
快速 Python Pandas:拆分数据框的两种方法
假设您有一个相当大的数据框。无论出于何种原因,您都希望以某种方式将其分成两部分。在本文中,我将介绍两种常见的方法: 将数据框分成两部分:前 N 行(或行数的百分比)和其余部分; 按行数或百分比将其随机分成两部分。 作为示例数据,我将在大约三个月内使用我的 Spotify 流媒体历史记录,其中包含 6184 行。 (这意味着我平均每天听近 70 首歌曲!谁能想到?) 如果您碰巧喜欢这些歌曲或艺术家中
假设您有一个相当大的数据框。无论出于何种原因,您都希望以某种方式将其分成两部分。在本文中,我将介绍两种常见的方法:
-
将数据框分成两部分:前 N 行(或行数的百分比)和其余部分;
-
按行数或百分比将其随机分成两部分。
作为示例数据,我将在大约三个月内使用我的 Spotify 流媒体历史记录,其中包含 6184 行。 (这意味着我平均每天听近 70 首歌曲!谁能想到?)
如果您碰巧喜欢这些歌曲或艺术家中的任何一首,请告诉我! 😎
import pandas as pd
df = pd.read_json('./StreamingHistory.json')
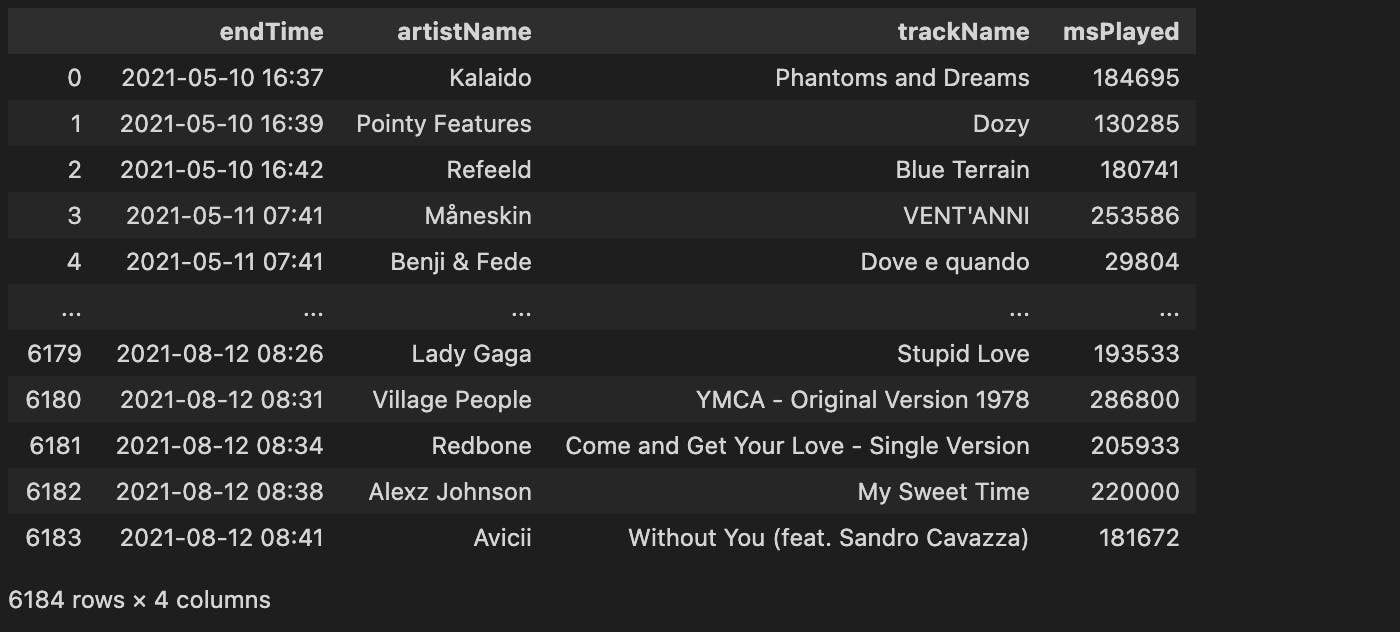
1.取数据框的前 N 行
在这两种情况下,棘手的部分是将第二个数据帧存储在另一个变量中。让我们看看如何做到这一点。
首先,让我们从数据帧中取出前 1000 行,并将其存储在一个新的数据帧df_1中:
df_1 = df.iloc[0:1000]
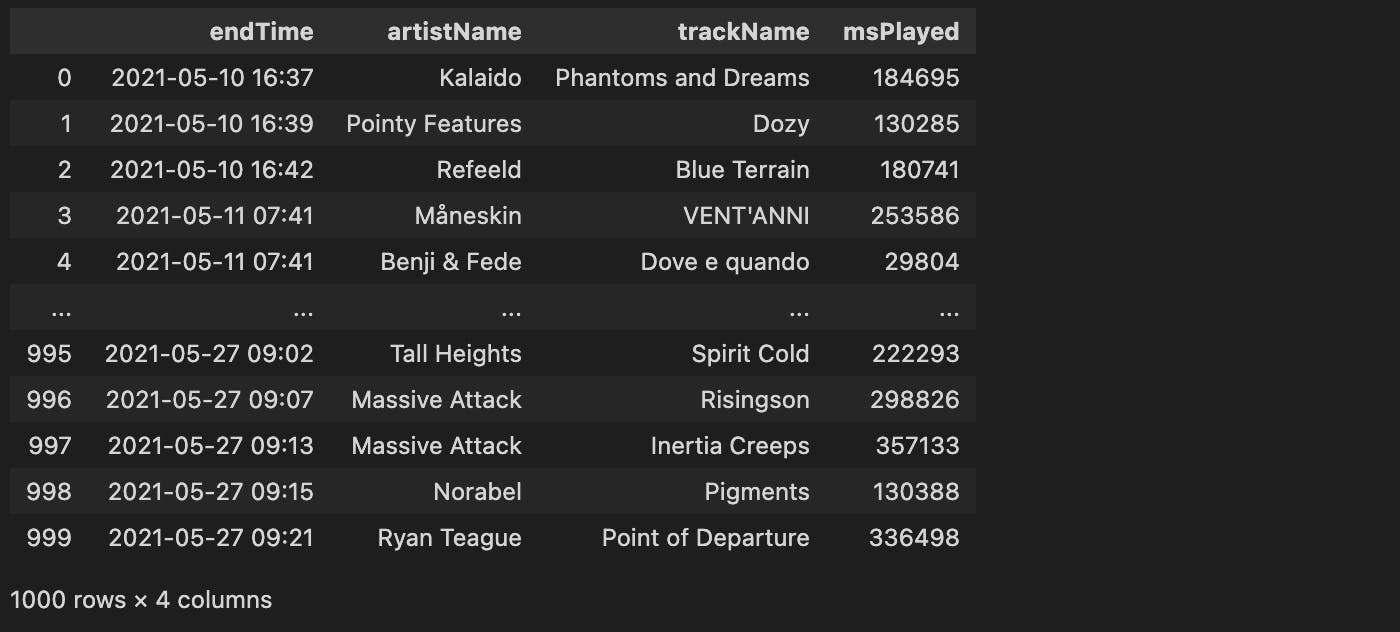
这非常简单:iloc将索引范围作为参数,并根据该范围对数据帧进行切片。
要获取初始数据帧的剩余部分,我们可以使用以下行:
df_2 = df.loc[~df.index.isin(df_1.index)].reset_index(drop=True)
在这种情况下,loc通过布尔条件进行切片——我们只采用那些在df_1中不是的索引。然后,我们必须重置结果切片中的索引,否则df_2将从索引 1000 开始。
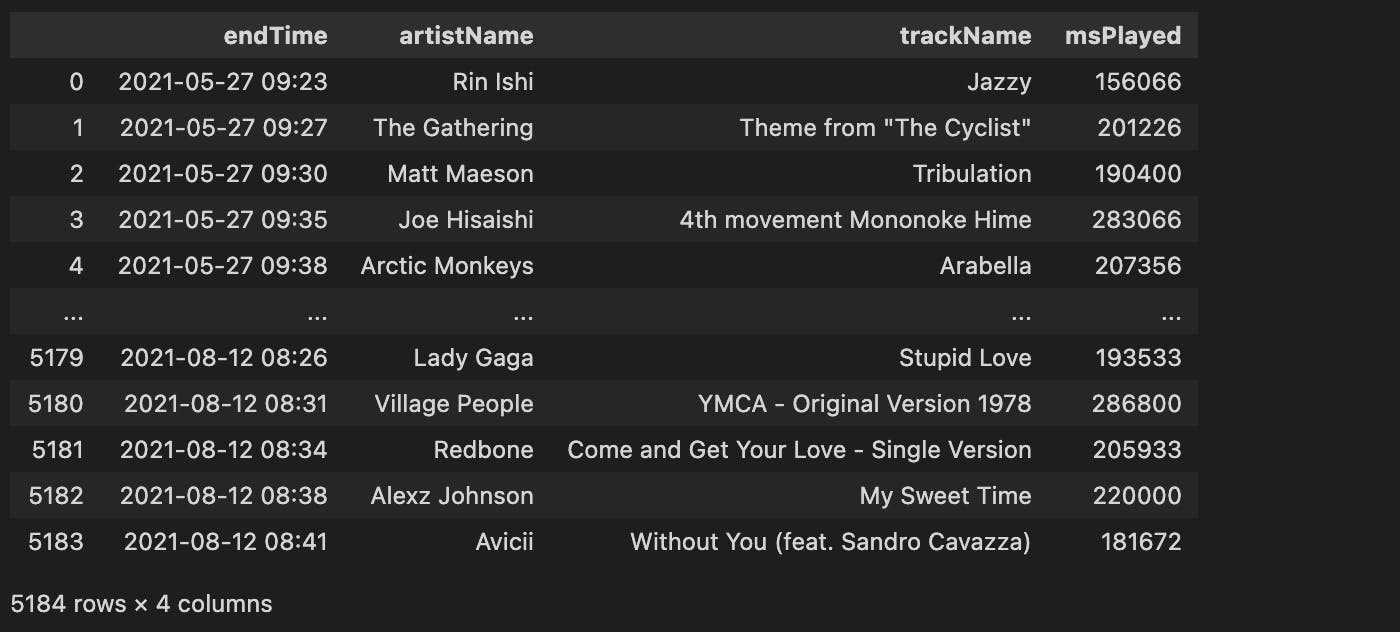
奖励:如果你想使用原始df的一小部分来指定df_1的大小,你可以这样定义:
frac = 0.9
df_1 = df.iloc[0:round(len(df) * frac)]
2.随机分成两部分
将数据集分成两个随机部分的一个常见原因是训练和验证机器学习模型。在 PyTorch 中有一个名为random_split的内置方法来执行此操作。但是,它返回一个Subset对象,而不是原始的Dataset类型。因此,如果您有自定义的数据集类型,使用random_split可能并不简单。
在这种情况下,或者在任何其他情况下,当您需要数据帧的两个(或一个!)随机部分时,您可以使用 Pandas 方法sample。我们可以分别使用 argsn或frac指定我们想要的随机样本中的行数或原始数据帧的比率:
df_1 = df.sample(n=5000) # or: frac=0.9
df_2 = df.loc[~df.index.isin(df_t.index)].reset_index(drop=True)
df_1 = df_1.reset_index(drop=True)
我们还必须在df_1上重置索引,因为随机数据帧的索引只是随机索引。但!我们必须在定义df_2之后,否则我们将无法正确获取剩余的行。
这是我们生成的数据框:
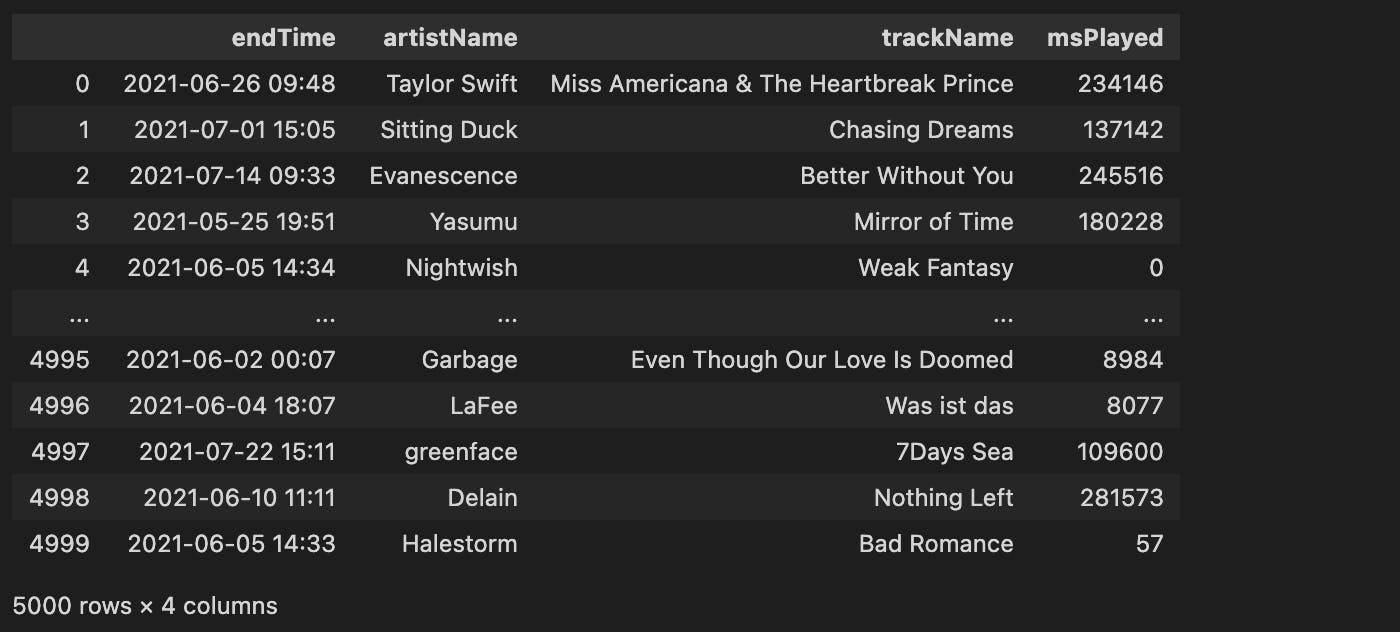
请注意,与第一个不同,第二个数据帧中的记录仍按时间顺序排列。
如果您有时间序列数据,这种随机抽样似乎没有多大意义,如本例所示。或者,如果您想根据过去的收听创建一个惊人的随机播放列表,它也可以!
结论
这些是一些简单的技巧,但是当我从事类似的任务时,我总是忘记如何获取第二个数据帧。希望我已经为其他读者以及未来的我清楚地解释了这一点! 🔮
如果您对 Python 和 Pandas 有任何问题或建议,请发表评论。或者只是谈论音乐,当然!
顺便说一句,感谢您的阅读😊您赢得了意大利摇滚乐队 Måneskin(欧洲电视网 2021 年获奖者)的一首优美的歌曲。
图片来源:
- 封面:催化剂材料, Freepik

学AI,认准AI Studio!GPU算力,限时免费领,邀请好友解锁更多惊喜福利 >>>
更多推荐

 0
0 0
0- 0



 已为社区贡献126473条内容
已为社区贡献126473条内容

所有评论(0)