




- @qq_38641985
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
孪生神经网络定义孪生神经网络(Siamese network)就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的。当我们想要提取同一属性的特征的时候,如果使用两个神经网络分别对图片进行特征提取,提取到的特征很有可能不在一个分布域中,此时我们可以考虑使用一个神经网络进行特征提取再进行比较。因此,孪生神经网络可以提取出两个输入图片同一分布域的特征,此时便可以判断两个输入图片的相似性。狭义
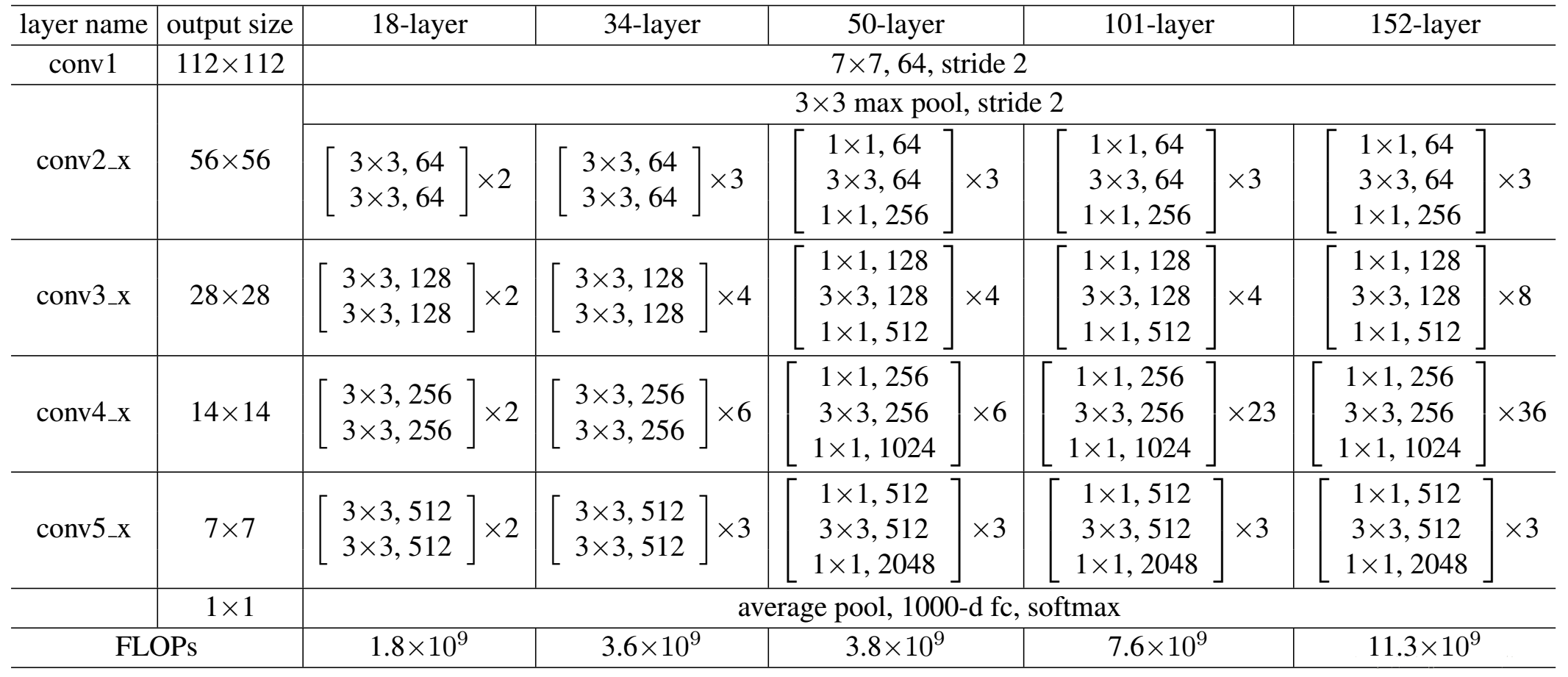
自从ResNet在2015年被提出,在ImageNet比赛classification任务上获得第一名,因为它“简单与实用”并存,之后很多方法都建立在ResNet50或者ResNet101的基础上完成的,检测,分割,识别等领域都纷纷使用ResNet,Alpha zero也使用了ResNet,所以可见ResNet确实很好用。Resnets50 网络结构示意图ResNet50和ResNet101对比.
import speech_recognition as srfile ="test.wav"r= sr.Recognizer()with sr.AudioFile(file) as src:audio = r.record(src)print("音声データの文字をお越し結果:", r.recognize_google(audio,language="ja"))speech_recognition
英语转语音from gtts import gTTSdef get_english_audio(text):tts = gTTS(text)return ttstext="This is a cat!"data = get_english_audio(text)data.save("eg.mp3")汉语转语音from gtts import gTTSdef get_chinese_audio(te
直接读取图片def display_img(file="p.jpeg"):img = cv.imread(file)print (img.shape)cv.imshow('image',img)cv.waitKey(0)cv.destroyAllWindows()读取灰度图片def display_gray_img(file="p.jpeg"):img = cv.imread(file,cv.IM
第一部下载对应源码: https://github.com/tensorflow/models建立工程目录复制models-master\research\object_detection到工程之中下载模型下载对应模型:https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1_detec
数据集:http://host.robots.ox.ac.uk:8080/pascal/VOC/voc2011/index.html说明:本文使用2012工程目录datasets|_____commodity______Annotations||__________JPEGImages数据预处理from xml.etree import ElementTree as ETfrom collecti
https://blog.csdn.net/dongd_70/article/details/82690927
数据集:http://host.robots.ox.ac.uk:8080/pascal/VOC/voc2011/index.html说明:本文使用2012工程目录datasets|_____commodity______Annotations||__________JPEGImages数据预处理from xml.etree import ElementTree as ETfrom collecti
第一部下载对应源码: https://github.com/tensorflow/models建立工程目录复制models-master\research\object_detection到工程之中下载模型下载对应模型:https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1_detec