
写文章




- @2401_82437081
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
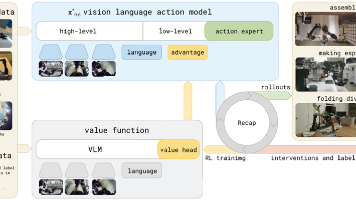
π0.6详解
解决的问题:在一个通用且扩展的机器人系统中成功实现RL(强化学习)重大挑战1.为大型模型设计可扩展且稳定的强化学习方法2.处理来自不同策略的异构数据3.在现实世界中建立带有奖励反馈的强化学习训练——奖励信号可能存在歧义或随机性解决方案:1.二值化优势值条件化通过优势值评估筛选出低质量的动作轨迹达到降噪,提高学习效果的目的;使得模型从传统RL中的模仿转为评估数据本身2.设计出Recap方案与价值函数
到底了