




- @KIDGIN7439
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
为了优化延迟,low lantency使用卡间直接收发cast成fp8的数据的方式,而不是使用normal算子的第一步执行机间同号卡网络发送,再通过nvlink进行转发的两阶段方式。进一步地,normal算子的dispatch包含了notify_dispatch传输meta信息和dispatch传输实际数据两个kernel,而low lantency也省去了notify的过程,为此需要的代价就是显

上节介绍了通信链路的建立过程,本节介绍下单机内部ncclSend和ncclRecv的运行过程。单机内的通信都是通过kernel来完成的,所以整个通信的过程可以分为两步,第一步是准备kernel相关的参数,第二步是实际执行kernel的过程。

上节以ringGraph为例介绍了机器间channel的连接过程,现在环里每个rank都知道了从哪个rank接收数据以及将数据发送给哪个rank,本节具体介绍下P2P和rdma NET场景下数据通信链路的建立过程。
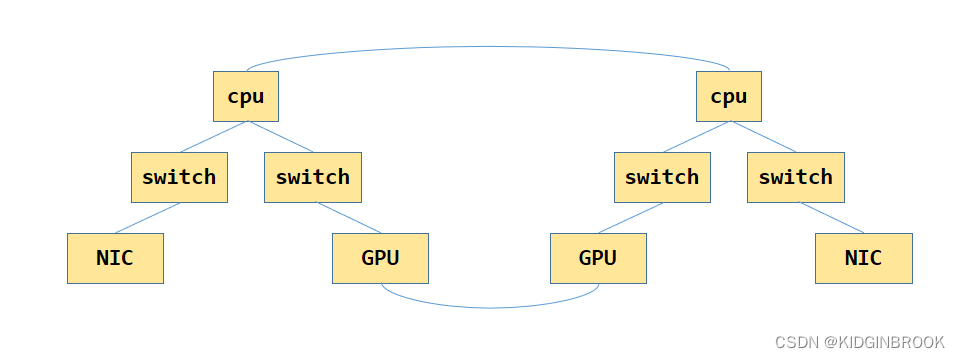
上次分析到nccl对机器PCI系统进行拓扑分析的过程,产出的结果为xml格式,接下来,nccl会根据这个xml进图的建立过程以便之后进行路径搜索。
上节中完成了单机内部的channel搜索,仍然以ringGraph为例的话,相当于在单台机器内部搜索出来了一系列的环,接下来需要将机器之间的环连接起来。
上节我们介绍了IB SHARP的工作原理,进一步的,英伟达在Hopper架构机器中引入了第三代NVSwitch,就像机间IB SHARP一样,机内可以通过NVSwitch执行NVLink SHARP,简称nvls,这节我们会介绍下NVLink SHARP如何工作的。

为了方便之后的搜索channel,接下来NCCL会计算GPU和NIC节点到其他任意节点之间的最优路径
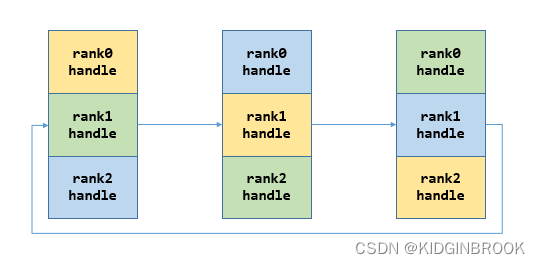
nccl里bootstrap环形网络连接的创建过程
nccl中channel的概念表示一个通信路径,为了更好的利用带宽和网卡,以及同一块数据可以通过多个channel并发通信,另外后续可以看到一个channel对应了一个GPU SM,所以基于这些原因,nccl会使用多channel,搜索的过程就是搜索出来一组channel。
因此基于这一点,mellanox提出了SHARP,将计算offload到了IB switch,每个节点只需要发送一次数据,这块数据会被交换机完成规约,然后每个节点再接收一次就得到了完整结果。
