

腾讯云CDW-ClickHouse云原生实践
本文介绍腾讯云数仓产品CDW-ClickHouse从云托管向云原生架构演进。探讨了利用云原生架构对开源ClickHouse进行改造过程中的难点与挑战、方案设计、关键技术、以及后续规划。
1. 前言
开源列式数据库ClickHouse以极致的性能、超高的性价比获得了广泛好评。在PB级查询分析场景下ClickHouse是最佳解决方案之一。开源ClickHouse集群采用SHARED-NOTHING架构,增加计算节点非常容易。
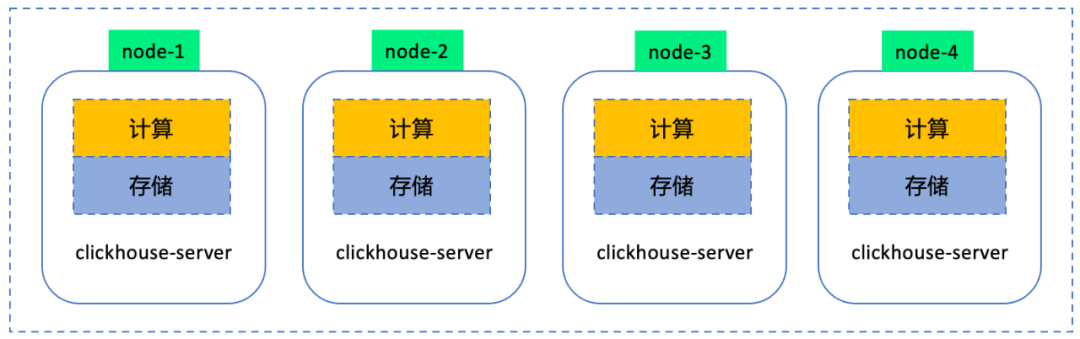
图1:开源ClickHouse架构
但是,开源ClickHouse也有明显的不足之处:
-
采用存算一体架构,计算与存储耦合。
存储与计算资源无法独立扩展。用户对计算与存储资源非对称需求越发强烈,并且希望云服务商能够提供更为灵活的资源编排能力。 -
不具备弹性能力。
开源ClickHouse集群没有数据均衡功能(rebalance)。在云托管ClickHouse阶段,通过业务层来均衡数据,代价大,耗时长。弹性效率十分低。 -
运维成本高。
开源ClickHouse运维成本高。例如,当集群扩容后,增量计算节点无法自动同步存量节点的SCHEMA信息,需要人工介入。
随着云原生理念深入人心,利用云原生架构对开源ClickHouse进行改造,计算资源池化,存储与计算分离,势在必行。业界对云原生ClickHouse并没有明确的定义。云原生ClickHouse至少需要具备以下特征:
-
采用存算分离架构,计算资源与存储资源独立扩展,按需付费;
-
高效弹性,计算资源扩容时数据Zero-copy;
-
计算资源池化,根据业务需求灵活编排计算资源;
-
易运维,甚至免运维,只关注业务本身;
腾讯云数仓服务CDW-ClickHouse已从云托管演进为云原生服务,下文简称云原生ClickHouse。本文叙述开源ClickHouse云原生改造过程中的难点、方案设计、关键技术、以及未来规划。
2. 云原生架构
为了解决开源ClickHouse的痛点,腾讯云CDW-ClickHouse采用了全新存算分离架构,将服务分为元数据服务层、计算层 和存储资源层。
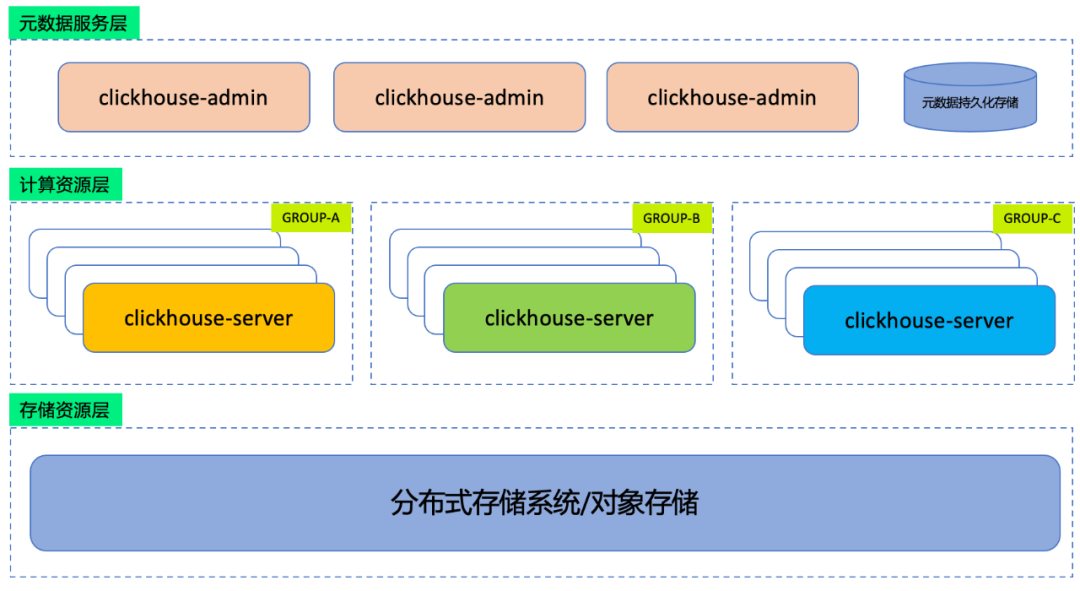
图2:云原生ClickHouse架构图
元数据服务层:元数据服务层包含集群管理节点clickhouse-admin 以及 元数据持久化存储。元数据管理节点clickhouse-admin负责管理集群的元数据元数据包括集群的数据分布表、SCHEMA信息等。同时,clickhouse-admin 还负责计算节点的保活功能。集群管理节点clickhouse-admin为无状态设计,可水平扩展。
计算层:云原生ClickHouse计算层由计算组构成,计算组为计算节点集合。在计算层计算节点可以分组隔离。部署clickhouse-server节点为无状态存在,数据存储剥离到分布式存储系统或对象存储之中。用户可以根据业务合理编排计算资源。
存储资源层:云原生ClickHouse对存储资源做了统一抽象,用户无需关注底层存储。架构层方便集成更多云上分布式存储服务。可以集成低成本无限容量的对象存储,也可以集成低延迟高吞吐的分布式文件系统。
目前,已经集成了对象存储COS,以及分布式文件系统CFS。
接下来章节分别对架构中各部分展开叙述。
3. 集群元数据管理
开源ClickHouse 采用的是SHARED-NOTHING架构,节点之间并不同步一些关键的信息。用户向集群新增节点后,增量节点并不会自动从存量节点上继承SCHEMA信息,导致易用性极差。云原生ClickHouse 引入clickhouse-admin角色,用于管理集群全局信息:
-
数据分布表:共享存储中数据与计算节点映射关系数据。
-
SCHEMA信息:ClickHouse集群中的schema对象。
-
配置信息:包括计算节点配置,共享存储配置,以及计算分组的配置等。
该角色为集群的管理节点,无状态设计,具体数据存储在持久化系统中。在具体部署中,clickhouse-admin节点可以根据情况进行多节点部署,共同分担负载。
3.1 处理DDL请求
云原生ClickHouse 引入了新的管理节点。为了简化部署,也为了方便集群元数据统一管理,clickhouse-admin接管了DDL功能。云原生ClickHouse不再依赖ZooKeeper集群。
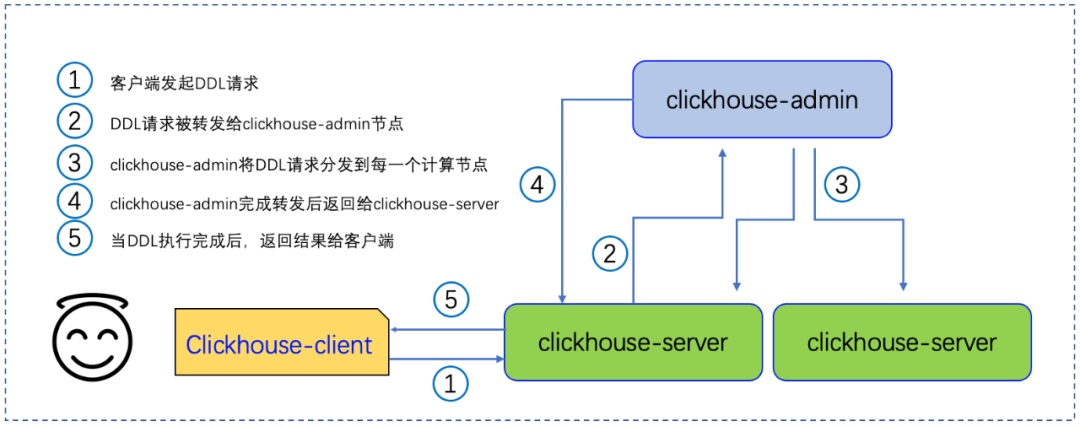
图3:统一处理DDL请求示意图
如图3所示,在一个简单的部署环境中,DDL请求执行流程。客户端发给clickhouse-server的请求,会转发到clickhouse-admin。接着,clickhouse-admin 统一将请求分发到对应计算组的节点。当前请求完成后,结果再原路转发给客户端。
在DDL被接管后,集群SCHEMA信息会被统一管理。这是后续集群扩容,节点重启,确保SCHEMA一致的基础。
3.2 元数据分发
开源ClickHouse 采用的SHARED-NOTHING架构。集群的节点之间并不同步元数据。当集群新增节点,或者节点重启后,节点无法获取到集群最新的SCHEMA信息。这也是ClickHouse用户的痛点之一。
云原生ClickHouse集群在节点启动时,会向clickhouse-admin注册服务。如果不属于该集群的节点,会注册失败。完成注册后,clickhouse-server从clickhouse-admin获取最新的元数据,包括schema信息、数据分布表信息。随后,clickhouse-server 进入数据加载阶段。
计算节点clickhouse-server 启动完成后,会与管理节点clickhouse-admin进行心跳同步。心跳信息中包含了元数据的版本信息。若版本变化,则同步更新最新元数据。从而在集群范围内,计算节点获取的元数据最终一致。
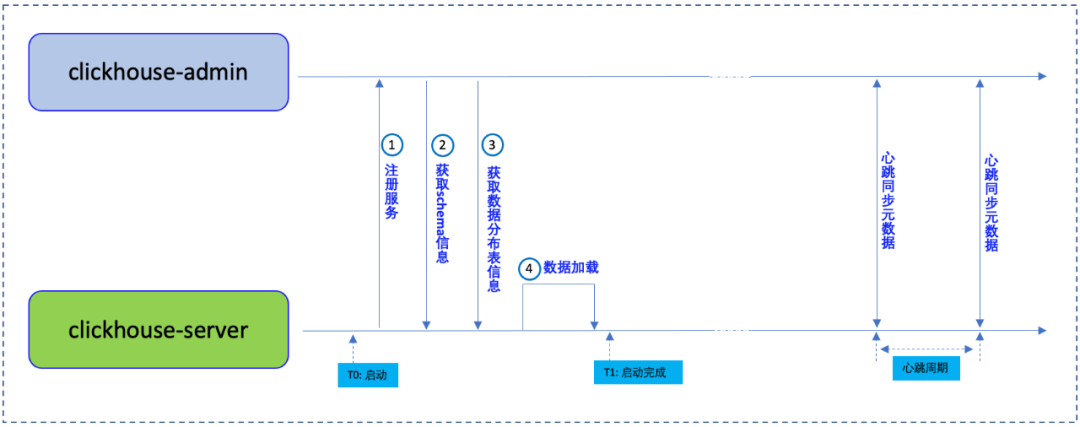
图4:原数据分发:启动和心跳
元数据分发功能为弹性伸缩奠定基础。
3.3 失败节点检测
在云原生ClickHouse集群中,计算节点clickhouse-server 与元数据管理节点clickhouse-admin之间保持心跳。clickhouse-admin 通过心跳信息踢出异常节点、以及感知新节点。
失败检测(Failure detector)通常采用心跳(Heartbeat)模型。在云原生ClickHouse的实现中,并没有单纯根据心跳超时来判断节点失效。由于网络延迟抖动,以及节点负载的变化,单纯根据超时来判断会有很大概率误判。参考Cassandra中失效检测模块的实现,算法细节见。
3.4 计算节点分组隔离
所谓计算组,就是一组计算节点的集合。也就是云原生ClickHouse集群支持部署多计算分组,满足业务按需资源编排。不同资源组可以共享相同数据,实现容灾以及读写分离功能。主要的应用场景:
-
容灾:同集群中,将不同计算分组部署在不同可用区,实现计算层容灾;
-
读写分离:可以规划2个计算分组,一个用户数据写入,一个用于数据的查询,避免数据写入与查询相互干扰。
-
按业务需求合理编排计算资源:对于测试,可以分配小规模低配置计算组,对应重要业务分配更高配置计算资源。
目前,还不支持多计算组。这是云原生ClickHouse后续重要功能之一。
4. 自研表引擎
云原生ClickHouse中集成了自研表引擎:CloudMergeTree 以及 CloudDistributed。
前者基于分布式存储系统或对象存储系统实现数据读写、后台合并、以及数据自均衡。后者职责为ClickHouse分布式数据写入以及查询。
云原生ClickHouse自研表引擎在与开源社区代码级兼容的前提下,具备如下能力:
-
基于分布式存储系统/对象存储实现数据读写;
-
接口保持语义兼容,完整支持ClickHouse-SQL;
-
以Zero-Copy方式实现数据重分布;
-
弹性扩缩时有限影响服务;
虽是自研表引擎,在工程实践过程中,尽可能重用现有代码。关键逻辑都在CloudMergeTree/CloudDistributed中实现。之所以这样做,一个核心因素是为了保持云原生ClickHouse与开源ClickHouse能够同步升级。云原生的代码相对对立,不会耦合在开源ClickHouse现有逻辑里,从而能够确保兼容与升级。
4.1 统一存储视图
云原生ClickHouse的自研表引擎提供了统一的抽象视图,并不绑定在具体的分布式存储系统或者对象存储。
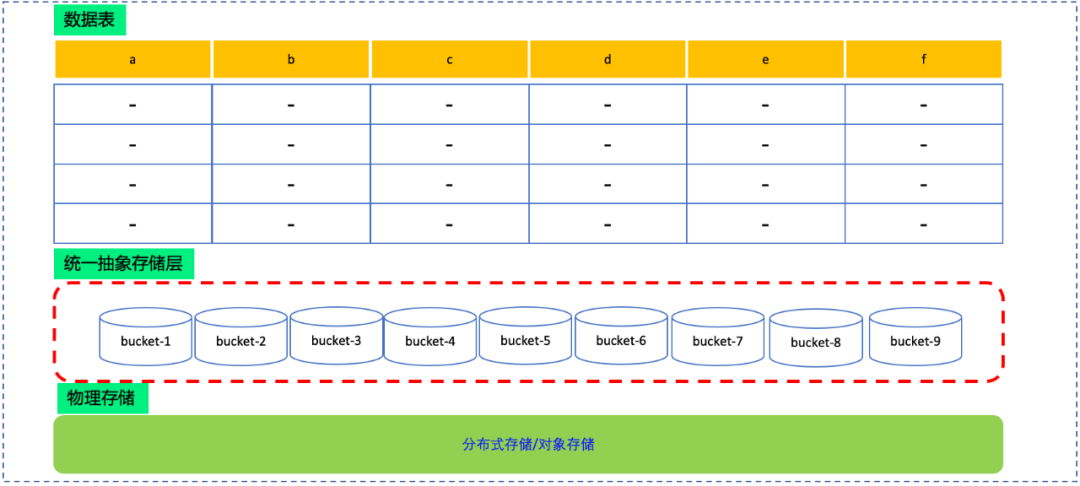
图5 统一存储视图模型
统一抽象存储层屏蔽了底层物理层次的细节。一方面,极大简化了自研表引擎的逻辑;另一方面,方便集成更多分布式存储系统或者对象存储。
统一抽象存储层将底层存储系统划分为固定数量的逻辑单位,简称为桶(Bucket)。具体桶的数量,在创建表是指定。抽象存储层的桶会均衡的分布在计算组内计算节点中。桶与计算节点之间的映射关系,称为数据分布表,由管理节点维护。划分桶的核心原因在于,简化弹性伸缩时数据重分布:
-
当扩容时,存量节点上的桶会重新分配给增量节点;
-
当缩容,或节点被踢出时,一部分桶会重新分配给存量节点;
显然,弹性伸缩时,只有数据桶重新分布,出发数据加载与卸载,而没有数据复制。极大地提升了弹性效率。
4.2 数据重定向
在统一抽象存储视图前提下,为了更好支持ClickHouse 分布式JOIN计算,用户可以通过 CloudDistribyted 的SHARD BY expr子句自定义表的数据分布。用户通过对参与JOIN的表作统一数据分布,可以实现COLOCATE JOIN。
举例:
CREATE TABLE test ( `i` Int64, `s` String ) ENGINE = CloudMergeTree ORDER BY i基于表test创建分布式表。
CREATE TABLE test_dist ( `i` Int64, `s` String ) ENGINE = CloudDistributed('default', 'default', test) SHARD BY xxHash32(i) % 99与开源ClickHouse不同之处在于,创建分布式表时,可以指定数据分布的规则,即SHARD BY expr。如上例中,当数据写入时候,会评估每一行数据在xxHash32(i) % 99的值,该值与桶的总数量取模运算,获取桶ID,数据将被分发到对应的桶中。
4.3 数据写入
云原生ClickHouse与开源ClickHouse写入流程类似,基于统一抽象存储层实现。
在开源ClickHouse中,同一个表在每一个节点上独立分配递增的BLOCK ID(可以理解为逻辑时间戳,用于标记数据写入的时序关系)。很明显,拥有较大的BLOCK ID的数据要后于拥有较小BLOCK ID的数据。
在云原生ClickHouse中,同一个表为每一个桶中维护了递增的BLOCK ID。这个BLOCK ID维护在管理节点中。正因为如此,一些后台任务(MERGE/MUTATE),是以桶为单位进行的。
为了避免弹性伸缩期间影响数据写入,每个节点写入数据时,需要满足如下要求:
-
向数据桶提交数据全局有序;
-
任意计算节点提交数据前,需要加载其他节点已提交数据(若有);
-
持有数据桶的计算节点,需要周期性加载其他节点已提交的数据(若有);
为此,实现了数据多节点并发提交机制。由于多个节点并发向桶中提交数据(data part),每个节点看到的数据不一定是最新的。在具体实现中,节点会周期性检查是否有新的数据需要加载。从而确保任意节点写入数据的最终一致性。更重要的时,需要确保不同节点看到数据提交的顺序是一致的。
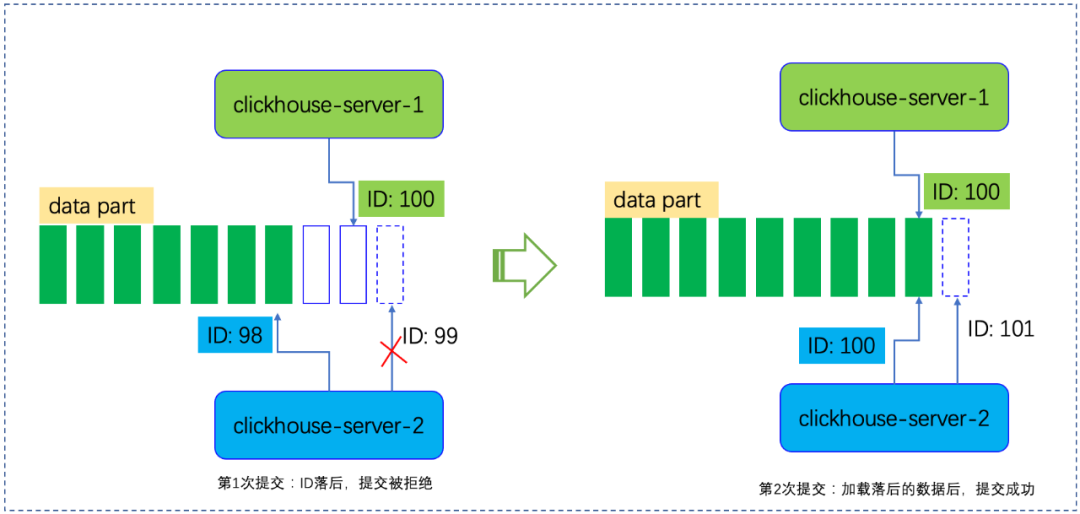
图6 多节点并发写入以及冲突解决示意图
如图所示,节点 clickhouse-server-2 第一次提交数据时,它本地感知到的ID是98,它用ID 99来向clickhouse-admin提交数据。clickhouse-admin看到当前ID为100(其中ID99-100的数据为clickhouse-server-1提交),因此拒绝了该节点的数据提交。clickhouse-server-2 启动加载流程,加载ID99-100的数据后,以ID101重新提交数据,这次由于没有其他节点成功提交,故提交成功。
计算节点提交数据时候,会携带本地维护的ID。clickhouse-admin 收到提交请求后,若请求携带的ID落后于全局ID,则拒绝提交。如果提交的ID与全局ID吻合,则接受提交。当提交拒绝时,说明其他节点已经提交了数据,需要加载这部分数据后,再用新的BLOCK ID来提交数据,直到提交成功。
当弹性伸缩时,数据分布表在不同节点上可能不一致。存在多个节点同时写入同一个桶的情况。多节点并发机制确保了弹性伸缩阶段写入数据的正确性。也就是说,弹性伸缩期并不影响集群数据写入。
并发写入机制是后续跨可用区容灾,计算组节点容灾的基础。
4.4 数据查询
云原生ClickHouse与开源ClickHouse查询流程类似,基于统一抽象存储层实现。
在弹性伸缩过程中,数据桶发生迁移,即从一个节点调整到另外一个节点。在这个过程中,集群中多个计算节点看到的数据桶分布表不一致。在不一致期间,分布式查询的结果一定是错误的。
为了避免将错误的结果返回给客户端,云原生ClickHouse 执行分布式查询时,会检查数据分布表,若分布表不同,则抛出异常。客户端收到异常后,需要重试。
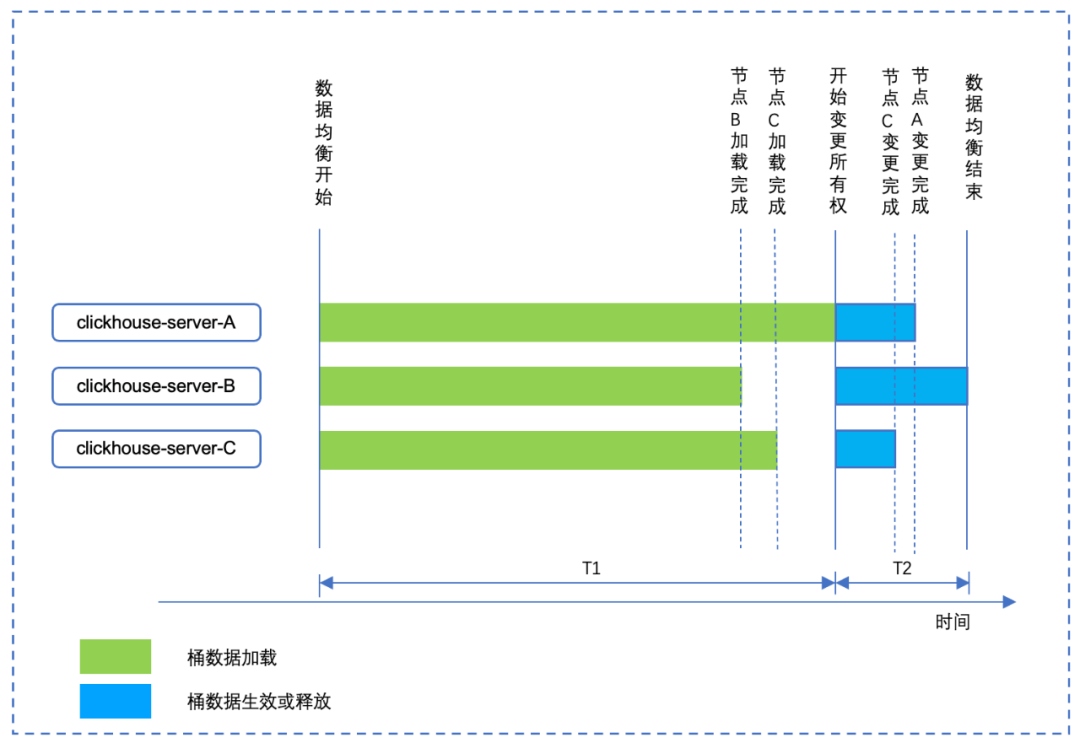
图7 桶迁移示意图
如图所示,在数据加载阶段,也就是T1时间内,查询服务仍然走原有节点。而在数据桶生效或者释放阶段,也就是T2时间内,数据桶分布表不一致,在该时间段内拒绝查询。
由于数据桶生效或者释放是非常短的时间,数据均衡对数据查询服务影响时间控制在较小时间段内。
5. 高效弹性
云原生ClickHouse实现了存储与计算资源分离。在弹性能力方面:
-
存储资源层:无论是分布式存储系统或对象存储,都天然具备弹性能力;
-
计算资源层:计算节点分组隔离,可以动态增加或减少计算分组。计算分组内可以动态增加和减少计算节点。
云原生ClickHouse对存储资源弹性扩展时,不会附带任何计算资源成本。在计算资源弹性时,只存在数据桶的所属关系变迁,无数据复制,弹性效率极大提升。
6. 未来工作
目前,云原生ClickHouse已经具备做到完整的弹性伸缩能力。用户可以按需购买计算资源与存储资源。在运维方面,云原生ClickHouse依赖云上运维管控系统,为用户提供开箱即用的服务。
云原生ClickHouse与开源ClickHouse有明显区别:
| 开源ClickHouse | 云原生ClickHouse | |
| 弹性效率 | 极低,伴随资源浪费、停服时间长 | 秒级弹性,实际受存量数据规模影响 |
| 架构 | 存算一体 | 存算分离 |
| 存储资源弹性 | 扩容存储资源,需额外支付计算成本 | 存储资源独立扩容,按量付费 |
| 计算资源弹性 | 扩容节点后,数据无法自动均衡 | 自动数据均衡 |
未来工作包括:
-
增强对象存储查询效率,包括冷热数据管理、缓存管理等。
-
支持计算节点容灾,包括支持多计算组实现跨可用区容灾,也支持计算组内计算节点容灾。
-
自研存储引擎支持UPSERT能力。
敬请期待。

更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)