
写文章




- @m0_71983290
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
MountainCarContinuous-v0,基于DDPG,pytorch,200轮收敛
3、第三种奖励值设置方法还是基于state[1]的,只不过把思路稍微转换一下,即reward=abs(state[1])-2,因为时间拖的越久,total_reward肯定越低,这样的话他在第一次抵达终点之后,会愿意更多的去终点,解决了第二种方法的缺陷。2、第二种奖励值设置方法是基于state[1]的,也就是reward=abs(state[1]),表示速度越大,给予越大的奖励值,前期效果还行,但
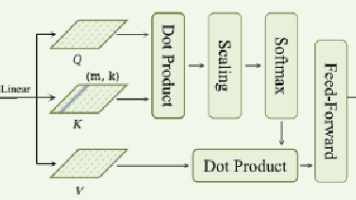
eeg conformer复现(eeg+自注意力)
这是一个端到端的eeg模型,在谷歌学术中获得了四百多的引用,实际上可以使用在eeg的任何任务中,包括但不限于运动想象,情感分类等,他的代码逻辑还算是比较清晰和简洁的,复现难度较低。
到底了