




- @qq_40910191
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文主要是对视觉定位方面的一些文章
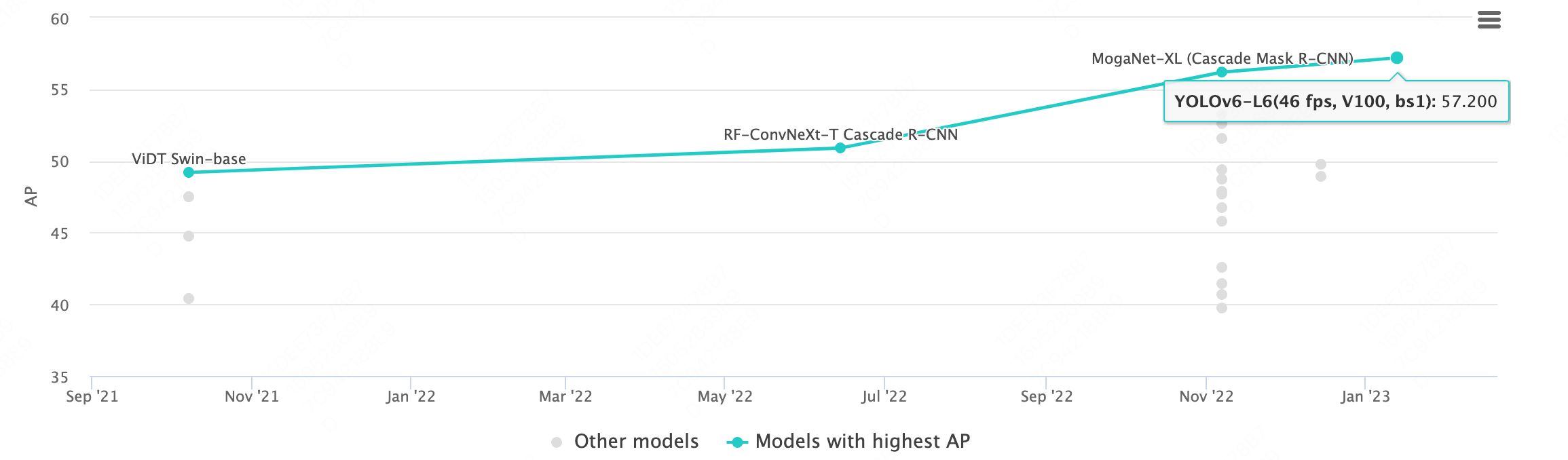
本文主要是对视觉定位方面的一些文章
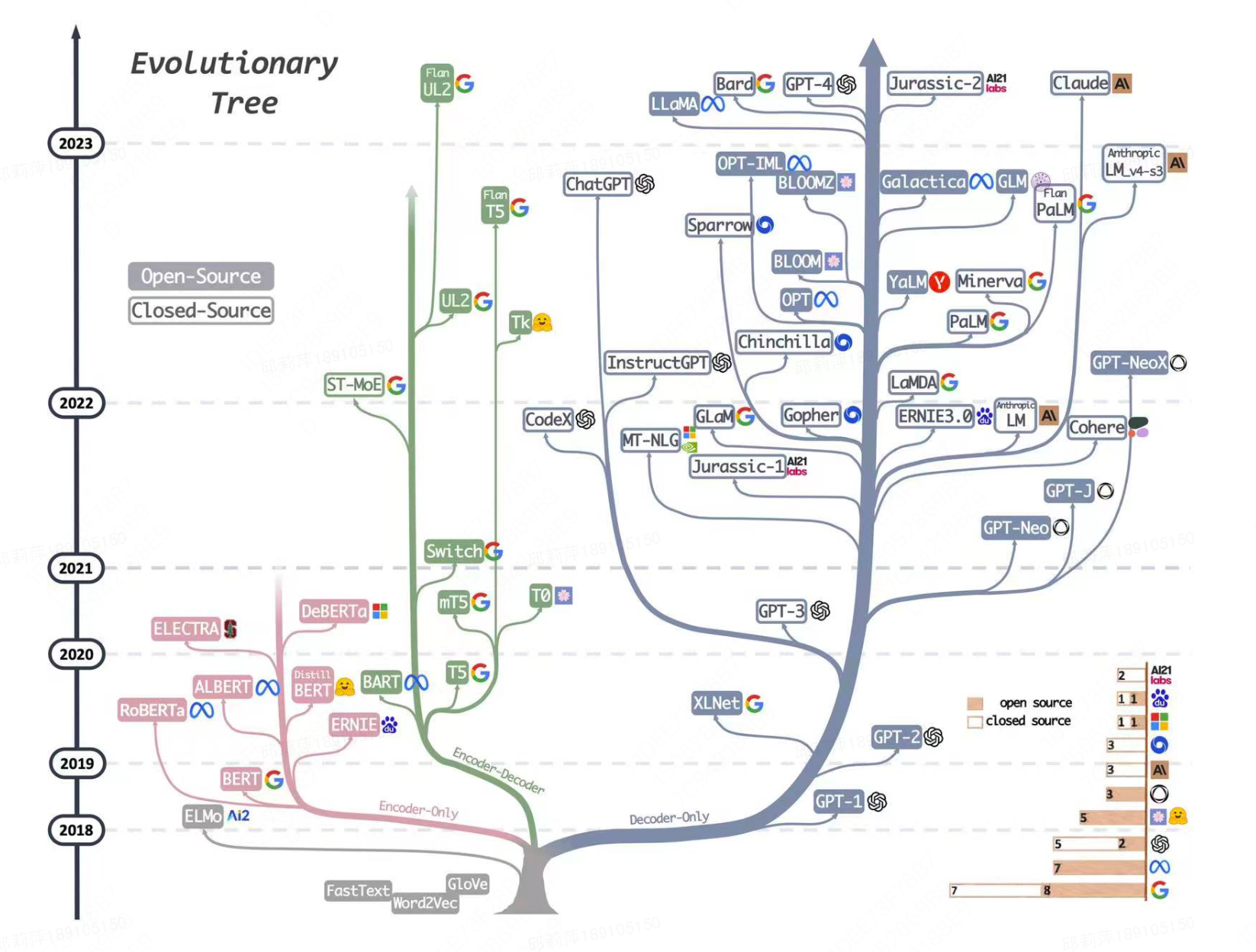
两年来基于LLM做vision-lanuage任务的一些工作,并将其划分为4个类别:冻住LLM,训练视觉编码器等额外结构以适配LLM,例如mPLUG-Owl,LLaVA,Mini-GPT4,Frozen,BLIP2,Flamingo,PaLM-E[1]将视觉转化为文本,作为LLM的输入,例如PICA(2022),PromptCap(2022)[2],ScienceQA(2022)[3]利用视觉模态
对于低资源微调大模型的共同点都是冻结大模型参数,通过小模块来学习微调产生的低秩改变。但目前存在的一些问题就是很容易参数灾难性遗忘,因为模型在微调的时候整个模型层参数未改变,而少参数的学习模块微调时却是改变量巨大,容易给模型在推理时产生较大偏置,使得以前的回答能力被可学习模块带偏,在微调的时候也必须注意可学习模块不能过于拟合微调数据,否则会丧失原本的预训练知识能力,产生灾难性遗忘。
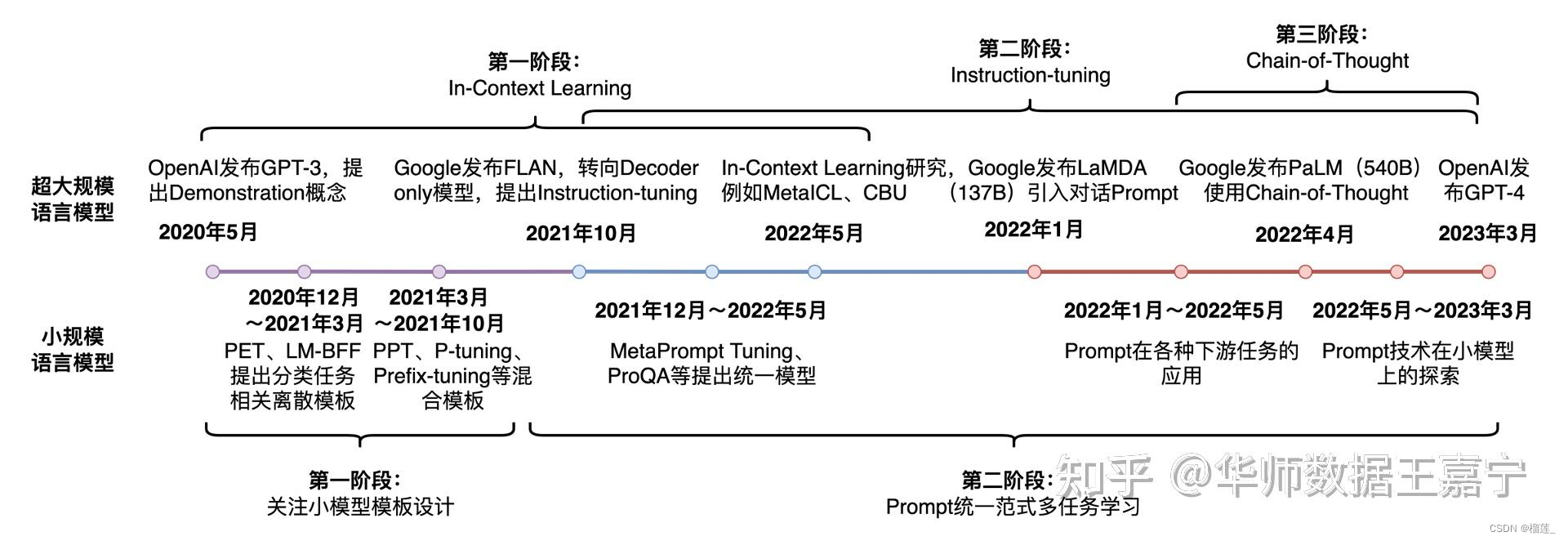
Diffusion Model (扩散模型) 是一类生成模型, 和 VAE (Variational Autoencoder, 变分自动编码器), GAN (Generative Adversarial Network, 生成对抗网络) 等生成网络不同的是, 扩散模型在前向阶段对图像逐步施加噪声, 直至图像被破坏变成完全的高斯噪声, 然后在逆向阶段学习从高斯噪声还原为原始图像的过程.

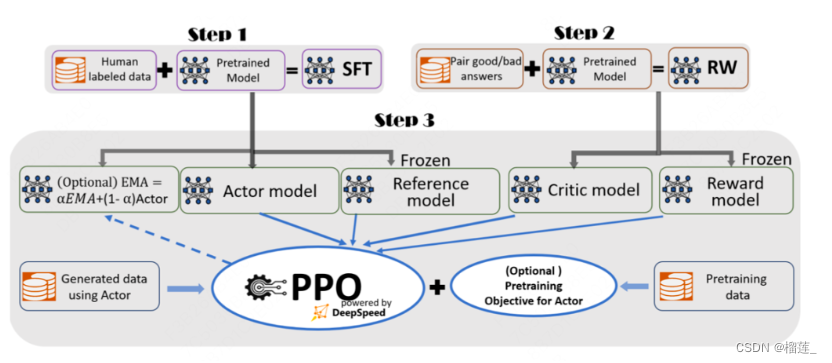
应用场景是什么?众所周知,整个 RLHF (基于人类反馈的强化学习) 分为这么三步:SFT (Supervised Fine-Tuning): 有监督的微调,使用正常的 instruction following 或者对话的样本,来训练模型的基础对话、听从 prompt 的能力;RM (Reward Modeling): 基于人类的偏好和标注,来训练一个能模拟人偏好的打分模型;
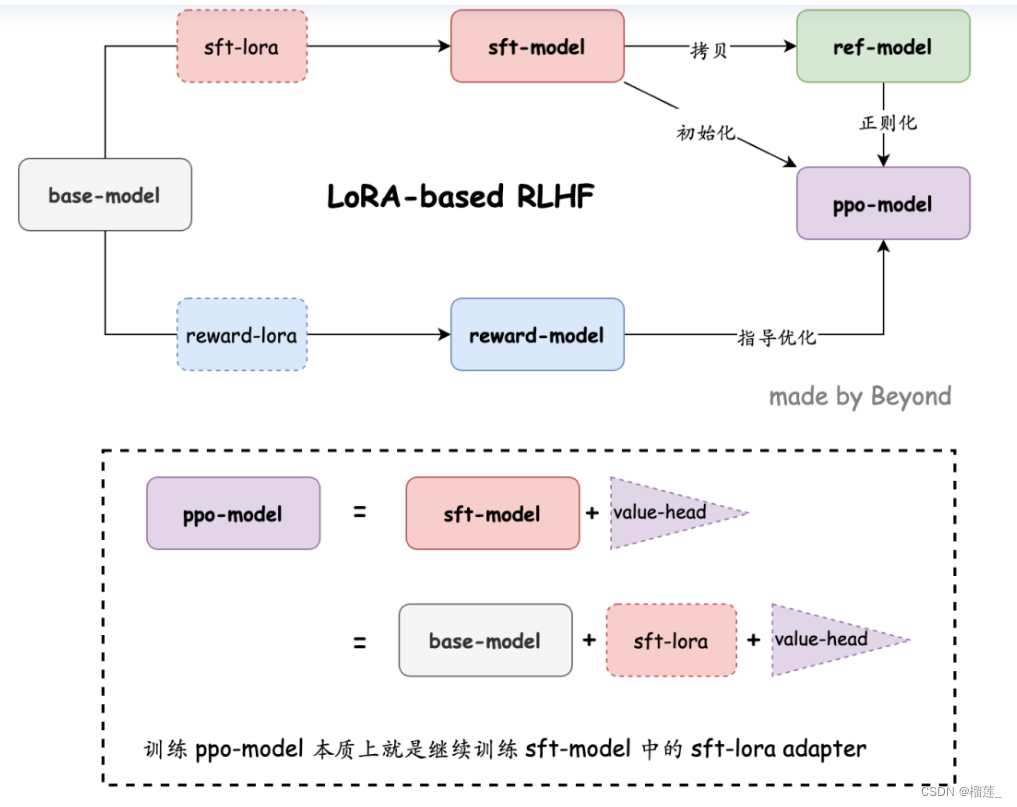
对于低资源微调大模型的共同点都是冻结大模型参数,通过小模块来学习微调产生的低秩改变。但目前存在的一些问题就是很容易参数灾难性遗忘,因为模型在微调的时候整个模型层参数未改变,而少参数的学习模块微调时却是改变量巨大,容易给模型在推理时产生较大偏置,使得以前的回答能力被可学习模块带偏,在微调的时候也必须注意可学习模块不能过于拟合微调数据,否则会丧失原本的预训练知识能力,产生灾难性遗忘。
