细粒度分析--RACNN
论文:https://ieeexplore.ieee.org/document/8099959代码:https://github.com/11-626/RA-CNNCVPR2017的Oral文章。概述:在multiple scales上,以类似cascade network的形式使得网络相互增强学习,进行基于region 的特征表达。横向:传统vgg分类网络,用来classificati...
论文:https://ieeexplore.ieee.org/document/8099959
代码:https://github.com/11-626/RA-CNN
CVPR2017的Oral文章。
概述:在multiple scales上,以类似cascade network的形式使得网络相互增强学习,进行基于region 的特征表达。

横向:传统vgg分类网络,用来classification;纵向:APN,用来获取attention map,本质为两层全连接层。
Multi-task formulation:
(1)分类
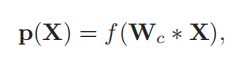
f(.)表示将卷积特征映射到可以与类别条目匹配的特征向量,通过fc层+softmax层实现,得到fine-grained categories概率。
(2)区域检测
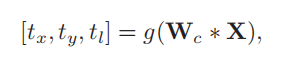
用来预测得到attention region 的box信息。g(.)表示两层堆叠的全连接层。tx, ty denotes the square’s center coordinates in terms of x and y axis, respectively, and tl denotes the half of the square’s side length.
作者代码中,第一层全连接将W* X特征转化成1* 1 * 1024的向量,第二层的全连接,Channel=3,用来输出[tx,ty,tl]。
Attention localization and amplifification:
得到attention region 的box信息之后,接着就要根据这行信息在原图中进一步处理,用来得到下一层网络训练的数据集。
① 获取Attention region 信息tx,ty,tl,其中tl为Attention region 长宽的一半,如下图所示:

(为什么tl为Attention region 长宽的一半,就是为了方便用tx,ty,tl这三个Attention region的信息表示Attention region左上角和右下角的位置坐标)
② 获取 Attention Mask.
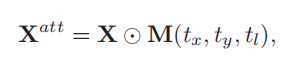
X表示原图;中间操作表示逐元素相乘;M(.)表示
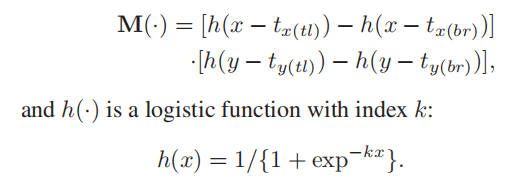
所以

所以当K is large enough时,在位于Attention region内部的像素,x-tx(tl)正数,x-tx(br)为负数,y-ty(tl)正数,y-ty(br)负数,则M(.)近似1* 1;而在Attention region外部的像素,近似0*0,所以M(.)与原图逐元素相乘得到 Attention Mask.,其实就是相当于在原图中截取Attention region ROI。
获得 Attention Mask 之后,对 Attention Mask进行双线性插值,使得 Attention Mask的大小与原图大小一样,这样便得到下一层网络的输入。
LOSS部分:

同理,第二个loss中的2表示有2与之并列的网络。
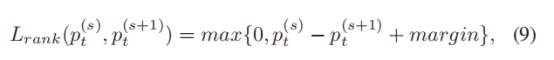
代码中,margin为一个0.05的常量。
rank_loss = (pred[i]-pred[i+1] + 0.05).clamp(min = 0);
第一个Lcls,为 Multi-task formulation中分类中的loss,使用的是普通的交叉熵损失函数,第二个Lrank损失函数,表示Lcls预测结果的正确预测的概率。根据Lrank公式可知,当后一层网络的准确率逐渐大于前一层网络准确率时,Lrank会越来越收敛。说明,在Fine-grained 问题中,局部 attention map 训练的准确率要高于整图训练的准确率。
思考:如果使用多个局部 attention map 代替原图训练,是不是会提高准确率?

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)