基于java SDK语音识别技术概述与调研
语音识别技术概述与调研语音识别已经成为人工智能应用的一个重点,通过语音控制设备简单方便,在各个领域兴起了研究应用的热潮。数据、算法及芯片是语音识别技术的3个关键,大量优质的数据、精准快速的算法和高性能语音识别芯片是提升语音识别的核心。语音是人工智能产品的主要入口,乃兵家必争之地也。相关算法研究日新月异,CNN RNN CLRNN HMM LACE等模型都尤其优势,将多种算法综合运用修改更佳。一..
语音识别技术概述与调研
语音识别已经成为人工智能应用的一个重点,通过语音控制设备简单方便,在各个领域兴起了研究应用的热潮。数据、算法及芯片是语音识别技术的3个关键,大量优质的数据、精准快速的算法和高性能语音识别芯片是提升语音识别的核心。语音是人工智能产品的主要入口,乃兵家必争之地也。相关算法研究日新月异,CNN RNN CLRNN HMM LACE等模型都尤其优势,将多种算法综合运用修改更佳。
一、应用场景
目前语音识别在智能家居、智能车载、智能客服机器人方面有广泛的应用,未来将会深入到学习、生活、工作的各个环节。国内外许多大公司都在倾力研究此技术,并不断推出实际产品。比如科大讯飞的翻译器译呗,可实现汉语与各种语言之间的互译,效果不错。
百度借助自己的人工智能生态平台,推出了智能行车助手CoDriver。科大讯飞与奇瑞等汽车制造商合作,推出了飞鱼汽车助理,推进车联网进程。搜狗与四维图新合作推出了飞歌导航。云知声、思必驰在导航、平视显示器等车载应用方面推出了多款智能语控车载产品。出门问问则基于自己的问问魔镜进入到智能车载市场。
在语音识别的商业化落地中,需要内容、算法等各个方面的协同支撑,但是良好的用户体验是商业应用的第一要素,而识别算法是提升用户体验的核心因素。下文将从语音识别的算法发展路径、算法发展现状及前沿算法研究三个方面来探讨语音识别技术。
二、算法
对于语音识别系统而言,第一步要检测是否有语音输入,即,语音激活检测(VAD)。在低功耗设计中,相比于语音识别的其它部分,VAD采用always on的工作机制。当VAD检测到有语音输入之后,VAD便会唤醒后续的识别系统。主要包括特征提取、识别建模及模型训练、解码得到结果几个步骤。
首先,我们知道声音实际上是一种波。常见的mp3、wmv等格式都是压缩格式,必须转成非压缩的纯波形文件来处理,比如Windows PCM文件,也就是俗称的wav文件。wav文件里存储的除了一个文件头以外,就是声音波形的一个个点了。下图是一个波形的示例。
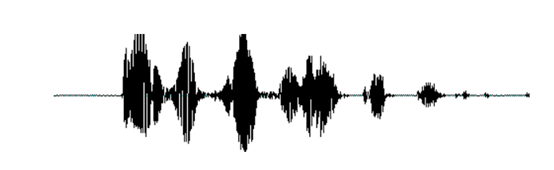
在开始语音识别之前,有时需要把首尾端的静音切除,降低对后续步骤造成的干扰。这个静音切除的操作一般称为VAD,需要用到信号处理的一些技术。要对声音进行分析,需要对声音分帧,也就是把声音切开成一小段一小段,每小段称为一帧。分帧操作一般不是简单的切开,而是使用移动窗函数来实现,这里不详述。帧与帧之间一般是有交叠的,就像下图这样:

图中,每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。我们称为以帧长25ms、帧移10ms分帧。图中,每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。我们称为以帧长25ms、帧移10ms分帧。
分帧后,语音就变成了很多小段。但波形在时域上几乎没有描述能力,因此必须将波形作变换。常见的一种变换方法是提取MFCC特征,根据人耳的生理特性,把每一帧波形变成一个多维向量,可以简单地理解为这个向量包含了这帧语音的内容信息。这个过程叫做声学特征提取。实际应用中,这一步有很多细节,声学特征也不止有MFCC这一种,具体这里不讲。
至此,声音就成了一个12行(假设声学特征是12维)、N列的一个矩阵,称之为观察序列,这里N为总帧数。观察序列如下图所示,图中,每一帧都用一个12维的向量表示,色块的颜色深浅表示向量值的大小。

接下来就要介绍怎样把这个矩阵变成文本了。首先要介绍两个概念:
- 音素:单词的发音由音素构成。对英语,一种常用的音素集是卡内基梅隆大学的一套由39个音素构成的音素集,参见The CMU Pronouncing Dictionary。汉语一般直接用全部声母和韵母作为音素集,另外汉语识别还分有调无调,不详述。
- 状态:这里理解成比音素更细致的语音单位就行啦。通常把一个音素划分成3个状态。
语音识别是怎么工作的呢?实际上一点都不神秘,无非是:
第一步,把帧识别成状态(难点);第二步,把状态组合成音素;第三步,把音素组合成单词。
如下图所示:

图中,每个小竖条代表一帧,若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词。也就是说,只要知道每帧语音对应哪个状态了,语音识别的结果也就出来了。图中,每个小竖条代表一帧,若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词。也就是说,只要知道每帧语音对应哪个状态了,语音识别的结果也就出来了。
那每帧音素对应哪个状态呢?有个容易想到的办法,看某帧对应哪个状态的概率最大,那这帧就属于哪个状态。比如下面的示意图,这帧对应S3状态的概率最大,因此就让这帧属于S3状态。

那这些用到的概率从哪里读取呢?有个叫“声学模型”的东西,里面存了一大堆参数,通过这些参数,就可以知道帧和状态对应的概率。获取这一大堆参数的方法叫做“训练”,需要使用巨大数量的语音数据,训练的方法比较繁琐,这里不讲。
但这样做有一个问题:每一帧都会得到一个状态号,最后整个语音就会得到一堆乱七八糟的状态号,相邻两帧间的状态号基本都不相同。假设语音有1000帧,每帧对应1个状态,每3个状态组合成一个音素,那么大概会组合成300个音素,但这段语音其实根本没有这么多音素。如果真这么做,得到的状态号可能根本无法组合成音素。实际上,相邻帧的状态应该大多数都是相同的才合理,因为每帧很短。
解决这个问题的常用方法就是使用隐马尔可夫模型(Hidden Markov Model,HMM)。这东西听起来好像很高深的样子,实际上用起来很简单:
第一步,构建一个状态网络。
第二步,从状态网络中寻找与声音最匹配的路径。
这样就把结果限制在预先设定的网络中,避免了刚才说到的问题,当然也带来一个局限,比如你设定的网络里只包含了“今天晴天”和“今天下雨”两个句子的状态路径,那么不管说些什么,识别出的结果必然是这两个句子中的一句。
那如果想识别任意文本呢?把这个网络搭得足够大,包含任意文本的路径就可以了。但这个网络越大,想要达到比较好的识别准确率就越难。所以要根据实际任务的需求,合理选择网络大小和结构。
搭建状态网络,是由单词级网络展开成音素网络,再展开成状态网络。语音识别过程其实就是在状态网络中搜索一条最佳路径,语音对应这条路径的概率最大,这称之为“解码”。路径搜索的算法是一种动态规划剪枝的算法,称之为Viterbi算法,用于寻找全局最优路径。

这里所说的累积概率,由三部分构成,分别是:
观察概率:每帧和每个状态对应的概率
转移概率:每个状态转移到自身或转移到下个状态的概率
语言概率:根据语言统计规律得到的概率
其中,前两种概率从声学模型中获取,最后一种概率从语言模型中获取。语言模型是使用大量的文本训练出来的,可以利用某门语言本身的统计规律来帮助提升识别正确率。语言模型很重要,如果不使用语言模型,当状态网络较大时,识别出的结果基本是一团乱麻。
三 、调研
百度语音识别技术
注册百度AI开放平台,点击左侧栏语音技术,在控制栏创建应用:百度AI平台

创建应用后记录如图三个字段信息。

1语音存储及识别
相关文件:16k.pcm (百度ai平台下载)
百度API提供两种类型的语音识别功能,故语音存储可有两种存储方式:
- 直接文件存储方式(数据库表存储文件名、类型、地址等信息)。
- 二进制存储方式。
数据库配置及创建测试表
spring.datasource.url=jdbc:mysql://localhost:3306/ass_test?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&serverTimezone=UTC
spring.datasource.username=
spring.datasource.password=
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
创建fileinfo表
CREATE TABLE `fileinfo` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`filename` varchar(50) NOT NULL COMMENT '文件名',
`filepath` varchar(50) NOT NULL COMMENT '文件路径',
`filetype` varchar(50) NOT NULL COMMENT '文件类型',
`filedata` MEDIUMBLOB COMMENT '文件DATA',
`creattime` datetime COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
Html demo.html:
<html>
<head>
<script type='text/javascript'>
function spack(){
var wrapSpk = document.getElementById('wrapSpk');
var spkAudio=document.getElementById('spkAudio');
var spkText=document.getElementById('spkText').value;
wrapSpk.removeChild(spkAudio);
var spk1='<audio id="spkAudio" autoplay="autoplay">';
var spk2='<source src="http://tts.baidu.com/text2audio?lan=zh&ie=UTF-8&spd=6&text='+spkText+'" type="audio/mpeg">';
var spk3='<embed height="0" width="0" src="">';
var spk4='</audio>';
wrapSpk.innerHTML = spk1+spk2+spk3+spk4;
var spkAudio=document.getElementById('spkAudio');
spkAudio.play();
}
function voiceToWord(){
window.location.href="http://localhost:8080/voice/voiceToWord";}
if (document.createElement("input").webkitSpeech == undefined) {
alert("很遗憾,你的浏览器不支持语音识别。");
}
else{
alert("尝试使用语言识别来输入内容吧");
}
</script>
</head>
<body>
<!--<input name="s" type="text" x-webkit-speech x-webkit-grammar="builtin:translate" />
<input x-webkit-speech lang="zh-CN" />
<input x-webkit-speech x-webkit-grammar="bUIltin:search" />
<form action="http://www.google.com/search" >
<input type="search" name="q" lang="zh-CN" x-webkit-speech x-webkit-grammar="builtin:search" onwebkitspeechchange="startSearch(event)"/>
</form>
-->
<div>
汉字转语音播放:<input type="text" id="spkText">
<input type="button" id="spkBtn" onclick="spack()" value="播放">
</div>
<div id="wrapSpk">
<audio id="spkAudio" autoplay="autoplay">
<source src="http://tts.baidu.com/text2audio?lan=zh&ie=UTF-8&spd=6&text=" type="audio/mpeg">
<embed height="0" width="0" src="">
</audio>
</div>
<div id="wrapSpk">
<form action="http://localhost:8080/voice/receiveToHost" method="post" id="iconForm" enctype="multipart/form-data">
<table">
<tr>
<td>语音文件:</td>
<td><input id="pcmFile" name="pcmFile" type="file" /></td>
<td><input type="submit" value="上传到本地"/></td>
</tr>
</table>
</form>
</div>
<div id="wrapSpk1">
<form action="http://localhost:8080/voice/receiveToBase" method="post" id="iconForm1" enctype="multipart/form-data">
<table">
<tr>
<td>语音文件:</td>
<td><input id="pcmFile1" name="pcmFile1" type="file" /></td>
<td><input type="submit" value="上传到数据库"/></td>
</tr>
</table>
</form>
</div>
<div id="wrapSpk2">
<form action="http://localhost:8080/voice/voiceToWordD" method="post" id="iconForm2" enctype="multipart/form-data">
<table">
<tr>
<td>语音文件:</td>
<td><input id="pcmFile2" name="pcmFile2" type="file" /></td>
<td><input type="submit" value="直接识别"/></td>
</tr>
</table>
</form>
</div>
<div id="wrapSpk">
文件识别:<input type="button" id = "shibie" value="语音转文字" onclick="voiceToWord()"/>
</div>
</body>
</html>
百度链接客户端:
在此之前,需要导入百度api的jar包。
Mave配置:
<dependency>
<groupId>com.baidu.aip</groupId>
<artifactId>java-sdk</artifactId>
<version>4.1.1</version>
</dependency>
<!-- jdbcTemplate -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- MySQL连接 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
客户端AipSpeechClient.java 代码示例:
public class AipSpeechClient {
//设置APPID/AK/SK
private static final String APP_ID = "";
private static final String API_KEY = "";
private static final String SECRET_KEY = "";
public static AipSpeech AIPSPEECH=null;
private static AipSpeechClient aipSpeechClient;
private AipSpeechClient(){
}
public static AipSpeechClient getInstance(){
if(aipSpeechClient==null){
AIPSPEECH=new AipSpeech(APP_ID, API_KEY, SECRET_KEY);
AIPSPEECH.setConnectionTimeoutInMillis(2000);
AIPSPEECH.setSocketTimeoutInMillis(60000);
aipSpeechClient = new AipSpeechClient();
}
return aipSpeechClient;
}
}
或者创建配置类AppConfig.java,代码如下:
@Configuration
public class AppConfig {
//设置APPID/AK/SK
private static final String APP_ID = "";
private static final String API_KEY = "";
private static final String SECRET_KEY = "";
@Bean
public AipSpeech aipSpeech() {
return new AipSpeech(APP_ID, API_KEY, SECRET_KEY);
}
}
Controller层用@Autowired注入。
Controller类VoiceReceiveController.java:
/**
* 语音识别controller
*
* @author zhangjx
* @version 1.0
* @since 2019-9-4
*/
@RestController
@RequestMapping("/voice")
public class VoiceReceiveController {
public static final String path = "E:\\testFile\\";
// public AipSpeech client = AipSpeechClient.getInstance().AIPSPEECH;
public static final String filePath = "E:\\testFile\\16k.pcm";
@Autowired
public AipSpeech aipSpeech;
@Autowired
public JdbcTemplate jdbcTemplate;
/**
* 测试demo,直接存入本地,业务环境需要创建表来存储文件名、文件类型及文件路径 此方法亦可存储其他类型文件
*
* @param pcmFile
* @param request
* @return
* @throws IOException
*/
@PostMapping(value = "/receiveToHost")
public String uploadToHost(MultipartFile pcmFile, HttpServletRequest request) throws IOException {
long startTime = System.currentTimeMillis(); //获取开始时间
MultipartHttpServletRequest multipartRequest = (MultipartHttpServletRequest) request;
MultipartFile file = multipartRequest.getFile("pcmFile");
savePic(file.getInputStream(), file.getOriginalFilename());
String sql = "insert into fileinfo (filename,filepath,filetype,filedata,creattime) values(?,?,?,?,?);";
jdbcTemplate.update(sql, file.getOriginalFilename(), path, file.getOriginalFilename().split("\\.")[1], null,
new Date());
long endTime = System.currentTimeMillis(); //获取结束时间
return "success!"+"程序运行时间:" + (endTime - startTime) + "ms";
}
/**
* 测试demo,直接存入数据库,业务环境需要创建表来存储文件名、文件类型及文件路径 此方法也可以存储其他类型文件,文件大小不宜过大。
*
* @param pcmFile
* @param request
* @return
* @throws IOException
*/
@PostMapping(value = "/receiveToBase")
public String uploadToDatabase(MultipartFile pcmFile, HttpServletRequest request) throws IOException {
long startTime = System.currentTimeMillis(); //获取开始时间
MultipartHttpServletRequest multipartRequest = (MultipartHttpServletRequest) request;
MultipartFile file = multipartRequest.getFile("pcmFile1");
String sql = "insert into fileinfo (filename,filepath,filetype,filedata,creattime) values(?,?,?,?,?);";
jdbcTemplate.update(sql, file.getOriginalFilename(), "DATABASE", file.getOriginalFilename().split("\\.")[1],
file.getInputStream(), new Date());
long endTime = System.currentTimeMillis(); //获取结束时间
return "success!"+"程序运行时间:" + (endTime - startTime) + "ms";
}
/**
* 测试demo,读取本地文件及二进制数据并识别。
*
* @param pcmFile
* @param request
* @return
* @throws IOException
*/
@GetMapping(value = "/voiceToWord")
public String voiceToWorld() throws IOException {
long startTime = System.currentTimeMillis(); //获取开始时间
// 文件读取方式,aipSpeech.asr()方法为多态方法,实际上都是调用的二进制方法,可自行查看api
JSONObject asrRes = aipSpeech.asr(filePath, "pcm", 16000, null);
long endTime = System.currentTimeMillis(); //获取结束时间
return asrRes.get("result").toString()+"程序运行时间:" + (endTime - startTime) + "ms";
}
/**
* 测试demo,上传文件直接识别。
*
* @param pcmFile
* @param request
* @return
* @throws IOException
*/
@PostMapping(value = "/voiceToWordD")
public String voiceToWorldDirect(MultipartFile pcmFile, HttpServletRequest request) throws IOException {
long startTime = System.currentTimeMillis(); //获取开始时间
MultipartHttpServletRequest multipartRequest = (MultipartHttpServletRequest) request;
MultipartFile file = multipartRequest.getFile("pcmFile2");
JSONObject asrRes = aipSpeech.asr(file.getBytes(), "pcm", 16000, null);
long endTime = System.currentTimeMillis(); //获取结束时间
return asrRes.get("result").toString()+"程序运行时间:" + (endTime - startTime) + "ms";
}
/**
* 测试demo,文件流
*
* @param inputStream
* @param fileName
*
*/
private void savePic(InputStream inputStream, String fileName) {
OutputStream os = null;
try {
byte[] bs = new byte[1024];
int len;
File tempFile = new File(path);
if (!tempFile.exists()) {
tempFile.mkdirs();
}
os = new FileOutputStream(tempFile.getPath() + File.separator + fileName);
while ((len = inputStream.read(bs)) != -1) {
os.write(bs, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
os.close();
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
测试方法:
启动springboot。
浏览器打开html。
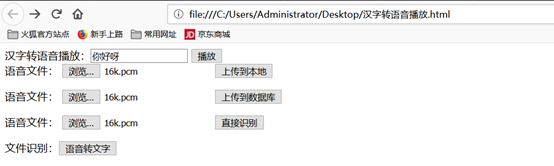
依次进行测试并查看数据库及配置的存储位置。
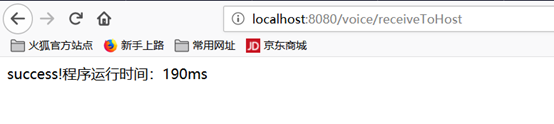
文件上传响应结果:


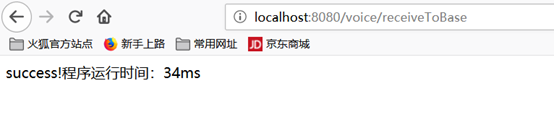
文件存入数据库响应结果:

直接识别结果:
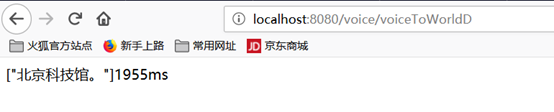
文件识别结果:

注意事项:
1、 上传需要完整的录音文件,录音文件时长不超过60s。
2、 系统默认为普通话模式,本次调用为非极速模式语音输入法。
3、 原始 PCM 的录音参数必须符合 16k 采样率、16bit 位深、单声道,支持的格式有:pcm(不压缩)、wav(不压缩,pcm编码)、amr(压缩格式)。
4、 上传文件亦适用其他类型文件上传,数据库存储方式不适合大文件存储,系统设置为16M限制。
5、 本次测试基于springboot进行,demo中的AppID、API Key、Secret Key需自行申请。
6、 错误码

7、 接口函数说明

2、资费标准
语音识别极速版价格
语音识别极速版采用分段阶梯定价方式,调用单价按照自然月累积调用量所落阶梯区间而变化。月初,上月累积的调用量清零,重新开始累积本月调用量。 每账号前50000次调用免费,免费额度用尽后开始计费,价格如下:
| 月调用量(万次) | 语音识别极速版(元/次) |
|---|---|
| 0<调用次数<=600 | 0.0042 |
| 600<调用次数<=3000 | 0.0036 |
| 3000<调用次数<=6000 | 0.0029 |
| 6000<调用次数<=15000 | 0.0019 |
| 15000<调用次数 | 0.0014 |
语音识别价格
语音识别包含输入法、搜索、粤语、英语、四川话、远场模型。可按天/月购买QPS。价格如下:
| QPS购买方式 | 单价(元) |
|---|---|
| 1QPS/天 | 80 |
| 1QPS/月 | 1400 |
| 1QPS/年 | 12000 |
说明:若原有QPS默认配额为2,则购买10QPS/月后,该月QPS提升至12。不限调用量。
免费额度
接口服务 免费调用量额度 QPS限额 计费模式
语音识别 不限制 默认2-10QPS(可通过企业认证提升) 可购买提升QPS
语音识别极速版 每账号共50000次 默认5QPS;开通付费后提升至50QPS 按调用量阶梯计费
注:成功调用与失败调用均算作一次调用,消耗免费额度。
个人创建的应用控制台,企业认证QPS值为10.
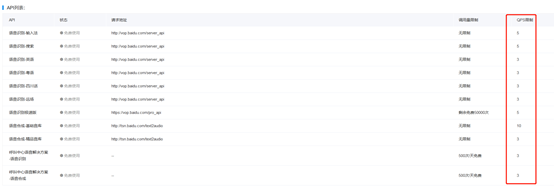
其他语音识别平台资费
科大讯飞
调用方法类似于百度api。
计费标准:

优点:
1、 支持语种多。
2、 支持长时间录音识别(5小时内)。
3、 转换精度高。
缺点:
1、 付费。
腾讯
企业认证10QPS,个人认证2QPS。
优点:
1、 免费。
2、 提供多版本语音识别技术,如语音识别-echo版,语音识别-流式版(AI Lab),语音识别-流式版(WeChat AI),流式版可做到边录编译。
缺点:
1、 echo版单次请求上限15s,只支持普通话。
2、 AI Lab及WeChat AI只支持普通话。
阿里
1. 语音数据处理费用
• 实时语音识别服务,按照处理的语音时长计费,可以自助开通后付费或购买预付费资源包。
• 一句话语音识别服务,按照调用次数计费,可以自助开通后付费或购买预付费资源包。
• 录音文件识别服务,按照录音时长计费,可以自助开通后付费或购买预付费资源包。
• 语音合成服务,按照调用次数计费,可以自助开通后付费或购买预付费资源包。
2. 附加产品费用
• 超额并发线路费用,商用客户默认提供200路并发,如果客户业务量较大超过200路的,可以自助购买额外并发线路
• 文本自学习定制模型,用于提高客户业务领域的名词句子识别率,可以自助开通
3.计费方式和报价
预付费方式

注意:预付费资源包的有效期是购买之日起1年以内
后付费方式
按天结算,量大优惠,随调用量增加梯度报价。

计费细则
试用版:
• 目前试用版不计费,您可免费试用,如有变化,请关注官网通知;
• 一句话识别、实时语音识别、语音合成在2个并发内每个自然日使用量不限;
• 录音文件识别每个自然日识别时长不超过2小时;
商用版:
• 如果您需要超过2个并发或更大量的录音文件识别接口的时长使用,请您开通商用版;
• 开通商用版之后,默认为后付费模式。购买预付费资源包之后,自动变更为预付费模式,并使用资源包内资源进行抵扣,当预付费资源包内资源使用完之后,会再次变更为后付费模式;
• 商用版(包括预付费模式和后付费模式)按每个自然日实际使用量计费,无免费额度,不使用则不产生费用,若使用则每天结算。北京时间每晚24点,系统将自动对您当天用量进行全量计算和计费,具体账单生成会有延迟;
• 计费规则:
- 按时长计费的,会累加每次调用的语音时长(按秒向下取整,如本次发送的语音长度22.8秒,则记为22秒)。
- 按照次数计费的,返回失败的调用不会计入次数。
- 计费总额按照当天24点总体用量最后达到的梯度价格进行全量计费,例如一句话识别当天达到500千次调用量,则当日扣费500*3.0元(300-999千次阶梯价格)=1500.0元。
- 语音合成的计费调用次数按照每次请求中传入的字符数(UTF-8编码,以下字符数均以此编码为准。1个汉字、英文字母、全半角标点符号均算1个有效字符)作为统计依据:100个字符以内(含100个字符)记为1次计费调用;每超过100个字符则多记1次计费调用,且1次请求最多传入300个字符。例如,102个字符记为2次计费调用,201个字符记为3次计费调用,依此类推。(2019年6月10日零点前开通预付费或后付费的商用版客户,将于2020年6月9日24点开始自动调整为新规格的计费方式。)
并发数计算
并发数指同一个账号同时在处理的请求数。
一般语音请求的处理都会延续一段时间,例如用户新建一个语音识别请求,持续发送语音数据给服务端,这时并发数就是1;在这个请求处理的同时,这个用户又新建了另一个请求,开始发送语音数据,这时服务端在处理这个账号的2个请求,并发数就变成2。
超额并发线路

优点:
1、 识别准确率高。
2、 超快的解码速率。
3、 独创的模型优化工具。
4、 广泛的领域覆盖。
缺点:
1、付费。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)