




- @flyingnosky
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
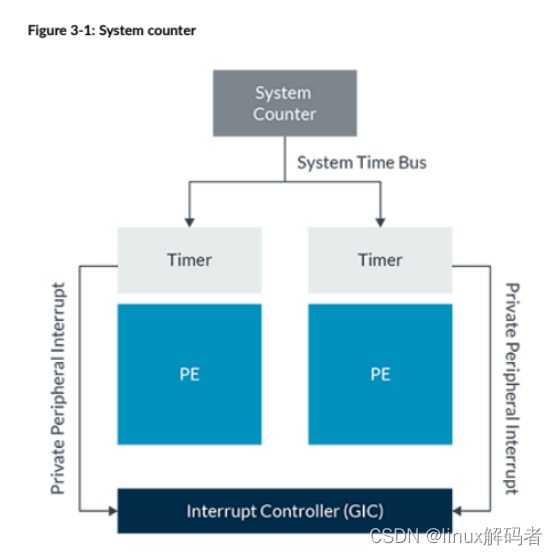
2.3处理中断的模型在多处理器实现中,存在下列模型来处理中断:Targeted distribution model:该模型可以应用于所有PPI和LPI。它也可以应用于:(1)如果GICD_IROUTER<n>.Interrupt_Routing_Mode==0,在非传统操作的SPI;(2)在传统操作时,当GICD_CTLR.ARE_*==0时,如果仅GICD_ITARGETSR<
Generic timer介绍
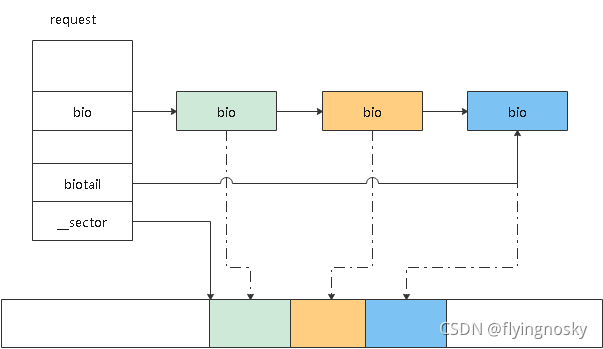
之前计划先将bounce过程,但bounce过程涉及bio的切分,因此本节将bio的操作:切分和合并。前面对bio的组织和分配做了基本的介绍,bio的切分是将一个bio分成两个bio,而合并准确来说是将bio与IO请求request进行合并。1. IO请求request和bio的关系下图反应了request和bio之间的关系。request是由在硬盘位置连续的bio链接起来的。图中request中
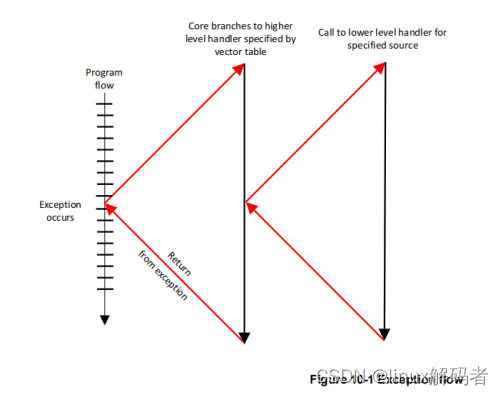
ARMv8-A异常处理
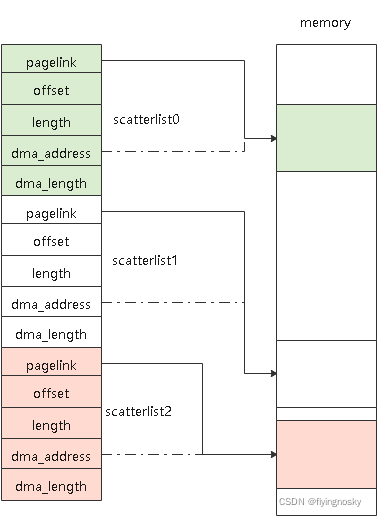
函数dma_map_sg()为流式DMA MAP函数,它将包含多个物理内存区域的SGL映射到连续的IOVA上。与dma_alloc_coherent()相比,它将要映射的物理内存已经分配好,不需要像dma_alloc_coherent()那样在函数中分配,因此速度比dma_alloc_coherent()快,适用于动态分配的场景;另外dma_alloc_coherent()的设备一致性通常通过硬件
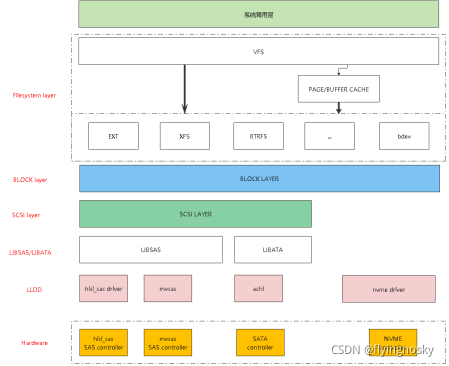
更新了BLOCK层代码分析(1)(2)后,觉得有必要对存储IO框架层次做介绍,因此增加了本小节。1.存储IO框架存储IO内核框架如下图所示:以上列出几种驱动的存储软件框架,包含NVME驱动/SAS驱动/SATA驱动。IO依次经过系统调用层、文件系统层、BLOCK层、SCSI层、LIBSAS/LIBATA层以及LLDD。但并不是所有的这些层都经过,比如对于NVME驱动,对接BLOCK层,并不会经过S
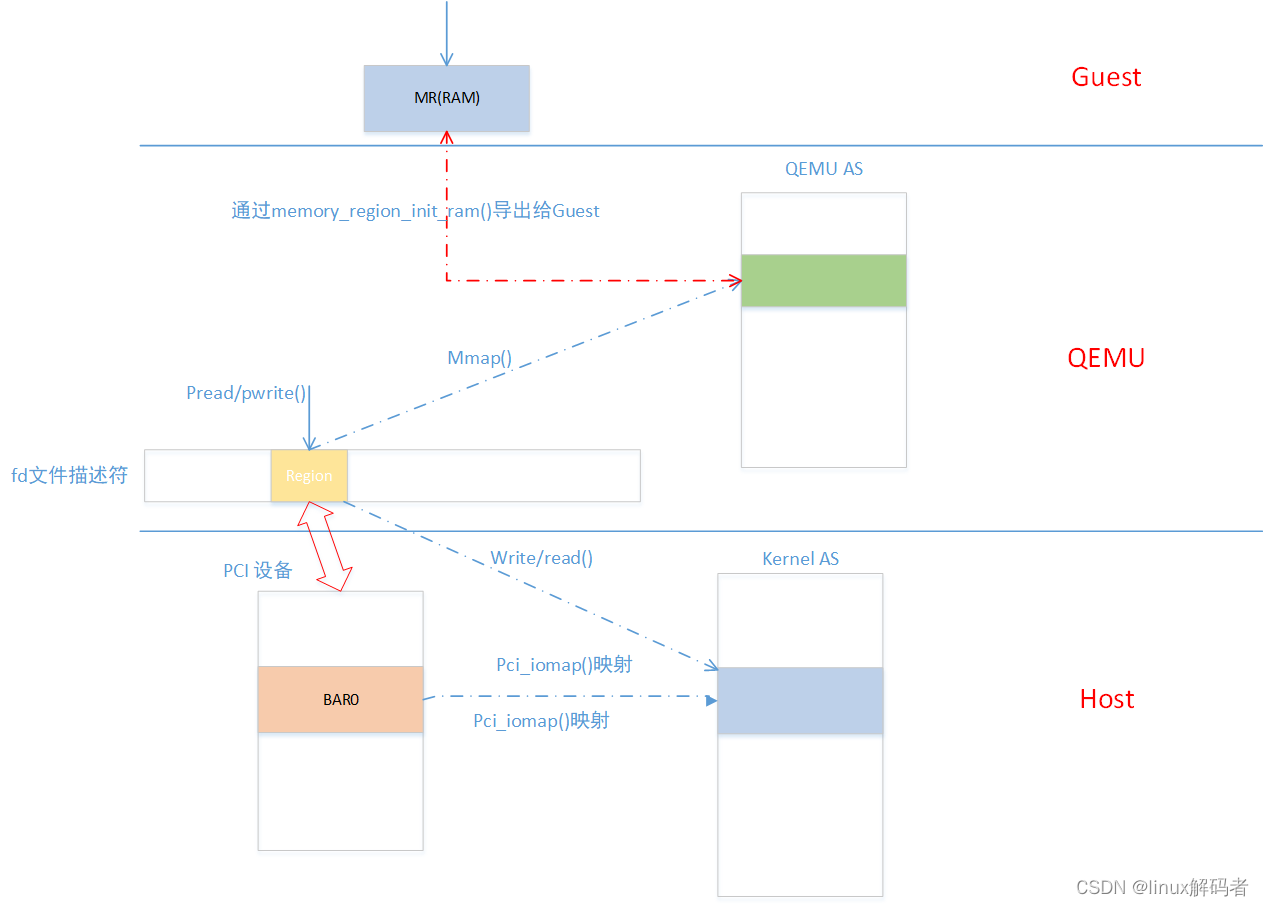
3 VFIO设备的内存信息和地址空间模拟先介绍VFIO中虚拟机中Guest中是如何访问BAR空间的。先看如下图:在Host中通过pci_iomap()将PCI设备的BAR0空间映射到内核地址空间;通过之前VFIO_GROUP_GET_DEVICE_FD将文件描述符fd与PCI设备进行关联,后面对fd的操作最终会操作PCI设备对应的内核地址空间;在QEMU中将文件描述符fd中region通过mmap
QEMU monitor可以通过HMP和QMP链接虚拟机。1 HMP方式1.1 方式一1) 在启动qemu时添加如下命令:-qmp unix:/path/qmp-test,server,nowait \2)在host上使用命令链接:nc -U /path/qmp-test1.2 方式二1)在启动qemu时添加如下命令:-qmp telnet:127.0.0.1:4444,server,nowait
1 描述通常存在一个全局开关来enable/disable vIOMMU。系统中所有的设备仅能通过vIOMMU或全部不通过,这样使使用非常不灵活。我们介绍bypass iommu属性来让设备可以通过也可以不通过vIOMMU。这对于在相同虚拟机上使用no-iommu模式的passthrough设备和通过vIOMMU的设备非常有用。PCI host bridge也有一个bypass_iommu属性。该
8. VHE下图呈现了一个简化的软件栈和异常级别:你可以看到一个独立的hypervisor是如何映射到ARM异常级别。hypervisor运行在EL2而虚拟机运行在EL0/1。这种情况在托管hypervisor上存在问题,如下图所示:通常,内核运行在EL1,但虚拟控制在EL2。这意味着大多数host OS运行在EL1,通过EL2的stub代码来访问虚拟化控制。这种安排效率低下,因为它可能涉及增加的
