
目录一、关系数据库特性二、NoSQL数据库分类三、RDBMS与MongoDB对应的术语四、MongoDB数据库4.1linux下MongoDB 单节点安装4.2连接操作4.3创建数据库4.4删除数据库4.4.1删除数据库中集合4.5插入文档4.5.1insert()方法4.5.2 save()方法4.6 查询文档4.6.1M...
目录
一、关系数据库特性
1、A (Atomicity) 原子性
原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。
比如银行转账,从A账户转100元至B账户,分为两个步骤:1)从A账户取100元;2)存入100元至B账户。这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100元。
2、C (Consistency) 一致性(没用过好像)
一致性也比较容易理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
例如现有完整性约束a+b=10,如果一个事务改变了a,那么必须得改变b,使得事务结束后依然满足a+b=10,否则事务失败。
3、I (Isolation) 独立性
所谓的独立性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
比如现有有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的。
4、D (Durability) 持久性
持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
二、NoSQL数据库分类
| 类型 | 部分代表 | 特点 |
| 列存储 | Hbase Cassandra Hypertable | 顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势。 |
| 文档存储 | MongoDB CouchDB | 文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有机会对某些字段建立索引,实现关系数据库的某些功能。 |
| key-value存储 | Tokyo Cabinet / Tyrant Berkeley DB MemcacheDB Redis | 可以通过key快速查询到其value。一般来说,存储不管value的格式,照单全收。(Redis包含了其他功能) |
| 图存储 | Neo4J FlockDB | 图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方便。 |
| 对象存储 | db4o Versant | 通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据。 |
| xml数据库 | Berkeley DB XML BaseX | 高效的存储XML数据,并支持XML的内部查询语法,比如XQuery,Xpath。 |
三、RDBMS与MongoDB对应的术语
| RDBMRDBMSS | MonMongoDBgoDB |
| 表格 | 集合 |
| 行 | 文档 |
| 列 | 字段 |
| 表联合 | 嵌入文档 |
| 主键 | 主键 (MongoDB 提供了 key 为 _id ) |
| 数据库服务和客户端 | |
| Mysqld/Oracle | mongod |
| mysql/sqlplus | mongo |
四、MongoDB数据库
4.1 linux下MongoDB 单节点安装
1、环境变量配置

执行source .bash_profile
注意:这个需要重新进一次shell。
2、启动服务端
![]()
出现问题(如果不出现,上面就可以直接启动):
![]()
解决办法:
加上--storageEngine=mmapv1 其实这个就是出现的问题里提示的
解决后:
![]()
这就正常启动了,其中--dbpath=/home/songbw/Mongo/data/db是MongoDB的数据存储的位置,但是这个目录在安装过程不会自动创建,所以需要手动创建data目录,并在data目录中创建db目录。
3、启动客户端
![]()
因为我的无密码
4.2 连接操作
有密码连接方式如下:
mongodb://admin:123456@localhost/test
其中mongobd://是固定的,后面的格式如下
username:password@hostname/dbname
4.3 创建数据库
语法
MongoDB 创建数据库的语法格式如下:
use DATABASE_NAME
如果数据库不存在,则创建数据库,否则切换到指定数据库。
实例
以下实例我们创建了数据库runoob:
> use runoob
switched to db runoob
> db
runoob
>
其中db是显示当前数据库的名字
如果你想查看所有数据库,可以使用 show dbs 命令:
> show dbs
local 0.078GB
test 0.078GB
>
可以看到,我们刚创建的数据库runoob 并不在数据库的列表中, 要显示它,我们需要向 runoob 数据库插入一些数据。




插入语句后面会讲,这里的runoob不是代表的数据库,而是表runoob,如下:




而且MongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。
4.4 删除数据库
语法
MongoDB 删除数据库的语法格式如下:
db.dropDatabase()
删除当前数据库,可以使用db 命令查看当前数据库名。
实例
以下实例我们删除了数据库runoob。
首先,查看所有数据库:
> show dbs
local 0.078GB
runoob 0.078GB
test 0.078GB
接下来我们切换到数据库runoob:
> use runoob
switched to db runoob
>
执行删除命令:
> db.dropDatabase()
{ "dropped" : "runoob", "ok" : 1 }
最后,我们再通过show dbs 命令数据库是否删除成功:
> show dbs
local 0.078GB
test 0.078GB
>
4.4.1 删除数据库中集合
集合删除语法格式如下:
db.collection.drop()



实验不成功啊,为什么删除是false呢
知道为什么,中间的collection要换成具体的集合啊,如下:




其中db.col.insert({title:'MongoDB教程',description:'MongoDB是一个Nosql数据库',by:'菜鸟教程'})
是往集合col中插入一条数据,而db.col.find()是查找col集合中的东西,db.col.drop()就是删除集合col,所以要删除集合,你得知道集合的名字
4.5 插入文档
MongoDB 使用 insert() 或 save() 方法向集合中插入文档,语法如下:
db.COLLECTION_NAME.insert(document)
4.5.1 insert() 方法
插入文档有两种方式
a、直接插入
实例
以下文档可以存储在MongoDB 的 runoob 数据库 的 col集合中:
>db.col.insert({title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '菜鸟教程',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})
以上实例中col 是我们的集合名,如果该集合不在该数据库中, MongoDB 会自动创建该集合并插入文档。
查看已插入文档:
> db.col.find()
{ "_id" : ObjectId("56064886ade2f21f36b03134"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "菜鸟教程", "url" : "http://www.runoob.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 }
>
b、将数据定义为一个变量再插入
实例
我们也可以将数据定义为一个变量,如下所示:
> document=({title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '菜鸟教程',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
});
执行后显示结果如下:
{
"title" : "MongoDB 教程",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "菜鸟教程",
"url" : "http://www.runoob.com",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
执行插入操作:
> db.col.insert(document)
WriteResult({ "nInserted" : 1 })
>
4.5.2 save()方法
插入文档你也可以使用db.col.save(document) 命令。如果不指定 _id 字段 save() 方法类似于 insert() 方法。如果指定 _id 字段,则会更新该 _id 的数据。
具体解释见4.8.2
4.6 查询文档
语法
MongoDB 查询数据的语法格式如下:
>db.COLLECTION_NAME.find()
find() 方法以非结构化的方式来显示所有文档。
如果你需要以易读的方式来读取数据,可以使用pretty() 方法,语法格式如下:
>db.col.find().pretty()
pretty() 方法以格式化的方式来显示所有文档。
实例
以下实例我们查询了集合col 中的数据:
> db.col.find().pretty()
{
"_id" : ObjectId("56063f17ade2f21f36b03133"),
"title" : "MongoDB 教程",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "菜鸟教程",
"url" : "http://www.runoob.com",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
除了find() 方法之外,还有一个 findOne() 方法,它只返回一个文档。
总结:sql中查询语句select …… from …… where ……与db.col.find()的对比:
col相当于select后面的表名
db.col.find()中小括号里面是查询条件,相当于where后面的条件
4.6.1 MongoDB中where子句
MongoDB与RDBMS Where语句比较
如果你熟悉常规的SQL 数据,通过下表可以更好的理解 MongoDB 的条件语句查询:
| 操作 | 格式 | 范例 | RDBMS中的类似语句 |
| 等于 | {<key>:<value>} | db.col.find({"by":"菜鸟教程"}).pretty() | where by = '菜鸟教程' |
| 小于 | {<key>:{$lt:<value>}} | db.col.find({"likes":{$lt:50}}).pretty() | where likes < 50 |
| 小于或等于 | {<key>:{$lte:<value>}} | db.col.find({"likes":{$lte:50}}).pretty() | where likes <= 50 |
| 大于 | {<key>:{$gt:<value>}} | db.col.find({"likes":{$gt:50}}).pretty() | where likes > 50 |
| 大于或等于 | {<key>:{$gte:<value>}} | db.col.find({"likes":{$gte:50}}).pretty() | where likes >= 50 |
| 不等于 | {<key>:{$ne:<value>}} | db.col.find({"likes":{$ne:50}}).pretty() | where likes != 50 |
其中likes是文档中的一个字段
4.6.2 MongoDB AND条件
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,相当于常规 SQL 的 AND 条件。
语法格式如下:
>db.col.find({key1:value1, key2:value2}).pretty()
实例
以下实例通过 by 和 title 键来查询 菜鸟教程 中 MongoDB 教程 的数据
> db.col.find({"by":"菜鸟教程", "title":"MongoDB 教程"}).pretty()
{
"_id" : ObjectId("56063f17ade2f21f36b03133"),
"title" : "MongoDB 教程",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "菜鸟教程",
"url" : "http://www.runoob.com",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
以上实例中类似于WHERE 语句:WHERE by='菜鸟教程' AND title='MongoDB 教程'
4.6.3 MongoDB OR条件
MongoDB OR 条件语句使用了关键字 $or,语法格式如下:
>db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
实例
以下实例中,我们演示了查询键 by 值为菜鸟教程或键 title 值为 MongoDB 教程 的文档。
>db.col.find({$or:[{"by":"菜鸟教程"},{"title": "MongoDB 教程"}]}).pretty()
{
"_id" : ObjectId("56063f17ade2f21f36b03133"),
"title" : "MongoDB 教程",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "菜鸟教程",
"url" : "http://www.runoob.com",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
>
4.6.4 AND 和OR 的联合使用
以下实例演示了AND 和 OR 联合使用,类似常规 SQL 语句为: 'where likes>50 AND (by = '菜鸟教程' OR title = 'MongoDB 教程')'
- 我自己写的表达上面意思的mongo查询语句
db.col.find({{"likes",{$gt:50}},{$or:[{"by":"菜鸟教程"},{"title": "MongoDB 教程"}]}}).pretty()
出现错误:
2016-11-22T18:04:29.324+0800 E QUERY [thread1] SyntaxError: invalid property id @(shell):1:13
- 正确的mongo查询语句
db.col.find({"likes":{$gt:50},$or:[{"by":"菜鸟教程"},{"title": "MongoDB 教程"}]}).pretty()
分析:
表达likes>50的mongo语句是:"likes":{$gt:50}
而表达by = '菜鸟教程' OR title = 'MongoDB 教程’的mongo语句是:
$or:[{"by":"菜鸟教程"},{"title": "MongoDB 教程"}]
我错就错在:对于这两个单独的语句,外层不应该再加{}了,否则就会出错,当我把中括号去掉后,就正确了。
4.6.5 $type操作符
$type操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果。
MongoDB 中可以使用的类型如下表所示:
| 类型 | 数字 | 备注 |
| Double | 1 |
|
| String | 2 |
|
| Object | 3 |
|
| Array | 4 |
|
| Binary data | 5 |
|
| Undefined | 6 | 已废弃。 |
| Object id | 7 |
|
| Boolean | 8 |
|
| Date | 9 |
|
| Null | 10 |
|
| Regular Expression | 11 |
|
| JavaScript | 13 |
|
| Symbol | 14 |
|
| JavaScript (with scope) | 15 |
|
| 32-bit integer | 16 |
|
| Timestamp | 17 |
|
| 64-bit integer | 18 |
|
| Min key | 255 | Query with -1. |
| Max key | 127 |
|
实例

使用find查找到集合col中有两个文档




db.col.find({"name":{$type:2}}) 是查找到name的类型为string的文档,类型对应的数字见上表。

db.col.find({"name":{$type:1}}) 是查找到name的类型为double的文档。
4.6.6 Limit()与Skip()方法
1、Limit()方法
如果你需要在MongoDB中读取指定数量的数据记录,可以使用MongoDB的Limit方法,limit()方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数。
语法
limit()方法基本语法如下所示:
>db.COLLECTION_NAME.find().limit(NUMBER)
实例



命令db.col.find() 查找到集合col中有4个文档
命令db.col.find({},{"name":1,"_id":0}).limit(2) 仅显示前两个文档,因为limit中的参数为2,但是有意外收获:
因为我之前一直以为mongo中的查询结果显示的都是完整的文档,不知道如何显示我想选择的字段,就像命令db.col.find({},{"name":1,"_id":0}).limit(2)中find小括号中的({},{"name":1,"_id":0}),第一个花括号为空,表示查询条件没有限制,而第二个花括号中的name字段为1,表示只显示name字段,而_id字段是时刻都带着的,如果不想显示_id字段就要写上”_id”:0,而其它的字段不写那就是不显示。
2、Skip()方法
我们除了可以使用limit()方法来读取指定数量的数据外,还可以使用skip()方法来跳过指定数量的数据,skip方法同样接受一个数字参数作为跳过的记录条数。
语法
skip() 方法脚本语法格式如下:
>db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
实例




不解释那么多了,命令db.col.find({},{"name":1,"_id":0}).limit(2).skip(2) 跳过前两条,显示了后两条的数据。
4.7 更新文档
4.7.1 update()方法
update() 方法用于更新已存在的文档。语法格式如下:
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:
- query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
- upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
实例
我们在集合col 中插入如下数据:
>db.col.insert({
title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '菜鸟教程',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})
接着我们通过update() 方法来更新标题(title):
>db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) # 输出信息
> db.col.find().pretty()
{
"_id" : ObjectId("56064f89ade2f21f36b03136"),
"title" : "MongoDB",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "菜鸟教程",
"url" : "http://www.runoob.com",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
>
可以看到标题(title)由原来的 "MongoDB 教程" 更新为了 "MongoDB"。
以上语句只会修改第一条发现的文档,如果你要修改多条相同的文档,则需要设置multi 参数为 true。
>db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}},{multi:true})
4.7.2 save()方法




如上图在runoob数据库的col集合中有4个文档,它们的文档id分别为:
"_id" : ObjectId("583403ddba241767138ac9f5")
"_id" : ObjectId("58340674ba241767138ac9f6")
"_id" : ObjectId("583403ddba241767138ac9f7")
"_id" : ObjectId("583508d899840df340a96983")
如果执行db.col.save( { "name":"duguqiubai", "sex":"male", "likes":199}),并没有指定_id字段,如下:




此时save()的功能就相当于插入文档中的insert(),插入了新的文档
{ "_id" : ObjectId("58350c7099840df340a96984"), "name" : "duguqiubai", "sex" : "male", "likes" : 199 }
如果执行
db.col.save({
... "_id" : ObjectId("58350c7099840df340a96984"),
... "name":"xiaofeng",
... "ages":"35",
... "likes":"200"})
里面有_id字段,此_id字段代表的文档在col集合中是存在的,就相当于更新_id字段所代表的文档,结果如下:
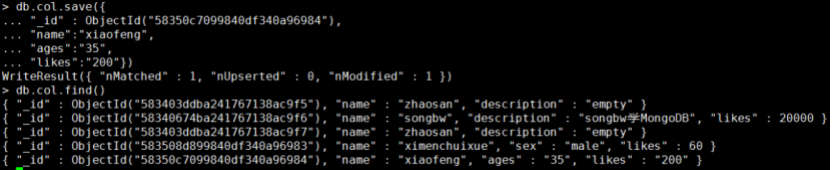

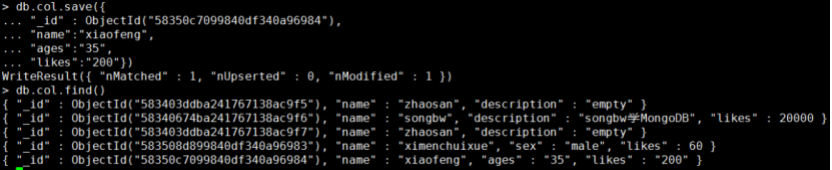
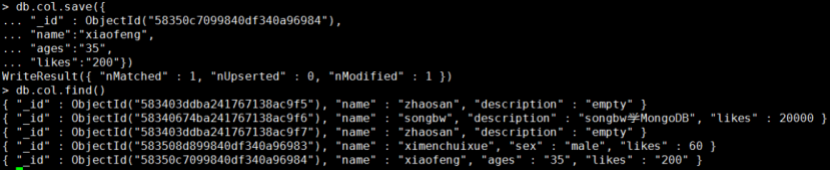
你会发现,对应的_id字段的文档由duguqiubai的信息完全改为了xaiofeng的信息了。
4.8 删除文档
MongoDB remove()函数是用来移除集合中的数据。在执行remove()函数前先执行find()命令来判断执行的条件是否正确,这是一个比较好的习惯。
语法
remove() 方法的基本语法格式如下所示:
db.collection.remove(
<query>,
<justOne>
)
如果你的MongoDB 是 2.6 版本以后的,语法格式如下:
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
参数说明:
- query :(可选)删除的文档的条件。
- justOne : (可选)如果设为 true 或 1,则只删除一个文档。
- writeConcern :(可选)抛出异常的级别。
实例1




如上,在col集合中,name为ximenchuixue的文档有3个,如果只想删除满足条件的一个,执行db.col.remove({"name":"ximenchuixue"},1),如下:




也即将justOne的值设置为true,如上,三个ximenchuixue的文档,我们就删除了一个
如果想全部删除,则db.col.remove({"name":"ximenchuixue"})




如上,剩余的两个ximenchuixue的文档也被删除了。
注意:显然我这里mongo用的是第一种语法格式
实例2
若想删除表中的所有数据,则为:
db.ent_record_bx_table.remove({})
意思是删除表 ent_record_bx_table 中的所有数据。
4.9 MongoDB排序
MongoDB sort()方法
在MongoDB中使用使用sort()方法对数据进行排序,sort()方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列。
语法
sort()方法基本语法如下所示:
>db.COLLECTION_NAME.find().sort({KEY:1})
实例




命令db.col.find({},{"name":1,"_id":0}).sort({"name":1}) 将文档按照name值进行升序排列
4.9 MongoDB索引
以后如果有需要的话再看
4.10 MongoDB复制原理
MongoDB复制是将数据同步在多个服务器的过程。
复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性,并可以保证数据的安全性。
4.10.1 MongoDB复制原理
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
MongoDB复制结构图如下所示:



以上结构图中,客户端从主节点读取数据,在客户端写入数据到主节点,主节点与从节点进行数据交互保障数据的一致性。
4.10.2 副本集特征
a N个节点的集群
b 任何节点可作为主节点
c 所有写入操作都在主节点上
d 自动故障转移
e 自动恢复
以上例子,部分摘自菜鸟教程,在此表示感谢

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)