Postgres JSONB 使用及性能分析
本故事重点介绍 JSONB 提供的各种功能,并通过示例进行了阐述,并通过可以存储和查询非结构化数据的场景进行了解释。还讨论了来自应用层的数据验证。

什么是JSONB?
PostgreSQL 文档定义的数据类型 JSON 和 JSONB 几乎相同;主要区别在于 JSON 数据存储为 JSON 输入文本的精确副本,而 JSONB 以分解的二进制形式存储数据;也就是说,不是作为 ASCII/UTF-8 字符串,而是作为二进制代码。
这有一些直接的好处:
-
效率更高。
-
处理速度明显加快。
-
支持索引(这可能是一个显着的优势,我们将在后面看到)。更简单的模式设计(用 JSONB 列替换实体属性值 (EAV) 表,可以查询、索引和连接,从而将性能提高到 1000 倍!)
一些缺点:
-
输入稍慢(由于增加了转换开销)。
-
由于更大的表占用空间,它可能比普通 JSON 占用更多的磁盘空间,但并非总是如此。
Postgres JsonB 可以支持的最大大小 根据 Postgres 官方文档,每个文档的最大大小为 255 MB。请查看源代码 这里**.**
select查询的数据保存和分析
请在此处](https://github.com/ereshzealous/spring-data-jpa-audit)找到具有审计框架以及[的 java 前端的完整源代码。
我创建了一个示例应用程序,它在普通 RDBMS 列中存储了用户的基本数据,例如他们的姓名、联系人_号码、安全_号码和国家/地区。收集的其他详细信息很少,适用于一个国家以及他们所属的专业。以下是不同国家和专业的数据如何保存。为了检查可行性,我包含了纯字符串、布尔值、数字、字符串数组和一个复杂对象。因此,这将危及所有用例,并且可以针对它们运行选择查询以查看其工作原理。

我已经将数据加载到表中,大约 400 万个数据分布在不同的国家和不同的行业。
使用 Json 数据进行搜索的类型:
可以对 JSONB 数据执行多种类型的查询,例如属性、包含、存在和特定 JSONB 函数以提取路径或提取值......
让我们看看如何在 JSONB 上查询不同数据类型的数据。
Query 1 : (On String) 数据完全匹配让我们在 UserDetails 数据集中查询职业 u003d Farmer。
Query 2 : (On String) 数据通配符匹配
像“%Farm%”这样的职业
Query 3 : (On number) 家庭成员的数量
Query 4 : (On number) 查找范围内的家庭成员
Query 5 : (on Boolean) Find if any users has Disability
Query 6 : (On Array of Strings/Object) Find Exact match:
备用联系人号码,它们是字符串数组并与确切数据匹配。
对于上述查询,没有结果。但是我们有表格中的数据。原因是我们不能像这样查询数组类型的精确匹配。
其他方法 :
1.使用JSONB函数包含,但它会返回true或false而不是结果集。可以对其进行调整以返回结果集。
- 调整上述查询,使用like 运算符而不是“u003d”,即使它是完全匹配的。
返回结果所花费的时间更多,因为它不是可以工作的三元组索引,而是完全匹配。 Trigram 索引不会在这里受益。
3\。使用属性方式作为搜索条件。
查询 7:(字符串数组)→ 通配符匹配
这里我们不能使用属性方式来包含。我们既可以使用 JSONB contains 函数,也可以使用正常的方式来搜索带有 trigram 索引的通配符。还没有使用索引。
您可以看到 like 运算符在与通配符搜索完全匹配的情况下表现如何。
查询 8:日期/时间戳查询 → 完全匹配
由于我们有出生日期属性,我们将对此进行搜索。
查询 9:在日期/时间戳查询 → 在范围上
Query 10: On Object → 查询作为内部子节点的“info”对象,看看谁有crop为“Corn”。
查询 11:对象 → 作物为“玉米”,农场规模在 2-3 之间。
请注意执行时间是 44.733 毫秒,相当少。但是如果我们使用属性方式,我们可以进一步减少时间。
JSONB 性能:
在本节以上的所有查询中,没有使用任何索引,并且在 4M 数据上的性能相对较好。如果我们想提高大型数据集的性能怎么办。
-
为了改进对大型数据集的查询,我们必须在每次搜索中定义适当的搜索条件参数,我们必须在查询中包含许多需要的属性。 (这对于 JSONB 或普通查询集也是一样的)。
-
通过使用索引,我们可以提高性能。
3.带隔断。
让我们在这里讨论索引,因为我们经常使用分页来获取结果,最终我们会在偏移量和总数中获取实际数据(这本质上是顺序的。在大型数据集上,这可能是一个瓶颈)。
JSONB 和索引
当我们使用 JSONB 的 ->> 操作符时,PostgreSQL 可以使用 B-tree 或 Hash 索引来处理操作。 ->> 运算符以文本格式返回指定属性的值。 PostgreSQL 可以将文本结果的索引用作比较操作数。 GIN 索引可由 GIN JSONB 运算符类使用。
GIN JSONB 运算符类
默认操作符类 jsonb_ops 支持存在操作符(?、?&、?|)和包含操作符(@>)。而 jsonb_path_ops 只支持包含操作符。因此 GIN 索引只能搜索具有特定键或键值的。[PostgreSQL Doc : jsonb operator]
我用几种方法对4M数据进行了测试并得出了结论。
BTREE:
CREATE INDEX idx_btree_profession ON user_details USING BTREE ((details->>'profession'));CREATE INDEX idx_btree_profession_hash ON user_details USING HASH((details->>'profession') );---------------------------------------------------------- ---------------------SELECT count(*) FROM user_details WHERE details->>'profession' u003d 'Farmer';
SELECT count(*) FROM user_details WHERE details->>'profession' u003d 'Farmer'
或详情->>'职业' u003d '医生';
杜松子酒:
CREATE INDEX idx_gin_profession ON user_details USING GIN ((details->'profession'));------------------------- -------------------------------------------------------选择计数(*) FROM用户_details WHERE details->>'profession' u003d 'Farmer';
SELECT count(*) FROM user_details WHERE details->>'profession' u003d 'Farmer'
或详情->>'职业' u003d '医生';
带有 JSONB_OPS 的 GIN
CREATE INDEX idx_btree_profession ON user_details USING GIN (details jsonb_ops);CREATE INDEX idx_btree_profession ON user_details USING GIN (details jsonb_path_ops);------- -------------------------------------------------- -----------SELECT count(*) FROM user_details WHERE details @> '{"profession" : "Farmer"}';
SELECT count(*) FROM user_details WHERE details @> '{"profession" : "Farmer"}'
或详情@> '{"profession" : "Doctor"}';
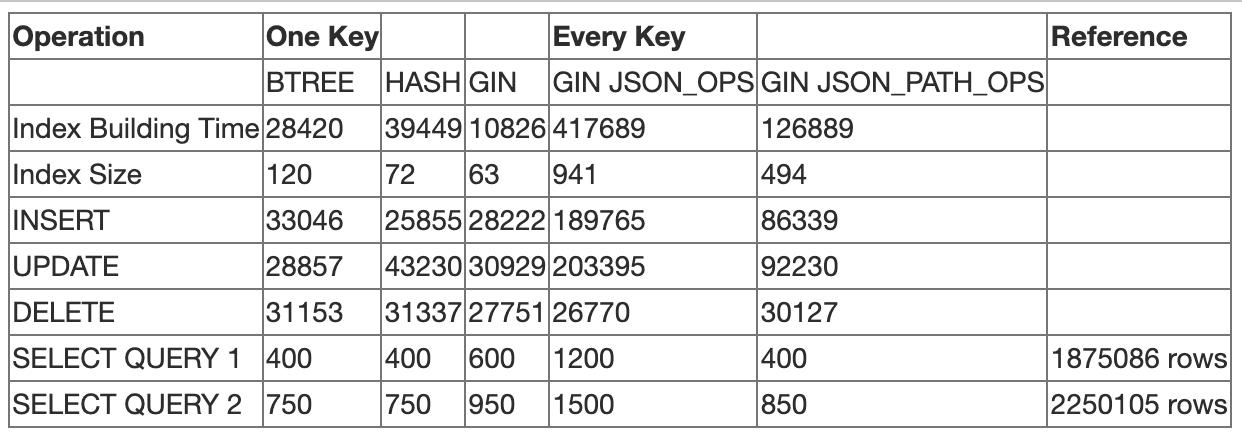
根据上面的结果,BTREE 在单个属性的搜索中表现最好,Gin 索引在构建时间和索引大小方面都表现出色。 Jsonb_path_ops 在搜索每一个属性方面的表现都比 jsonb_ops 好。虽然 jsonb_path_ops 是所有属性的索引,但是相比单键索引,它表现得很好,而且 jsonb_path_ops 的索引大小和构建时间也不够好,因为它有 40 多个属性。
结论
BTREE 索引在单个属性的索引搜索中表现最好。 HASH 索引也表现不错,但不提供 WAL (Write Ahead Log) 是异常终止的关键。 GIN 索引在使用单个索引索引所有属性方面具有优势,但是在索引单个键方面的性能比 BTREE 和 HASH 索引要差。
因此,在选择 JSONB 类型的索引时,如果索引搜索几个预定的属性,BTREE 是最佳选择,但是,如果索引搜索任意属性,则首选 GIN 索引。在使用 GIN 索引的情况下,使用 jsonb_path_ops 作为一个类来检查它是否简单地有一个 key-value,但是为了检查不仅有一个 key-value 还检查 key 的存在,最好使用jsonb_ops。
非结构化数据的应用端验证
当我们处理非结构化数据时,我们必须从应用程序端或数据库处理它,以便将适当的数据插入表中,以使数据保持一致。
验证 JSON 结构:
众所周知,有一种方法可以使用 JSON Schema 验证 JSON 文本。https://json-schema.org/。借助模式,我们可以验证数据。
-
数据库端:不建议在数据库端进行模式验证,因为如果对现有结构进行添加不会有问题,但如果有删除则迫使我们迁移然后添加数据。添加越来越多的验证会变得很麻烦。即使在无 SQL 数据库中,我们也没有在数据库端进行模式验证。
-
应用端: 是应用程序在插入数据库时处理的一种应用程序逻辑。我们必须确保当从后端直接写入数据库时,我们必须处理它。
如何在 Java/Spring 中验证 JSON Schema:
可以为我们做的可用库很少。它们可以与 spring 集成,或者我们也可以在数据实际存在时执行按需验证。
请参阅下面我为 Professions 属性实现的架构。可以编写越来越复杂的模式来验证 JSON 字符串。
除此之外,我们还可以在应用程序逻辑中注入一个逻辑框架(更具体到数据)

PostgreSQL社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 1
1- 0



 已为社区贡献19904条内容
已为社区贡献19904条内容

所有评论(0)