- @bbbeoy
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
文章目录 [隐藏]1. 强化学习和深度学习结合2. Deep Q Network (DQN) 算法3. 后续发展3.1 Double DQN3.2 Prioritized Replay3.3 Dueling Network4. 总结强化学习系列系列文章 我们终于来到了深度强化学习。1. 强化学习和深度学习结合
https://zhuanlan.zhihu.com/p/1229973702017年NIPS上的文章"Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation"提出了一种Actor Critic using Kronecker-Factored Trust
Introduction“Money makes the world go round” is something which you cannot ignore whether to choose to agree or disagree with it. A more apt saying in today’s digital revolutionary age would be “Dat..
Memory Access Patterns大部分device一开始从global Memory获取数据,而且,大部分GPU应用表现会被带宽限制。因此最大化应用对global Memory带宽的使用时获取高性能的第一步。也就是说,global Memory的使用就没调节好,其它的优化方案也获取不到什么大效果,下面的内容会涉及到不少L1的知识,这部分了解下就好,L1在Maxwell之后就不用了,..
[-]监督学习及其目标函数损失函数loss函数平方损失函数最小二乘法 Ordinary Least Squares平方损失Square loss的标准形式最小二乘法解线性回归最小二乘解log对数损失函数逻辑回归log损失函数的标准形式交叉熵logistic的损失函数表达式Hinge损失函数SVMHinge 损失函数的标准形式核函数感知损失感知机算法感知机算法的损失函数两者的等价指数损失函数Adab
按语:当数据含有离群点(Outliar)或者强影响点(influential observation)时,稳健回归(Robust Regression)会比普通最小二乘法(OLS)的表现要更优异。稳健回归也可以用来检测数据中的强影响点。提示: 本文旨在介绍与稳健回归相关的R命令,因此,并未全面覆盖稳健回归的相关知识,也不涉及数据清洗、数据检测、模型假设和模型诊断等内容。文档内容基于R 2.
1. 定义两个不同的图import tensorflow as tfg1 = tf.Graph()with g1.as_default():v = tf.get_variable("v", [1], initializer = tf.zeros_initializer) # 设置初始值为0g2 = tf.Graph()with g2.as_default():v
作者:余霆嵩本文就近年提出的四个轻量化模型进行学习和对比,四个模型分别是:SqueezeNet、MobileNet、ShuffleNet、Xception。目录一、引言二、轻量化模型2.1 SqueezeNet2.2 MobileNet2.3 ShuffleNet2.4 Xception三、网络对比一、引言自 2012 年 ...
这里的动机是一个pair的频率很高,但是其中pair的一部分的频率更高,这时候不一定需要进行该pair的合并。通过这种方式可以更好的处理跨语言和不常见字符的特殊问题(例如,颜文字),相比传统的BPE更节省词表空间(同等词表大小效果更好),每个token也能获得更充分的训练。1. 根据不同的切分粒度可以把tokenizer分为: 基于词的切分,基于字的切分和基于subword的切分。这是当前大模型的
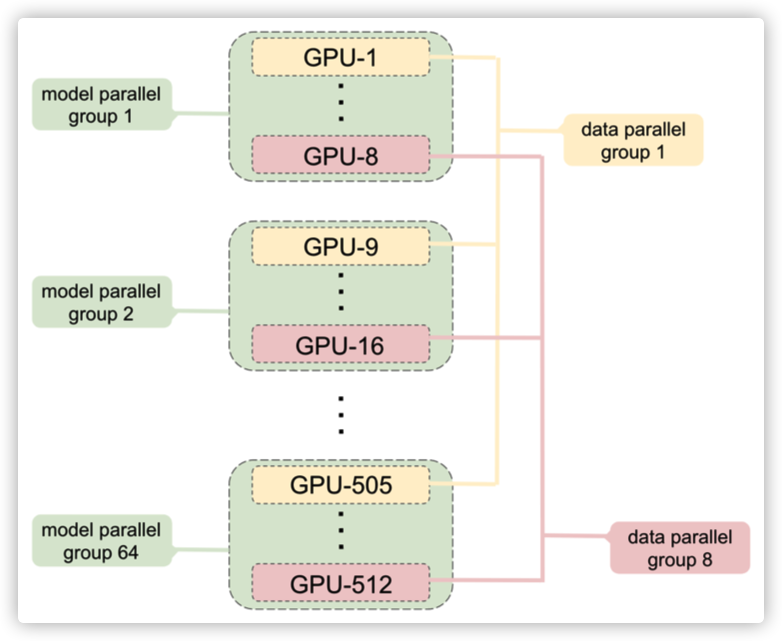
NVIDIA Megatron 是一个基于 PyTorch 的分布式训练框架,用来训练超大Transformer语言模型,其通过综合应用了数据并行,Tensor并行和Pipeline并行来复现 GPT3,值得我们深入分析其背后机理。本系列大概有6~7篇文章,通过论文和源码和大家一起学习研究。本文把 Megatron 的两篇论文/一篇官方PPT 选取部分内容,糅合在一起进行翻译分析,希望大家可以通过