
CarbonData部署和使用
本文主要介绍了华为开源的一个新型的大数据列式存储格式CarbonData。简要描述了CarbonData的特性。有介绍了CarbonData的安装以及和Spark的集成,最后在spark-shell中通过编程执行SQL,测试了CREATE、LOAD、SELECT、INSERT、UPDATE、DELETE
Apache CarbonData | GitHub | 文档
1 概述
CarbonData是一个开源的用于快速数据分析的新型BigData文件格式,这个项目是华为公司在2016年开源的类Parquet的列式存储,也仅仅用了不到一年的时间就成为了Apache的顶级项目。
CarbonData是一种高性能数据解决方案,支持各种数据分析方案,包括BI分析,临时SQL查询,详细记录快速过滤查找,流分析等。CarbonData已经部署在许多企业生产环境中,在最大的场景之一中,它支持在具有3PB数据(超过5万亿条记录)的单个表上进行查询,响应时间少于3秒!
CarbonData文件格式是HDFS中的一个列式存储,它具有许多现代列式格式的功能,如可拆分、压缩模式、复杂数据类型等,并且CarbonData具有以下独特功能:
- 将数据与索引一起存储:它可以显着提高查询性能并减少 I/O 扫描和CPU资源(查询中有过滤器)。CarbonData索引由多级索引组成,处理框架可以利用此索引来减少调度和处理所需的任务,并且还可以在任务端扫描中以更精细的粒度单位(称为blocklet)跳过扫描而不是扫描整个文件。
- 可操作的编码数据:通过支持高效压缩和全局编码方案,可以查询压缩/编码数据,可以在将结果返回给用户之前转换数据,这是“后期实现的”。
- 支持单一数据格式的各种用例:如交互式OLAP样式查询,顺序访问(大扫描),随机访问(窄扫描)。
2 安装
2.1 要求
- 类Unix环境(Linux、Mac OS X)
- Git
- Apache Maven(推荐3.3版本或者更高)
- Java 7 或者 Java 8
- Apache Thrift 0.9.3
其它安装我这里直接跳过。可以查看下环境的thrift:thrift -version,如果没有则需要安装:
- 安装依赖
yum -y install automake libtool flex bison pkgconfig gcc-c++ boost-devel libevent-devel zlib-devel python-devel ruby-devel openssl-devel
- 安装 thrift
wget http://archive.apache.org/dist/thrift/0.9.3/thrift-0.9.3.tar.gz
tar -zxf thrift-0.9.3.tar.gz
cd thrift-0.9.3/
./configure --with-boost=/usr/local
make -j24
make install
# 验证
thrift -version
错误一:如果在编译时报如下错误:
g++: error: /usr/local/lib64/libboost_unit_test_framework.a: No such file or directory
make[5]: *** [processor_test] Error 1
make[5]: *** Waiting for unfinished jobs....
make[5]: Leaving directory `/opt/thrift-0.9.3/lib/cpp/test'
make[4]: *** [all] Error 2
make[4]: Leaving directory `/opt/thrift-0.9.3/lib/cpp/test'
make[3]: *** [all-recursive] Error 1
make[3]: Leaving directory `/opt/thrift-0.9.3/lib/cpp'
make[2]: *** [all-recursive] Error 1
make[2]: Leaving directory `/opt/thrift-0.9.3/lib'
make[1]: *** [all-recursive] Error 1
make[1]: Leaving directory `/opt/thrift-0.9.3'
make: *** [all] Error 2
出现上面的错误是因为./configure 的时候是默认编译32位的,不会在 lib64/下产生文件,可以先查找libboost_unit_test_framework.a文件,再在提示的目录下创建一个软连接。
find / -name libboost_unit_test_framework.a
# 将/usr/local/lib/libboost_unit_test_framework.a软连到lib64下
ln -s /usr/local/lib/libboost_unit_test_framework.a /usr/local/lib64/libboost_unit_test_framework.a
错误二:libboost_unit_test_framework.a找不到时,则需要手动安装boost库。然后在创建64位的软连接。
# https://www.boost.org/
wget https://dl.bintray.com/boostorg/release/1.71.0/source/boost_1_71_0.tar.gz
tar zxf boost_1_71_0.tar.gz
cd boost_1_71_0/
./bootstrap.sh
./b2 install
ln -s /usr/local/lib/libboost_unit_test_framework.a /usr/local/lib64/libboost_unit_test_framework.a
错误三:问题解决后再次make install,此时可能还会遇到如下的错误:
collect2: error: ld returned 1 exit status
make[4]: *** [processor_test] Error 1
make[4]: Leaving directory `/opt/thrift-0.9.3/lib/cpp/test'
make[3]: *** [install] Error 2
make[3]: Leaving directory `/opt/thrift-0.9.3/lib/cpp/test'
make[2]: *** [install-recursive] Error 1
make[2]: Leaving directory `/opt/thrift-0.9.3/lib/cpp'
make[1]: *** [install-recursive] Error 1
make[1]: Leaving directory `/opt/thrift-0.9.3/lib'
make: *** [install-recursive] Error 1
安装libevent,然后再次安装thrift
wget https://github.com/libevent/libevent/releases/download/release-2.0.22-stable/libevent-2.0.22-stable.tar.gz
tar -zxf libevent-2.0.22-stable.tar.gz
cd libevent-2.0.22-stable
./configure --prefix=/usr
make
sudo make install
2.2 获取CarbonData
2.2.1 下载二进制包
在CarbonData发布1.6.0之后进行编译中提示有个包缺失(carbondata-core),然后在Maven中央仓库中查找是也缺失没有这个依赖包,最新的版本显示的是 1.5.4。
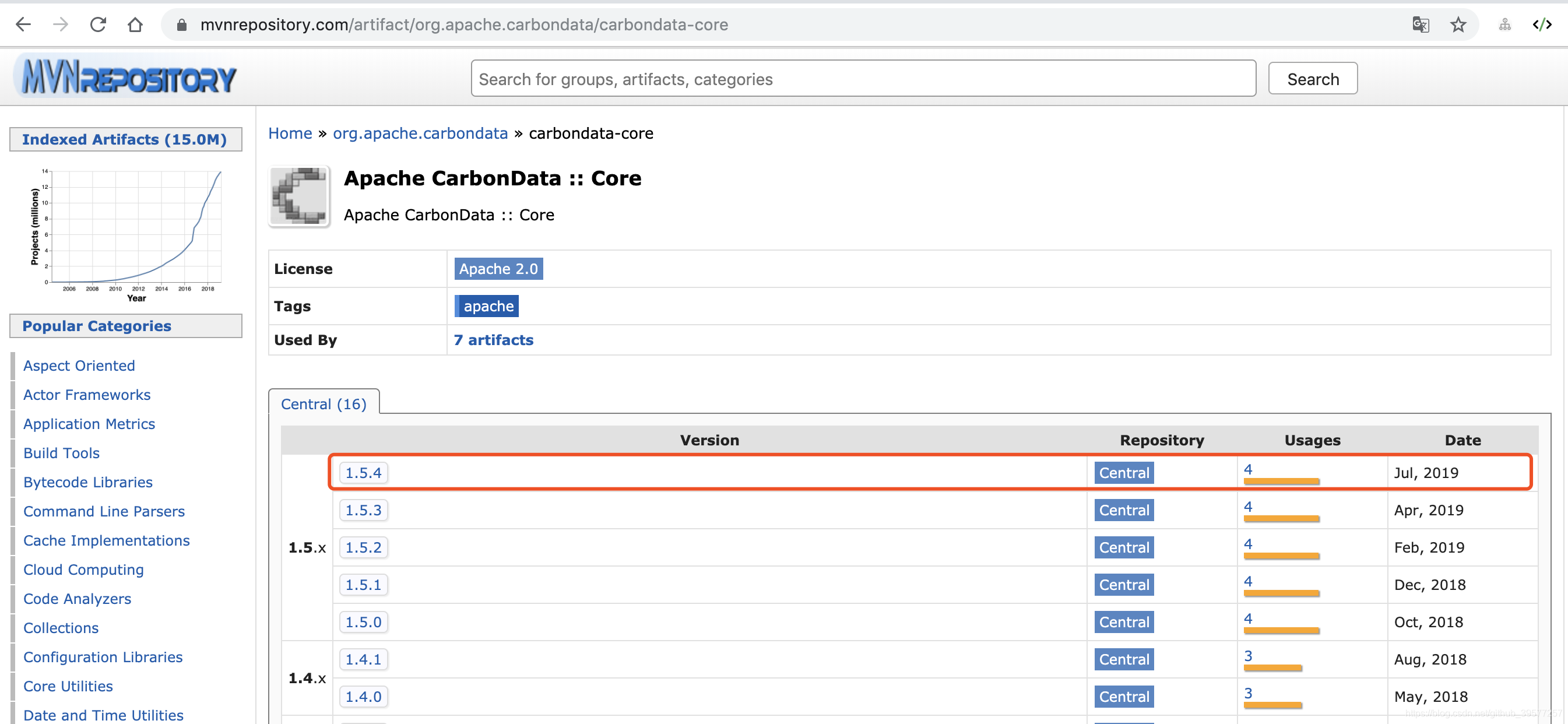
和Spark集成比较简单,官方已经提供了这个编译后的jar包,因此可以直接下载官方提供的apache-carbondata-1.6.0-bin-spark2.3.2-hadoop2.7.2.jar包:carbondata/1.6.0
因此这次直接下载官方已经打好的二进制jar包。
wget https://dist.apache.org/repos/dist/release/carbondata/1.6.0/apache-carbondata-1.6.0-bin-spark2.3.2-hadoop2.7.2.jar
2.2.2 编译方式
又过了段之间,发现Maven中央仓库终于同步上了,我们这次从头开始编译,本想着会顺利,不过依然出现了一些问题,这里也提供了我的解决方法供大家参考。
本次编译我们将源码的Hadoop版本修改为3.1.2进行编译。编译过程如下:
# 1 clone源码
# 也可以直接下载对应版本的源码包
# wget http://archive.apache.org/dist/carbondata/1.6.0/apache-carbondata-1.6.0-source-release.zip
# unzip apache-carbondata-1.6.0-source-release.zip
# cd carbondata-parent-1.6.0/
git clone https://github.com/apache/carbondata.git
cd carbondata/
# 2 选择版本。这里选择最新的CarbonData-1.6.0
git tag
git checkout tags/apache-CarbonData-1.6.0-rc3
# 3 编译。指定Spark版本为2.3.4,Hadoop版本为 3.1.2
mvn -DskipTests -Pspark-2.3 -Dspark.version=2.3.4 -Dhadoop.version=3.1.2 clean package
编译过程可能会出现如下的问题:
问题1:依赖获取失败
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal on project carbondata-hive: Could not resolve dependencies for project org.apache.carbondata:carbondata-hive:jar:1.6.0: Could not transfer artifact org.pentaho:pentaho-aggdesigner-algorithm:jar:5.1.5-jhyde from/to conjars (http://conjars.org/repo): conjars.org: Name or service not known: Unknown host conjars.org: Name or service not known -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/DependencyResolutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <goals> -rf :carbondata-hive
解决:我们直接下载依赖包,手动导入本地Maven仓库。执行如下命令。
wget https://repo.spring.io/plugins-release/org/pentaho/pentaho-aggdesigner-algorithm/5.1.5-jhyde/pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar
# 手动导入jar包到本地仓库
mvn install:install-file -DgroupId=org.pentaho -DartifactId=pentaho-aggdesigner-algorithm -Dversion=5.1.5-jhyde -Dpackaging=jar -Dfile=pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar
问题2:org.apache.htrace.fasterxml.jackson.core.type不存在
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.2:compile (default-compile) on project carbondata-processing: Compilation failure: Compilation failure:
[ERROR] /root/apache/carbondata/processing/src/main/java/org/apache/carbondata/processing/loading/parser/impl/JsonRowParser.java:[34,53] package org.apache.htrace.fasterxml.jackson.core.type does not exist
[ERROR] /root/apache/carbondata/processing/src/main/java/org/apache/carbondata/processing/loading/parser/impl/JsonRowParser.java:[35,52] package org.apache.htrace.fasterxml.jackson.databind does not exist
[ERROR] /root/apache/carbondata/processing/src/main/java/org/apache/carbondata/processing/loading/parser/impl/JsonRowParser.java:[55,5] cannot find symbol
[ERROR] symbol: class ObjectMapper
[ERROR] location: class org.apache.carbondata.processing.loading.parser.impl.JsonRowParser
[ERROR] /root/apache/carbondata/processing/src/main/java/org/apache/carbondata/processing/loading/parser/impl/JsonRowParser.java:[55,37] cannot find symbol
[ERROR] symbol: class ObjectMapper
[ERROR] location: class org.apache.carbondata.processing.loading.parser.impl.JsonRowParser
[ERROR] /root/apache/carbondata/carbondata3/processing/src/main/java/org/apache/carbondata/processing/loading/parser/impl/JsonRowParser.java:[58,50] cannot find symbol
[ERROR] symbol: class TypeReference
[ERROR] location: class org.apache.carbondata.processing.loading.parser.impl.JsonRowParser
[ERROR] -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoFailureException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <goals> -rf :carbondata-processing
分析。可以看到源码中processing模块中使用的对象不存在,通过源码分析,报错的部分引用的包来自于htrace-core依赖,而这个包又继承自hadoop-hdfs。我的的Hadoop的版本从2.7改为了3.1.2其中的htrace-core依赖
也发生了改变,因此查看这个依赖的代码,发现TypeReference的包名由org.apache.htrace.fasterxml.jackson.core.type.TypeReference改为了org.apache.htrace.shaded.fasterxml.jackson.core.type.TypeReference、
ObjectMapper的包名由import org.apache.htrace.fasterxml.jackson.databind.ObjectMapper改为了org.apache.htrace.shaded.fasterxml.jackson.databind.ObjectMapper。
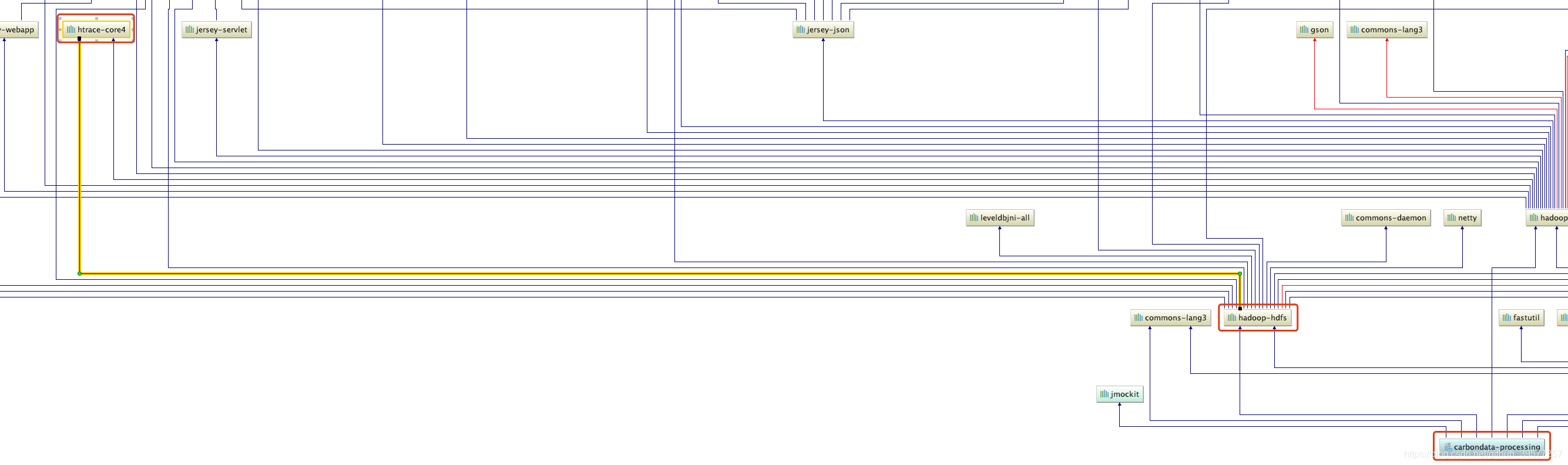
解决。 因此我们将processing/src/main/java/org/apache/carbondata/processing/loading/parser/impl/JsonRowParser.java代码中注釋掉第34、35行,导入新的包名,如下:
34 //import org.apache.htrace.fasterxml.jackson.core.type.TypeReference;
35 //import org.apache.htrace.fasterxml.jackson.databind.ObjectMapper;
36 import org.apache.htrace.shaded.fasterxml.jackson.core.type.TypeReference;
37 import org.apache.htrace.shaded.fasterxml.jackson.databind.ObjectMapper;
问题3:findbugs-maven-plugin检查项目时有一个Bug
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal org.codehaus.mojo:findbugs-maven-plugin:3.0.4:check (analyze-compile) on project carbondata-core: failed with 1 bugs and 0 errors -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <goals> -rf :carbondata-core
解决(第①步):通过IDEA工具打开源码发现项目中maven-duplicate-finder-plugin的版本无法识别,所以进行如下修改,将报错的如下四个模块的pom文件中的此插件添加上版本信息
examples/spark2/pom.xml第204行datamap/mv/core/pom.xml第132行datamap/mv/plan/pom.xml第126行integration/presto/pom.xml第637行
<plugin>
<groupId>com.ning.maven.plugins</groupId>
<artifactId>maven-duplicate-finder-plugin</artifactId>
<!-- 这里添加上版本,1.0.9 -->
<version>1.0.9</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
解决(第②步):因为我们修改了Spark和Hadoop的版本,这里就不进行严格的分析工作,因此设置分析工作的等级。
修改父级pom文件,大概在390多行,添加如下设置。
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>findbugs-maven-plugin</artifactId>
<version>3.0.4</version>
<configuration>
<!-- 设置分析工作的等级,可以为Min、Default和Max -->
<effort>Low</effort>
<!-- Low、Medium和High (Low最严格) -->
<threshold>High</threshold>
<excludeFilterFile>${dev.path}/findbugs-exclude.xml</excludeFilterFile>
<failOnError>true</failOnError>
<findbugsXmlOutput>true</findbugsXmlOutput>
<xmlOutput>true</xmlOutput>
<effort>Max</effort>
</configuration>
<executions>
<execution>
<id>analyze-compile</id>
<phase>compile</phase>
<goals>
<goal>check</goal>
</goals>
</execution>
</executions>
</plugin>
编译成功。上面的问题解决后,再次编译,编译成功后显示如下信息:
[INFO] Reactor Summary for Apache CarbonData :: Parent 1.6.0:
[INFO]
[INFO] Apache CarbonData :: Parent ........................ SUCCESS [ 2.343 s]
[INFO] Apache CarbonData :: Common ........................ SUCCESS [ 8.144 s]
[INFO] Apache CarbonData :: Core .......................... SUCCESS [ 35.548 s]
[INFO] Apache CarbonData :: Processing .................... SUCCESS [ 16.732 s]
[INFO] Apache CarbonData :: Hadoop ........................ SUCCESS [ 8.838 s]
[INFO] Apache CarbonData :: Hive .......................... SUCCESS [ 36.953 s]
[INFO] Apache CarbonData :: Streaming ..................... SUCCESS [ 20.272 s]
[INFO] Apache CarbonData :: Store SDK ..................... SUCCESS [01:11 min]
[INFO] Apache CarbonData :: Spark Datasource .............. SUCCESS [ 41.440 s]
[INFO] Apache CarbonData :: Spark Common .................. SUCCESS [01:05 min]
[INFO] Apache CarbonData :: CLI ........................... SUCCESS [ 33.643 s]
[INFO] Apache CarbonData :: Lucene Index DataMap .......... SUCCESS [ 9.463 s]
[INFO] Apache CarbonData :: Bloom Index DataMap ........... SUCCESS [ 7.759 s]
[INFO] Apache CarbonData :: Spark2 ........................ SUCCESS [01:46 min]
[INFO] Apache CarbonData :: Spark Common Test ............. SUCCESS [ 57.039 s]
[INFO] Apache CarbonData :: DataMap Examples .............. SUCCESS [ 2.454 s]
[INFO] Apache CarbonData :: Materialized View Plan ........ SUCCESS [ 40.615 s]
[INFO] Apache CarbonData :: Materialized View Core ........ SUCCESS [ 40.122 s]
[INFO] Apache CarbonData :: Assembly ...................... SUCCESS [ 31.297 s]
[INFO] Apache CarbonData :: Examples ...................... SUCCESS [ 30.754 s]
[INFO] Apache CarbonData :: presto ........................ SUCCESS [ 44.017 s]
[INFO] Apache CarbonData :: Flink Examples ................ SUCCESS [ 3.032 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 11:54 min
[INFO] Finished at: 2019-09-15T10:19:59+08:00
[INFO] ------------------------------------------------------------------------
2.3 和Spark集成
下载安装Spark 2.3.2,最好下载带Hadoop的tgz包。可以Standalone模式搭建。安装部分可以参考官网文档Spark Standalone Mode
-
将上一步下载获得的
apache-carbondata-1.6.0-bin-spark2.3.2-hadoop2.7.2.jar放置到$SPARK_HOME/carbonlib(carbonlib文件夹需要手动创建)下。 -
在Spark类路径中添加carbonlib文件夹路径
# $SPARK_HOME/conf/spark-env.sh,配置或添加
SPARK_CLASSPATH=$SPARK_HOME/carbonlib/*
-
复制GitHub对应版本的配置文件carbon.properties.template 到文件
$SPARK_HOME/conf/夹并将文件重命名为carbon.properties。 -
将上面几步添加的包和配置文件同样的方式复制到Spark其它节点上
-
在Spark节点master节点中,配置
$SPARK_HOME/conf/spark-defaults.conf文件中下表中提到的属性
#CarbonData配置项
## 要传递给驱动程序的一串额外JVM选项。例如,GC设置或其他日志记录。
spark.driver.extraJavaOptions -Dcarbon.properties.filepath=$SPARK_HOME/conf/carbon.properties
## 要传递给执行程序的一串额外JVM选项。例如,GC设置或其他日志记录。注意:您可以输入以空格分隔的多个值。
spark.executor.extraJavaOptions -Dcarbon.properties.filepath=$SPARK_HOME/conf/carbon.properties
- 在
$SPARK_HOME/conf/carbon.properties文件中添加以下属性:
carbon.storelocation=hdfs://cdh6:8020/app/CarbonStore
2.4 先决条件
- 安装并运行Hadoop HDFS和YARN
- 运行Spark
- CarbonData用户有权限访问HDFS
2.5 准备数据
$SPARK_HOME的文件结构如下(carbonlib为自己创建的)
[root@cdh6 spark-2.3.2-bin-hadoop2.7]# tree -C -L 1 ./
./
├── bin
├── carbonlib
├── conf
├── data
├── examples
├── jars
├── kubernetes
├── LICENSE
├── licenses
├── logs
├── NOTICE
├── pids
├── python
├── R
├── README.md
├── RELEASE
├── sample.csv
├── sbin
├── work
└── yarn
15 directories, 5 files
在上面的目录下写入数据到 sample.csv:
# 例如在$SPARK_HOME(/opt/spark-2.3.2-bin-hadoop2.7)下
cat > sample.csv << EOF
id,name,city,age
1,david,shenzhen,31
2,eason,shenzhen,27
3,jarry,wuhan,35
EOF
然后将数据上传到HDFS的/home/carbondata/下
hadoop fs -mkdir -p /home/carbondata
hadoop fs -put sample.csv /home/carbondata/
3 使用
重启Spark,然后执行:
$SPARK_HOME/bin/spark-shell \
--master spark://cdh6:7077 \
--total-executor-cores 2 \
--executor-memory 2G \
--jars file:///$SPARK_HOME/carbonlib/apache-carbondata-1.6.0-bin-spark2.3.2-hadoop2.7.2.jar
在spark-shell中执行:
# 1 导入如下包
scala> import org.apache.spark.sql.SparkSession
scala> import org.apache.spark.sql.CarbonSession._
# 2 创建 CarbonSession
scala> val carbon = SparkSession.builder().config(sc.getConf).getOrCreateCarbonSession("hdfs://cdh6:8020/carbon/data/store")
# 3 创建表。这一步会在上面getOrCreateCarbonSession指定HDFS路径/carbon/data/store创建出来
# 注意这里STORED AS carbondata,存储格式使用 carbondata
scala> carbon.sql(
s"""
| CREATE TABLE IF NOT EXISTS test_table(
| id string,
| name string,
| city string,
| age Int)
| STORED AS carbondata
""".stripMargin)
# 4 查看表。不仅可以看到我们刚创建出来的表test_table,还可以看到Hive表依然可以查看到
scala> carbon.sql("SHOW TABLES").show()
+--------+----------+-----------+
|database| tableName|isTemporary|
+--------+----------+-----------+
| default| movie| false|
| default| person| false|
| default|test_table| false|
+--------+----------+-----------+
# 5 加载数据
scala> carbon.sql("LOAD DATA INPATH '/home/carbondata/sample.csv' INTO TABLE test_table")
# 6 查询表数据
scala> carbon.sql("SELECT * FROM test_table").show()
+---+-----+--------+---+
| id| name| city|age|
+---+-----+--------+---+
| 1|david|shenzhen| 31|
| 2|eason|shenzhen| 27|
| 3|jarry| wuhan| 35|
+---+-----+--------+---+
# 7 统计相同城市的平均年龄
scala> carbon.sql(
s"""
| SELECT city, avg(age), sum(age)
| FROM test_table
| GROUP BY city
""".stripMargin).show()
+--------+--------+--------+
| city|avg(age)|sum(age)|
+--------+--------+--------+
| wuhan| 35.0| 35|
|shenzhen| 29.0| 58|
+--------+--------+--------+
# 8 插入一条数据。show()是一个执行算子,仅用作执行这个sql(一个Job)
scala> carbon.sql(
s"""
| INSERT INTO test_table VALUES("4", "Yore", "BeiJin", 20)
""".stripMargin).show()
## 再次查询数据,可以看到数据已经插入到表中。
scala> carbon.sql("SELECT * FROM test_table").show()
+---+-------+--------+---+
| id| name| city|age|
+---+-------+--------+---+
| 1| david|shenzhen| 31|
| 2| eason|shenzhen| 27|
| 3| jarry| wuhan| 35|
| 4| Yore| BeiJin| 20|
+---+-------+--------+---+
# 9 修改一条数据
scala> carbon.sql(
s"""
| UPDATE test_table SET (age)=(18) WHERE id='4'
""".stripMargin).show()
## 再次查询数据,可以看id为4的年龄已经更改为18岁啦。
scala> carbon.sql("SELECT * FROM test_table").show()
+---+-------+--------+---+
| id| name| city|age|
+---+-------+--------+---+
| 1| david|shenzhen| 31|
| 2| eason|shenzhen| 27|
| 3| jarry| wuhan| 35|
| 4| Yore| BeiJin| 18|
+---+-------+--------+---+
# 删除一条数据
scala> carbon.sql(
s"""
| DELETE FROM test_table WHERE id='2'
""".stripMargin).show()
## 再次查询数据,可以看id为1的那条数据已经被删除。
scala> carbon.sql("SELECT * FROM test_table").show()
+---+-------+--------+---+
| id| name| city|age|
+---+-------+--------+---+
| 2| eason|shenzhen| 27|
| 3| jarry| wuhan| 35|
| 4| Yore| BeiJin| 18|
+---+-------+--------+---+
推荐一个官方文档的一个PDF资料:CarbonData Spark Integration And Carbon Query Flow

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)