




- @yeyiboy
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
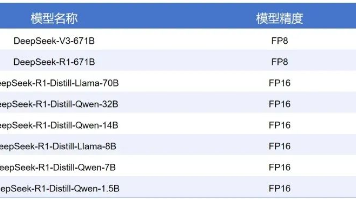
例如,图像分类任务中INT4量化可能使Top-1准确率从92%降至85%,虽然大模型的量化技术通过存储压缩与计算加速解决了部署资源瓶颈,但未来需要在精度-效率权衡、硬件适配性及算法复杂度间寻求最优解。大模型精度不同和计算和存储成本有关,精度越高肯定更准确,但是也会带来更高的计算和存储消耗。3、 提升通信与计算效率:分布式训练中,通过量化梯度减少通信带宽需求,加速多机训练过
一、问题描述:HDP3.0 集成了hive 3.0和 spark 2.3,然而spark却读取不了hive表的数据内容,准确来说是内表的数据。二、原因:hive 3.0之后默认开启ACID功能,而且新建的表默认是ACID表。而spark目前还不支持hive的ACID功能,因此无法读取ACID表的数据.三、解决办法:修改以下参数让新建的表默认不是acid表。h...
一、至少准备四个节点192.168.0.100m1192.168.0.101m2192.168.0.102m3192.168.0.103m4二、部署(在m1机器上进行目录的创建)1、创建相关目录mkdir -p /usr/local/minio/{bin,etc,data1,data2}2、下载minio文件wget https://dl.min.io/server/minio/release/l

SuperSet连接mysql设置
例如,图像分类任务中INT4量化可能使Top-1准确率从92%降至85%,虽然大模型的量化技术通过存储压缩与计算加速解决了部署资源瓶颈,但未来需要在精度-效率权衡、硬件适配性及算法复杂度间寻求最优解。大模型精度不同和计算和存储成本有关,精度越高肯定更准确,但是也会带来更高的计算和存储消耗。3、 提升通信与计算效率:分布式训练中,通过量化梯度减少通信带宽需求,加速多机训练过
例如,图像分类任务中INT4量化可能使Top-1准确率从92%降至85%,虽然大模型的量化技术通过存储压缩与计算加速解决了部署资源瓶颈,但未来需要在精度-效率权衡、硬件适配性及算法复杂度间寻求最优解。大模型精度不同和计算和存储成本有关,精度越高肯定更准确,但是也会带来更高的计算和存储消耗。3、 提升通信与计算效率:分布式训练中,通过量化梯度减少通信带宽需求,加速多机训练过
例如,图像分类任务中INT4量化可能使Top-1准确率从92%降至85%,虽然大模型的量化技术通过存储压缩与计算加速解决了部署资源瓶颈,但未来需要在精度-效率权衡、硬件适配性及算法复杂度间寻求最优解。大模型精度不同和计算和存储成本有关,精度越高肯定更准确,但是也会带来更高的计算和存储消耗。3、 提升通信与计算效率:分布式训练中,通过量化梯度减少通信带宽需求,加速多机训练过