语音情绪识别和语音识别等语音处理任务的语音数据 振幅归一化方法 how to normalize the amplitude of audio with python
网上找了一圈都没有找到比较靠谱的方法, 有一篇文章提到用什么do_pcm工具, 但是全网都没有相关的内容, 这里贴上一个调用pydub.effects.normalize方法进行振幅归一化的方法. 方便后面的同学.主要思想取一段语料中幅度最大的点将其幅度拉大到接近1,记录拉大的比例,再将其他所有点均按这个比例拉伸。pydub.effects.normalize源码@regi...
·
网上找了一圈都没有找到比较靠谱的方法, 有一篇文章提到用什么do_pcm工具, 但是全网都没有相关的内容, 这里贴上一个调用pydub.effects.normalize方法进行振幅归一化的方法. 方便后面的同学.
-
主要思想
取一段语料中幅度最大的点将其幅度拉大到接近1,记录拉大的比例,再将其他所有点均按这个比例拉伸。 -
pydub.effects.normalize源码
@register_pydub_effect
def normalize(seg, headroom=0.1): # 传入一个pydub的AudioSegment对象<class 'pydub.audio_segment.AudioSegment'>
"""
headroom is how close to the maximum volume to boost the signal up to (specified in dB)
headroom是多远接近最大音量(振幅)以提升信号(以dB为单位)
"""
peak_sample_val = seg.max # 计算传入的sound的最大振幅作为 峰值样本振幅值
# if the max is 0, this audio segment is silent, and can't be normalized
# 如果最大值为0,则此音频段是静默的,无法标准化 直接返回seg就好
if peak_sample_val == 0:
return seg
target_peak = seg.max_possible_amplitude * db_to_float(-headroom) # 目标峰值 = seg的最大可能振幅 * 转化成浮点数的理论最大振幅
needed_boost = ratio_to_db(target_peak / peak_sample_val) # 用 目标峰值/峰值样本振幅值 得到 浮点形式的音频缩放比例 再用ratio_to_db方法把这个值从浮点单位转成dB单位
return seg.apply_gain(needed_boost) # 调用apply_gain对seg执行needed_boost尺度的全局增益
- python调用pydub.effects.normalize进行振幅归一化的方法
from pydub import effects
_sound = AudioSegment.from_file("./input.wav", "wav")
sound = effects.normalize(_sound)
sound.export("./output.wav", format="wav")
- 实际效果
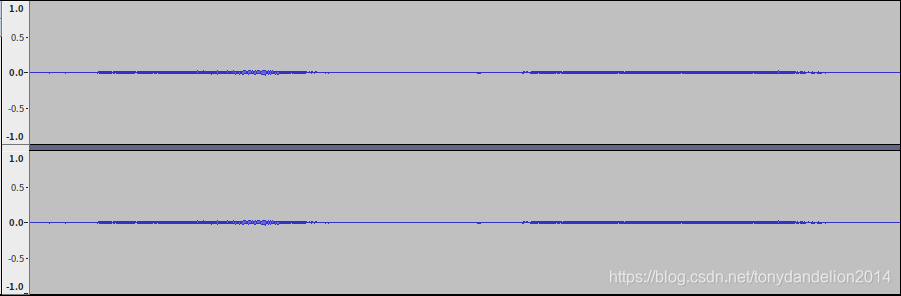
before normalized input.wav
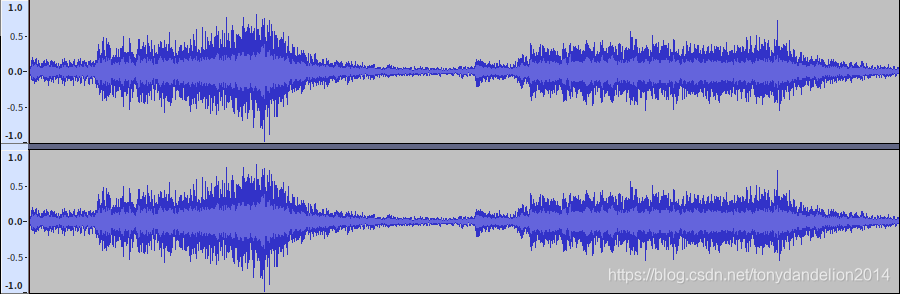
after normalized output.wav

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)