
使用 Python 进行 Web Scraping 的实用介绍
您是否知道,您实际上可以使用各种抓取技术轻松获取互联网上公开的任何信息或数据? 网络抓取使我们能够使用自动化和一些小的编程基础轻松实现这一目标! 我已经写了很多关于这个主题的文章,但我从来没有完全完成过初学者的介绍,所以今天的课程可能会很长。系好安全带! 您想要执行网页抓取的原因有很多,Python 有很多替代解决方案来处理网页抓取。 今天我们将通过使用 Scrapy 的实践会议来了解 Web 抓
您是否知道,您实际上可以使用各种抓取技术轻松获取互联网上公开的任何信息或数据?
网络抓取使我们能够使用自动化和一些小的编程基础轻松实现这一目标!
我已经写了很多关于这个主题的文章,但我从来没有完全完成过初学者的介绍,所以今天的课程可能会很长。系好安全带!
您想要执行网页抓取的原因有很多,Python 有很多替代解决方案来处理网页抓取。
 今天我们将通过使用 Scrapy 的实践会议来了解 Web 抓取到底是什么,如果不明确定义什么是 Web 抓取,我们将无法继续。
今天我们将通过使用 Scrapy 的实践会议来了解 Web 抓取到底是什么,如果不明确定义什么是 Web 抓取,我们将无法继续。
🔹 什么是网页抓取?
Web Scraping 有很多昵称,例如数据抓取、Web 数据提取等。其想法是,它是将网站中的数据提取为可用格式的方法。
从上面我们可以推断,网页抓取是一种用于从网站中提取大量数据的自动化方法或技术。
如果您曾经手动将网页中的数据复制并粘贴到文本编辑器中,那么您就执行了一种基本形式的网页抓取。
🔹 为什么要进行网页抓取?
网页是使用基于文本的标记语言(HTML 和 XHTML)构建的,并且经常包含大量有用的文本形式的数据。
如果您想获取新的 Web 数据并将其转化为对您的业务有价值的资产,那么 Web 抓取是提高可扩展数据请求效率的最佳方式。
 一些用例;
一些用例;
📌 价格比较
📌 服务商
📌 产品信息
📌天气信息
📌 研发
📌 职位列表
📌 电子邮件地址收集:
以及许多其他相关用例,收集的数据稍后可以转储为 JSON、CSV、文本等,以进行更多分析、机器学习等。
🔹 Web Scraping 是非法的吗?
抓取公共数据一直是一个灰色地带。 2019 年,LinkedIn败诉了,试图辩称它可以防止根据其服务条款抓取公共 LinkedIn 个人资料数据。
大型网站通常使用防御性算法来保护其数据免受网络爬虫的侵害,并限制 IP 或 IP 网络可能发送的请求数量。这导致了网站开发人员和像我这样的抓取开发人员之间的持续战斗。
分析、更改、操作数据或将其出售给其他人肯定是非法的,并且在抓取时也要小心,特别是如果您对特定网站有恶意。
有些网站允许网页抓取,有些则不允许,这将我带到robots.txt文件!
🔹 什么是robots.txt文件?
robots.txt是一个文本文件,它告诉爬虫、机器人或蜘蛛一个网站是否可以,或者应该如何按照网站所有者的规定报废。了解robots.txt文件以防止在网页抓取时被阻止至关重要。
 要知道一个网站是否允许网页抓取,您可以查看该网站的
要知道一个网站是否允许网页抓取,您可以查看该网站的robots.txt文件。您可以通过将/robots.txt附加到要抓取的 URL 来找到此文件。
对于本文,我们正在抓取Investing.com网站。所以,要查看robots.txt文件,网址是invest.com/robots.txt
网站的这个特定部分列出了所有加密货币的列表,这些加密货币可以无限滚动动态加载,但今天我们只能获得前 100 名!
让我们考虑这个例子;
zoz100057
Disallow:
上面的示例允许任何蜘蛛(用户代理)访问网站上的所有内容(Disallow u003du003d True)!如果Disallow是这样的Disallow: /,那就说明我们不能刮它的内容!
如果您是像我们网站这样的网站所有者,您还可以在Disallow字段中指定不允许的内容。
🔹 Scraper 工具和 API
开发人员构建了许多工具来简化 Web 抓取过程,例如 ParseHub、Octoperse、Mozenda、Scraper API、Webhose、Diffbot 等。
所有这些工具都提供了一个抽象的用户界面,有些工具为您提供免费试用,并限制了如果您没有使用他们的高级套餐,您可以实现的目标,这就是我们今天构建自己的蜘蛛的原因!
#Ad
ScraperAPI 是一个 Web 抓取 API 工具,可与 Python、Node、Ruby 和其他流行的编程语言完美配合。
Scraper API 处理数十亿个与网络抓取相关的 API 请求,如果您使用此链接从他们那里获取产品,我会有所收获。
🔹 Python 工具
我爱上了 Python,因为它的大量工具、社区和库可用于几乎所有你想做的事情,而且我也喜欢用 Python 爬取。
Scrapy、Selenium 和 Beautiful Soup 是用 Python 编写的最广泛使用的网页抓取框架。正如我前面提到的,我们将在本文中关注 Scrapy,我们将刮

请注意:在本文中,我将假设您了解一些有关 HTML、CSS 和 Python 的基础知识!
🔹 Scrapy 简介
Scrapy 是一个高级网络爬虫和网络爬虫框架,也是最流行和最强大的 Python 爬虫库之一。
它采用batteries included方法进行抓取,这意味着它可以处理所有抓取工具所需的许多常见功能!因此,开发人员不必每次都重新发明轮子。
安装
pip install scrapy
如果安装有任何问题,请参考官方指南获取更多帮助!
通过打开一个新的命令提示符并输入scrapy检查是否已安装,请注意我使用的是 Windows 机器。
您将在输出中看到以下可用方法。
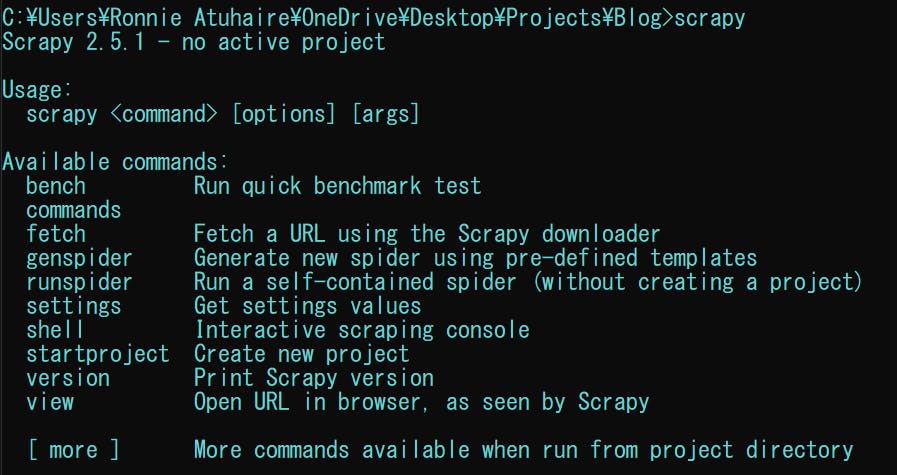
如果无法识别scrapy,您可能需要将其添加到路径变量中,考虑阅读官方指南和这篇文章以使其可识别。
现在让我们玩一些主要的命令;
在终端类型中;scrapy view https://www.investing.com/crypto/currencies上面的脚本将在默认浏览器的新标签页中打开该 URL
scrapy fetch https://www.investing.com/crypto/currencies上面的脚本会在命令行中返回一个HTML文档
scrapy startproject crypto_scraper上面的脚本初始化了一个新项目和样板代码,今天,我们想通过子类化和继承构建我们自己的蜘蛛来保持简单。
🔹 什么是蜘蛛?
蜘蛛是你定义的类,Scrapy 用来从一个网站(或一组网站)中抓取信息。
它们必须继承 Spider 并定义要发出的初始请求,可选择如何跟踪页面中的链接,以及如何解析下载的页面内容以提取数据。
现在让我们创建一个新的 python 文件,你可以随意命名它。我将命名我的crypto_list_scraper.py
首先导入scrapy&csv
import scrapy
import csv
如果我们没有决定构建我们的自定义爬虫,我们可以在 Scrapy 中使用内置的 CSV 服务。
CSV 模块将帮助我们写入文件,我们导入scrapy以便我们可以使用包提供的类。
现在创建一个具有以下变量的新类 & 它继承自Spider类;
class CryptoScraper(scrapy.Spider):
name = 'crypto_spider'
start_urls = ["https://www.investing.com/crypto/currencies"]
output = "crypto_currencies.csv"
可以看到,在我们创建的自定义类中,子类从Spider class继承了所有的方法。
💨name变量用于我们正在创建的蜘蛛名称。
💨start_urls是我们将从中开始抓取的 URL 列表。我们将从一个 URL 开始。
💨output是我们写入爬取数据的地方
让我们初始化我们的输出文件夹,以便我们能够写入我们的输出文件。
def __init__(self):
open(self.output, "w").close()
每次从类创建对象时都会调用__init__函数,并将同一类中的抓取数据传递给引用的输出。
open()和w帮助我们写入被称为self和close()的output file帮助我们对打开的文件进行内存控制。
Scrapy 有parse():一个方法将被调用来处理为每个请求下载的响应。响应参数是TextResponse的一个实例。
所以在我们定义我们的 parse 方法之前,让我们做一些网络检查,看看我们要收集哪些数据,以及DOM存放这些数据的位置。
像许多网站一样,站点有自己的结构和形式,并且有大量可访问的有用数据,但是很难从该站点获取数据,因为它没有结构化的API。
所以从网站上,让我们只收集加密货币的四大项目。
📌排名
📌名字
📌 符号
📌 市值
其余可用数据更具动态性。当您在elements tab下单击鼠标右键时,让我们通过选择inspect(开发工具)来检查我们的目标网站;
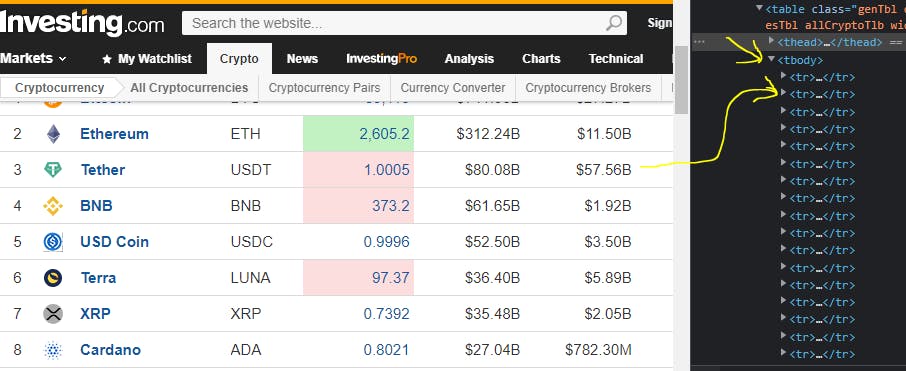
所以当你使用选择器识别结构时,我们看到我们需要的数据驻留在一个表中>>在<tbody>(表体)标签下,然后是<tr>(表行)标签
让我们获取下面的特定标签(您可以ctr + shift + c):
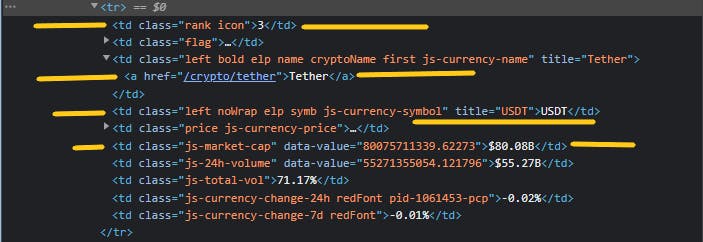
从上面的检查中,我们可以自信地得出以下标签具有相应信息的结论。
📌 排名 ->td > class='rank icon'
📌 名字 ->td > a
📌 符号 ->td > class='left noWrap elp symb js-currency-symbol'
📌 市值 ->td > class ='js-market-cap'
td基本上是表数据。
既然我们有我们需要的所有信息,让我们再次测试获取编码。让我们添加我们的 parse 方法。
def parse(self, response):
crypto_body = response.css("tbody > tr")
with open(self.output, "a+", newline="") as coin:
writer = csv.writer(coin)
我们已经从上面看到我们的目标数据是crypto_body
让我们也使用with语句打开我们的文件,它会自动处理关闭,因此有利于资源管理和异常处理。
a+以coin的形式打开一个文件以进行追加和读取,然后我们使用csv.witer()来追加我们的newline。
在 Scrapy 中,主要有两种选择器,即CSS选择器和XPath选择器。
它们都通过选择相同的文本或数据来执行相同的功能,但传递参数的格式不同。
CSS Selection:由于 CSS 语言是在任何 HTML 文件中定义的,我们可以使用它们的选择器作为在 Scrapy 中选择部分 HTML 文件的一种方式。
XPath Selection:它是一种用于在 XML 文档中选择节点的语言,因此它也可以用于 HTML 文件,因为 HTML 文件也可以表示为 XML 文档。
在同一个缩进中,我们添加下面的代码,我稍后会解释;
import scrapy
import csv
class CryptoScraper(scrapy.Spider):
name = 'crypto_spider'
start_urls = ["https://www.investing.com/crypto/currencies"]
output = "crypto_currencies.csv"
def __init__(self):
open(self.output, "w").close()
def parse(self, response):
crypto_body = response.css("tbody > tr")
with open(self.output, "a+", newline="") as coin:
writer = csv.writer(coin)
for crypto in crypto_body:
RANK = ".//td[@class='rank icon']/text()"
NAME = "td > a ::text"
SYMBOL = ".//td[@class='left noWrap elp symb js-currency-symbol']/text()"
MARKET_CAP = ".js-market-cap::text"
我们使用for loop来获取每个coin(表格行),但这次我们将其命名为crypto并为我们需要的不同数据创建变量,并使用 Scrapy 选择器来识别和选择它们。
我们在RANK和SYMBOL上使用 XPath 选择器及其各自的类,并且text()提取节点的 XPath 响应中的所有文本。
我们在NAME和MARKET_CAP上使用了 CSS 选择器。对于NAME,我们使用来自父节点td的子标签 a 并附加::text来提取文本,我们在MARKET_CAP上使用了一个类
到目前为止,我们的整个文件看起来都是这样,所以让我们测试一下。打开您的终端和文件所在的cd并键入;
scrapy runspider crypto_list_scraper.py
你会得到类似的东西,实际上并没有多大作用,但至少我们有200 HTTP status
 续图输出
续图输出
所以你意识到当你运行它时,output file (crypto_currencies.csv)是在同一个文件夹中创建的,到目前为止没有任何内容,因为我们需要将真实的输出数据写入它。所以暂时删除。
让我们通过在我们创建的最后一个变量下添加它来完成我们的 Spider;
COINS = dict()
COINS["rank"] = crypto.xpath(RANK).get()
COINS["name"] = crypto.css(NAME).get()
COINS["symbol"] = crypto.xpath(SYMBOL).get()
COINS["market_cap"] = crypto.css(MARKET_CAP).get()
writer.writerow([COINS["rank"], COINS["name"],\
COINS["symbol"], COINS["market_cap"]])
yield COINS
Scrapy 通过yield关键字提供了一种保存和存储数据的内置方式。
因此,我们创建了一个COINS空字典,因为我们生成了可以轻松转换为 JSON、CSV 等的字典数据get() 方法。
.get()方法将选择器找到的第一项作为字符串返回。
writer.writerow()一次写入一行。
最后,我们yield我们的字典项目。
这是我们的完整代码。
import scrapy
import csv
class CryptoScraper(scrapy.Spider):
name = 'crypto_spider'
start_urls = ["https://www.investing.com/crypto/currencies"]
output = "crypto_currencies.csv"
def __init__(self):
open(self.output, "w+").close()
def parse(self, response):
crypto_body = response.css("tbody > tr")
with open(self.output, "a+", newline="") as coin:
writer = csv.writer(coin)
for crypto in crypto_body:
RANK = ".//td[@class='rank icon']/text()"
NAME = "td > a ::text"
SYMBOL = ".//td[@class='left noWrap elp symb js-currency-symbol']/text()"
MARKET_CAP = ".js-market-cap::text"
COINS = dict()
COINS["rank"] = crypto.xpath(RANK).get()
COINS["name"] = crypto.css(NAME).get()
COINS["symbol"] = crypto.xpath(SYMBOL).get()
COINS["market_cap"] = crypto.css(MARKET_CAP).get()
writer.writerow([COINS["rank"], COINS["name"], COINS["symbol"], COINS["market_cap"]])
yield print(COINS)
所以我们在yield COINS上添加了一个print()语句,现在让我们在终端不显示日志的情况下运行我们的项目代码。
scrapy runspider crypto_list_scraper.py --nolog
输出:
 你可以在这里找到完整的源代码和 CSV 文件。
你可以在这里找到完整的源代码和 CSV 文件。
🔹 总结
这是一个相当长的内容,您实际上是通过构建一个简单的自定义 Spider 从网站检索加密数据来了解网络抓取的。
显然,你可以用 Scrapy 做更多的事情,尤其是当你创建或启动一个项目时,在不久的将来,我们也可以学习如何创建一个。
我还有其他文章使用Selenium,Beautiful Soup& Requests 来抓取互联网。您可以访问它们以查看其他爬取 Python 技术。
🔹 结论
再一次,希望你今天从我的小衣橱里学到了一些东西。
请考虑订阅或关注我的相关内容,尤其是关于技术、Python 和通用编程的内容。
你可以通过给我买杯咖啡来支持这个免费内容来表达额外的爱,我也对合作伙伴、技术写作角色、协作和 Python 相关的培训或角色持开放态度。
 📢 你也可以在Twitter上关注我:♥ ♥ 等着你! 🙂
📢 你也可以在Twitter上关注我:♥ ♥ 等着你! 🙂

学AI,认准AI Studio!GPU算力,限时免费领,邀请好友解锁更多惊喜福利 >>>
更多推荐

 0
0 0
0- 0



 已为社区贡献126473条内容
已为社区贡献126473条内容

所有评论(0)