




- @qq_17040587
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
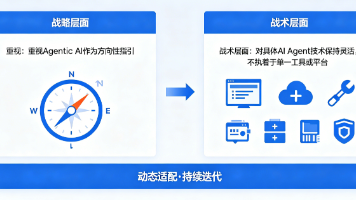
AI Agent≠Agentic AI ,企业用不好的核心根源别盲目采购 AI Agent ,企业真正缺的是 Agentic AI 战略一本书讲透 Agentic AI,从认知误区到企业落地有一个问题被问过无数次:既然 AI Agent 已经这么成熟了,企业为什么还是用不好?这个问题背后,实则有一个更深的问题没有被问出来:企业买的AI Agent,和他们真正需要的Agentic AI,不是同一件事
京东自营京东旗舰店。

AI Agent≠Agentic AI ,企业用不好的核心根源别盲目采购 AI Agent ,企业真正缺的是 Agentic AI 战略一本书讲透 Agentic AI,从认知误区到企业落地有一个问题被问过无数次:既然 AI Agent 已经这么成熟了,企业为什么还是用不好?这个问题背后,实则有一个更深的问题没有被问出来:企业买的AI Agent,和他们真正需要的Agentic AI,不是同一件事
前段时间准备登录一台很久没用过的测试服务器,结果连续输了三次密码都提示错误。这几年注册的账号越来越多,邮箱、NAS、云服务器、GitHub、Docker Hub、各种AI平台和开发工具,少说也有上百个。为了方便,有时候会让浏览器自动保存;为了保险,又会额外记在备忘录里。时间久了,密码倒是没丢,管理密码的方法却越来越混乱。更麻烦的是,很多重要账号其实关联着自己的数字资产。服务器密码丢了可以重置,但如

前段时间准备登录一台很久没用过的测试服务器,结果连续输了三次密码都提示错误。这几年注册的账号越来越多,邮箱、NAS、云服务器、GitHub、Docker Hub、各种AI平台和开发工具,少说也有上百个。为了方便,有时候会让浏览器自动保存;为了保险,又会额外记在备忘录里。时间久了,密码倒是没丢,管理密码的方法却越来越混乱。更麻烦的是,很多重要账号其实关联着自己的数字资产。服务器密码丢了可以重置,但如
服务器维护这件事,最让人难受的不是它挂了,而是不知道它挂了——等你从用户投诉里发现的时候,问题已经持续一两个小时了。这种情况出现几次之后,我就开始认真考虑搭一套监控告警系统。Prometheus + Node_Exporter + Alertmanager 这套组合在运维圈子里用得很多,核心原理也不复杂:Node_Exporter 负责把服务器 CPU、内存、磁盘这些指标暴露出来,Promethe

systemd-timesyncd:Linux 系统内置轻量 SNTP 时间同步服务,timedatectl set-ntp true实际就是启用该服务做网络校时。重启系统时间同步服务,立刻重新连接 NTP 服务器、强制马上校准系统时间。这里 把NTP前的注释符号#去掉 并且,NTP=标准服务区的IP。以管理员权限,开启 Linux 系统的自动网络时间同步功能。这是 Linux 系统中用于自动同步

服务器多了之后,有一个很现实的问题:Prometheus 搭好了,但机器上没有 Exporter,指标采不到,监控就形同虚设。手动 SSH 逐台安装效率太低;写脚本批量跑,又没有回滚机制,环境差异还会导致各种奇怪的问题。Ansible 解决的是这件事本身:写一个 Playbook,定义好下载、解压、建用户、配 systemd 服务这些步骤,在被控机上幂等执行。同一套 Playbook,在十台机器上

朱少民同济大学特聘教授、CCF杰出会员,曾任思科(中国)软件有限公司QA资深总监、多个IEEE 国际学术会议程序委员、《软件学报》《计算机学报》等审稿人。近三十年来一直从事软件测试、质量管理和软件工程等工作,先后获得多项省、部级科技进步奖,出版了二十多部著作和4本译作,代表作有《软件工程3.0》《全程软件测试》《软件测试方法和技术》《软件项目管理》等邢颖北京邮电大学教授、博士生导师,CCF高级会员
cpolar是一款安全高效的内网穿透工具,无需公网IP或复杂配置,只需一条命令,即可将本地服务器、Web服务或任意端口映射到公网,让你随时随地远程访问内网应用,特别适合开发调试、远程运维和应急部署等场景。PostgreSQL流复制的价值在于用相对低的成本解决了数据高可用的基础问题,一主一从或者一主多从的架构能满足大多数中小业务的容灾需求。但有几个前提需要认清:异步复制在极端情况下可能丢数据,对数据
