
写文章




- @DeerEyre
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
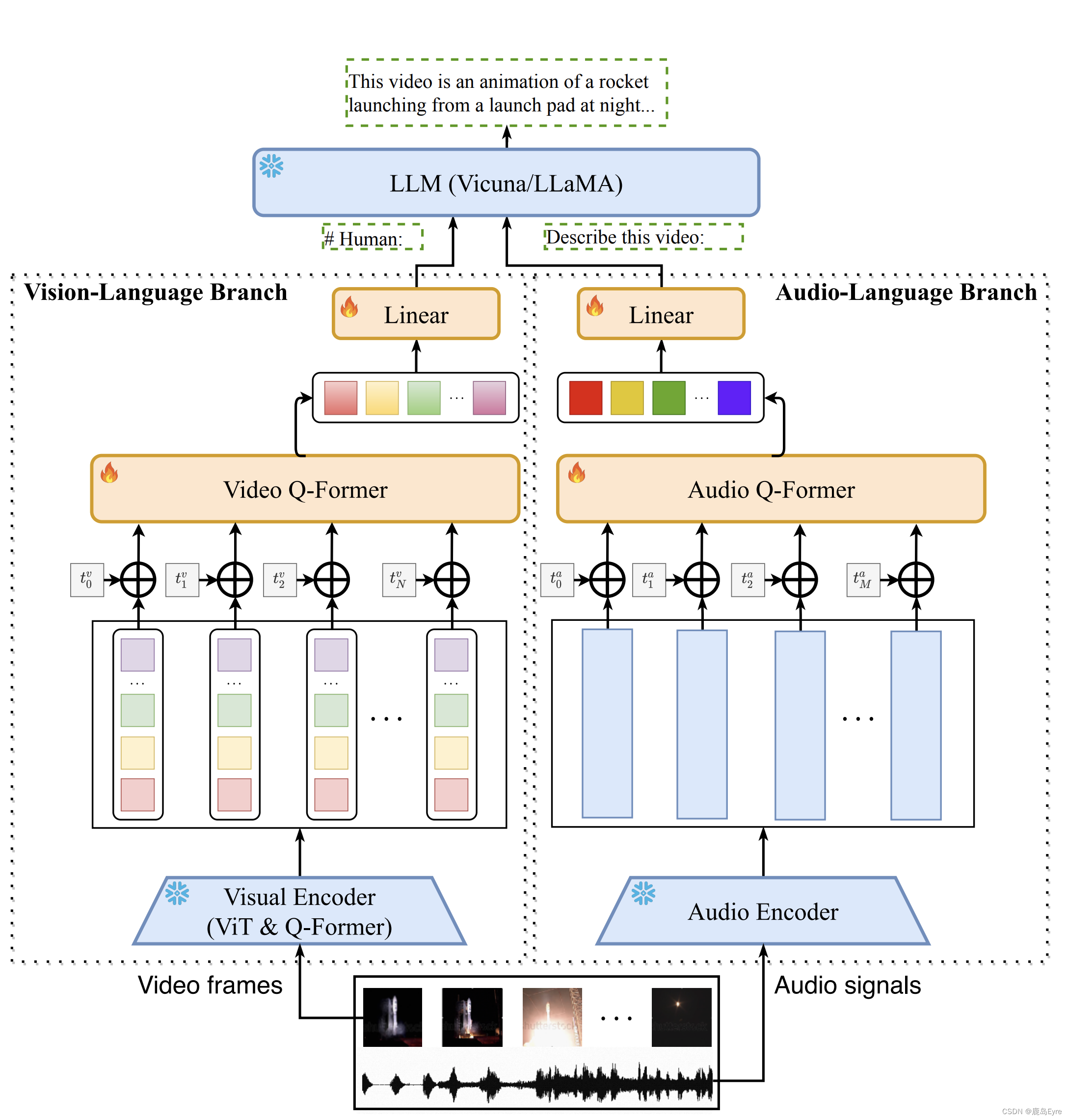
Video-LLaMA 论文精读
基于大量文本数据训练的LLM模型,表现非凡,尽管它们取得了很大成功,但大多数用户只能通过文本去与LLM进行交互。为了最大化发掘其潜力,将视觉理解能力加入LLM成为趋势。BLIP-2,由于其从冷冻的图像encoder与文本decoder引导视觉语言预训练而备受关注。但是难以准确理解非平稳的视觉场景,缓解视频与文本之间的模态间隙比图像和文本更具挑战性。本文的工作力图攻克视频转文字,并非采用外部感知模型
到底了