使用 Kubebuilder 开始使用 Kubernetes API
Kubebuilder 是我们的朋友,它将帮助我们搭建 Kubernetes API 项目。我们将介绍一些简短的概念,然后我们将逐步介绍如何使用 Kubebuilder 创建 Kubernetes API。
注意:按顺序执行每一步,我学到了很难的方法,如果你跳来跳去,Kubebuilder 可能会很挑剔。
关键概念
Kubernetes 中的 API(应用程序编程接口)
API 允许您与特定服务或 UI 进行交互。在 Kubernetes 上下文中,API 允许我们向 Kubernetes 集群添加功能。
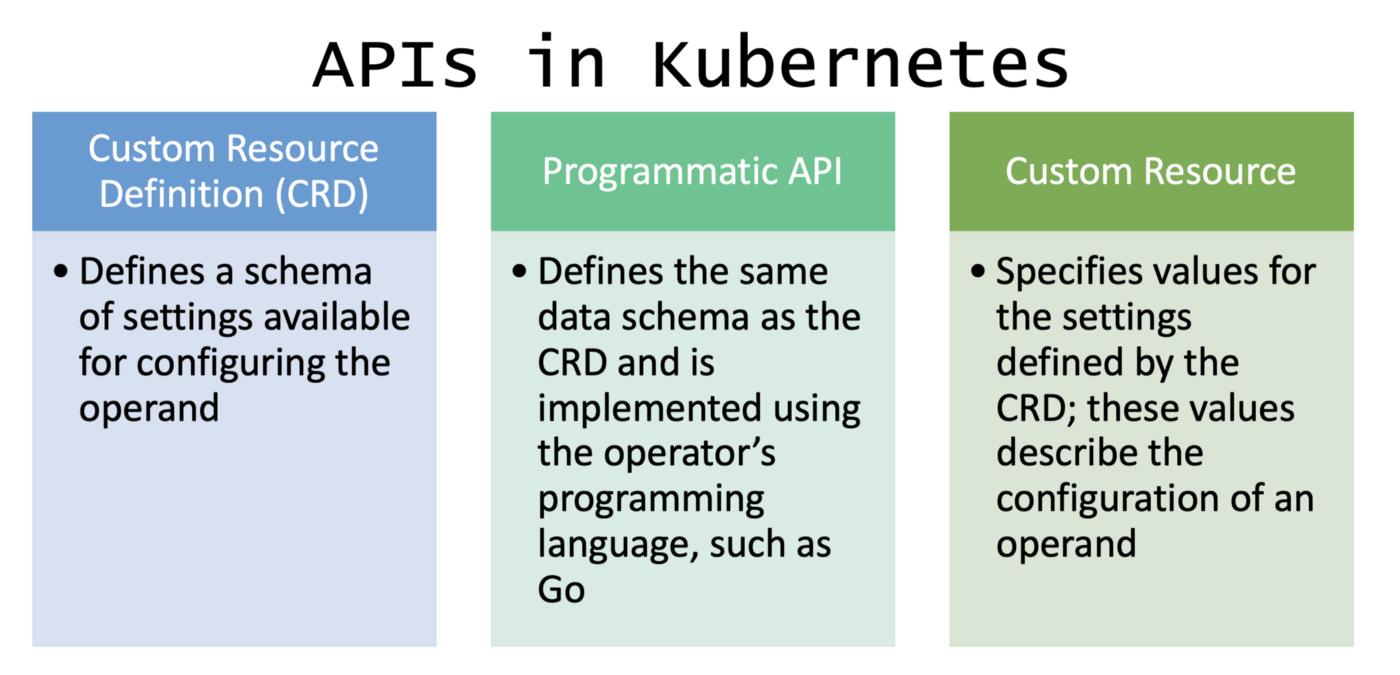
https://translate.google.com/translate?hl=en&sl=auto&tl=zh&u=https://kubernetes.io/docs/reference/using-api/api-concepts/
控制器
每个控制器实现一个控制循环,通过 API 服务器监视集群的共享状态,并根据需要进行更改,始终将其恢复到所需的状态。
将控制器想象成中央空调恒温器,如果天气炎热,您将温度设置为 65 度,并且一整天,热水瓶始终将房间温度恢复到 65 度。

调和器
在每个控制器中,协调器是由集群事件触发的逻辑。 reconcile 函数采用对象的名称并返回状态是否与所需状态匹配。
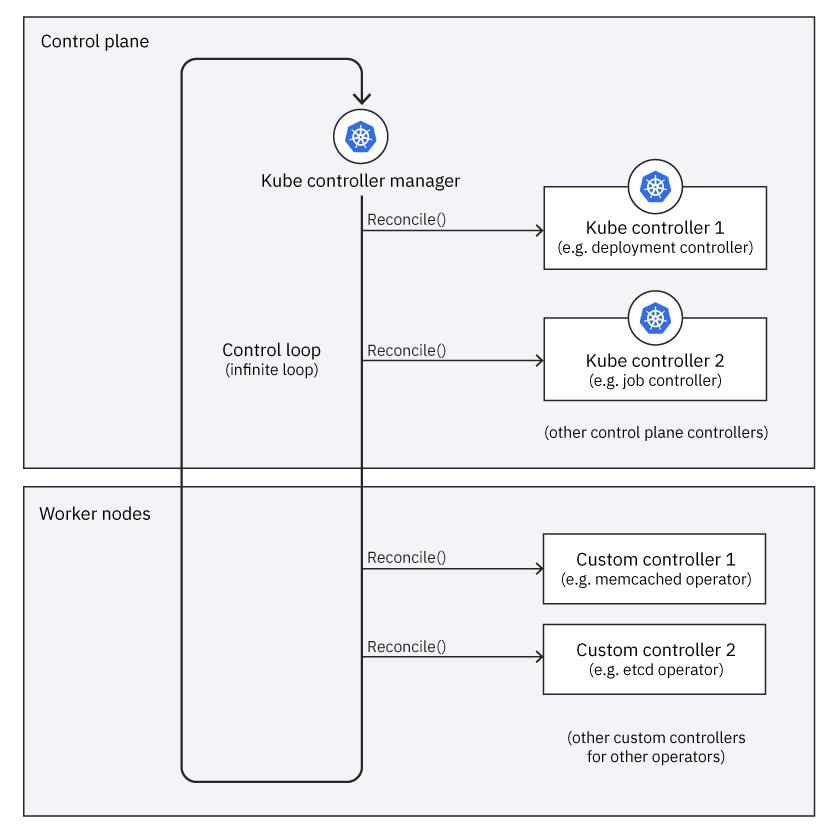
控制平面
Kubernetes 有一个控制平面,它是一个编排层,它公开 API 和接口以定义、部署和管理容器的生命周期。 Kubernetes 控制器运行在控制平面中,操作员的控制器运行在工作节点中。
控制平面中的组件之一是公开这些 API 的 API 服务器。控制平面中的另一个组件是运行控制器进程的控制器管理器,每个控制器作为管理集群的一部分具有特定的职责。
搭建环境
你需要:
-
去
-
码头工人
-
丑
-
Kubectl
-
自定义
-
立方体生成器
-
Go 编程 IDE
去
从https://go.dev/dl/下载合适的 Go 安装程序。您必须有 1.17,在本文发布时不支持 1.18。
码头工人
从https://docs.docker.com/get-docker/下载合适的 Docker 安装程序
** Minikube **
从https://minikube.sigs.k8s.io/docs/start/下载合适的 Minikube 安装程序
kubectl
在页面https://kubernetes.io/docs/tasks/tools/上找到相应的安装说明。您将需要处理 kubectl 文件夹权限。
自定义
在页面https://kubectl.docs.kubernetes.io/installation/kustomize/上找到相应的安装说明
Kubebuilder
运行以下命令安装 Kubebuilder,您可以在页面https://book.kubebuilder.io/quick-start.html找到说明。
# 下载 kubebuilder 并在本地安装。
curl -L -o kubebuilder https://go.kubebuilder.io/dl/latest/$(go env GOOS)/$(go env GOARCH)
chmod +x kubebuilder && mv kubebuilder /usr/local/bin/
1.初始化项目
为此示例创建一个项目文件夹,我们将使用我们的 CronJob 项目创建 CronJob Kubernetes API。
mkdir cronjob && cd cronjob
现在使用以下命令使用 kubebuilder 初始化文件夹:
kubebuilder init --domain cronjob.kubebuilder.io --repo cronjob.kubebuilder.io/project
运行初始化程序后,您将看到生成了 Dockerfile、Makefile、main go 程序和 config 文件夹。
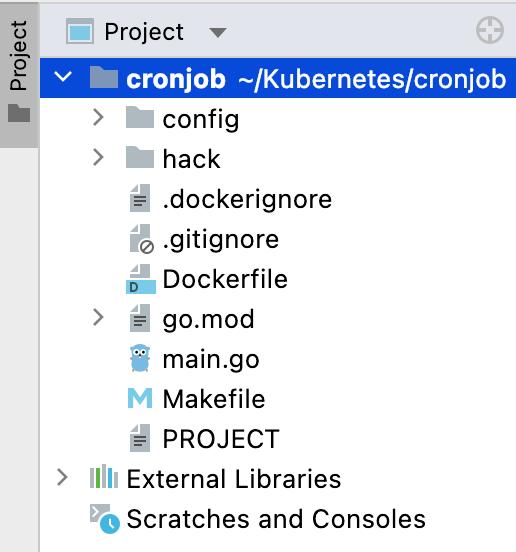
config 文件夹包含大量 YAML 文件,如下所示。默认具有用于启动控制器的 Kustomize 基础。 Manager 将控制器作为集群中的 pod 启动。 Prometheus 处理项目的指标。 RBAC 处理在他们自己的服务帐户下运行控制器所需的权限。
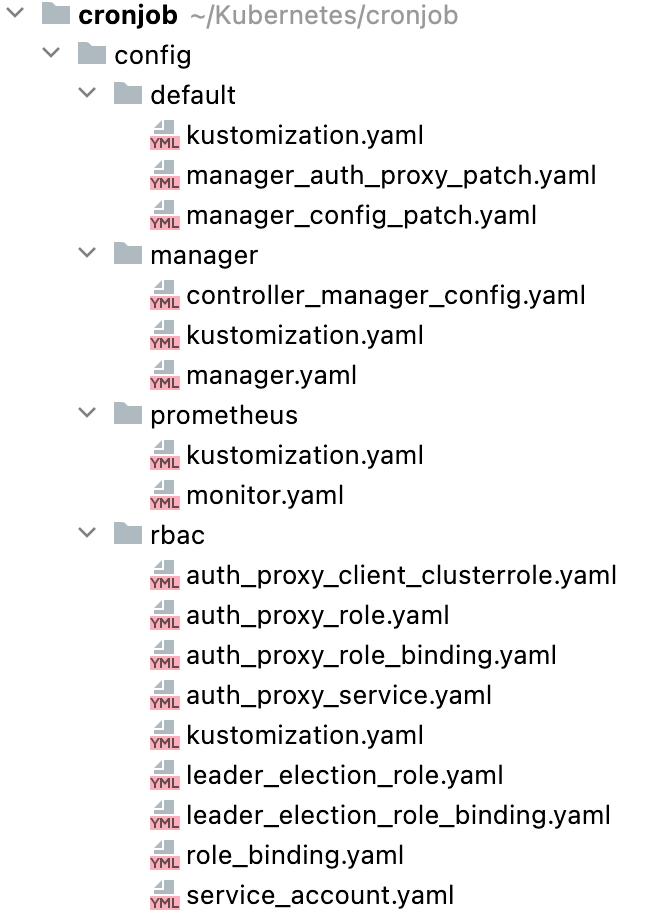
检查点:https://github.com/moza88/cronjob-kubebuilder-tutorial/tree/1_init_kubebuilder
2.创建 API
现在我们将通过运行来创建我们的 API:
kubebuilder 创建 api --group batch --version v1 --kind CronJob
为“创建资源”和“创建控制器”选择 Y。
运行上面的命令将生成一个 API、控制器和 crd(在 config 下)文件夹。您将找到我们的 Kind CronJob (cronjob_types.go)。每个 API 组版本都包含一种或多种 API 类型,我们称之为 Kinds。
运行你的脚手架项目
构建项目
如果您打开 Make 文件 (Makefile),您将看到您为该项目运行的所有命令。第一步是make all这将构建项目。
生成 Controller-Gen 和 Manager 脚本
运行make manifests以生成 CRD(自定义资源定义)、webhook 配置和集群角色,现在您应该会看到带有 controller-gen 和 manager 的 bin 文件夹。
! zoz100078](https://devpress-image.s3.cn-north-1.jdcloud-oss.com/a/30d9343721_1*YweKrgN1z_ymStzxAvo9mQ.jpg)
然后运行make generate,这将生成包含deepCopy、deepCopyInto和deepCopyObject的代码。
注意:如果您不运行make all ,您将不会在 bin 文件夹中获得管理器脚本。
编译运行
让我们确保一切都可以在您的主机上启动并运行。您需要建立本地 Kubernetes 集群,您可以使用 Minikube 或 Kind,在本练习中我们使用 Minikube。
在单独的终端中运行命令minikube start。
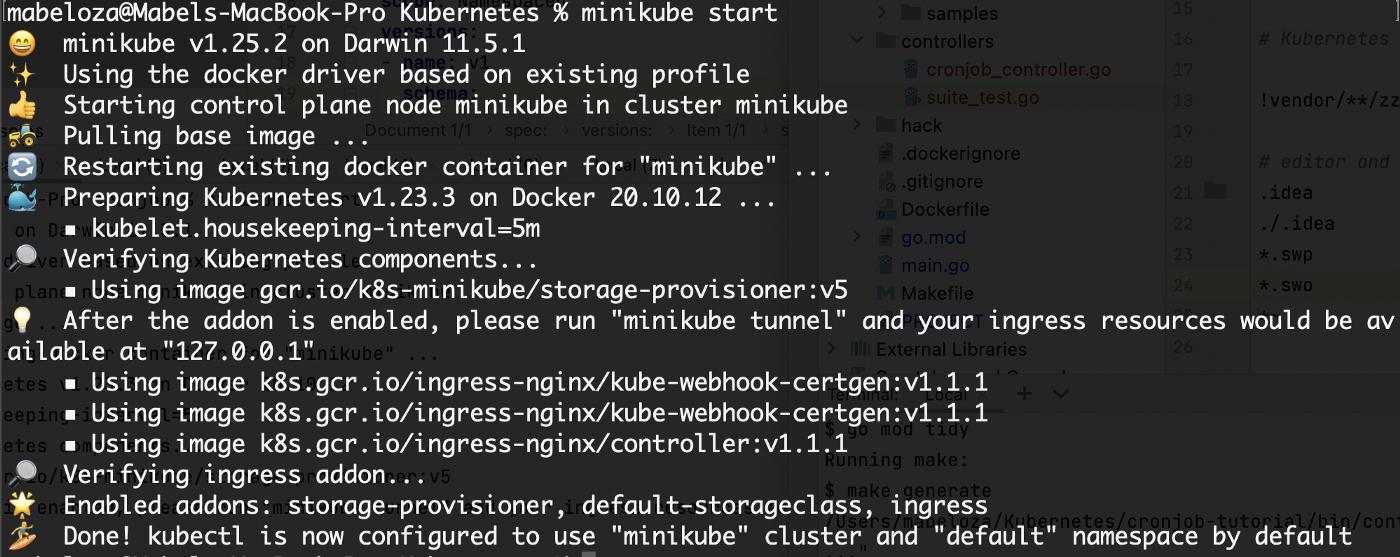
要检查您的集群是否已启动并正常运行,您可以运行kubectl get po -A。
如果您的集群未启动,您将出现如下错误:

现在您的本地集群已启动并运行,让我们构建并运行我们的项目。运行make build运行带有 main.go 文件的 bin 文件夹中的管理器。运行make run将运行该项目。

现在您可以在http://localhost:8080/metrics找到 Prometheus 指标。
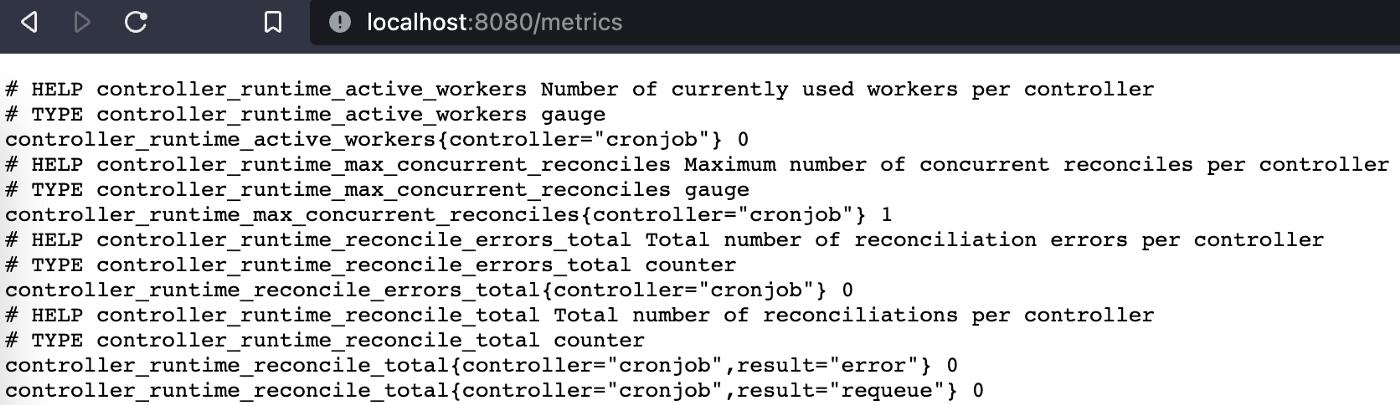
您将在http://localhost:8081/healthz找到 readyz 状态,在http://localhost:8081/readyz找到就绪状态。我知道这些 URL,因为它们在 main.go 文件的下面几行中说明:
if err :u003d mgr.AddHealthzCheck("healthz", healthz.Ping);错误!u003d无{
setupLog.Error(err, "无法设置健康检查")
os.Exit(1)
}
if err :u003d mgr.AddReadyzCheck("readyz", healthz.Ping);错误!u003d无{
setupLog.Error(err, "无法设置就绪检查")
os.Exit(1)
}
CronJob 种类 (cronjob_types.go)
让我们通过添加一个安排 cron 作业和模板作业的部分来创建我们的 cron 作业。打开 ~/api/v1/cronjob_types.go 文件并开始编写以下代码:
依赖关系
以下是 cronjob_types 所需的依赖项:
进口 (
batchv1beta1 "k8s.io/api/batch/v1beta1" corev1 "k8s.io/api/core/v1" metav1 **"k8s.io/apimachinery/pkg/apis/meta/v1"
**)
Cron 作业规范
我们将在type CronJobSpec struct中定义 CronJob 的所需状态,您可以删除注释但保留// + comment,因为它是控制器工具在生成 CRD 清单时将使用的元数据。
type CronJobSpec struct { //+kubebuilder:validation:MinLengthu003d0 Schedule string `json:"schedule"`
_//+kubebuilder:validation:MinLengthu003d0
// +可选_ StartingDeadlineSeconds *int64 `json:"startingDeadlineSeconds,omitempty"`// +可选
ConcurrencyPolicy ConcurrencyPolicy `json:"concurrencyPolicy,omitempty"`// +optional Suspend *bool `json:"suspend,omitempty"`
JobTemplate batchv1beta1.JobTemplateSpec `json:"jobTemplate"`//+kubebuilder:validation:Minimumu003d0 // +optional SuccessfulJobHistoryLimit *int32 `json:"successfulJobHistoryLimit,omitempty"`
_//+kubebuilder:validation:Minimumu003d0
// +optional_ FailedJobsHistoryLimit *int32 `json:"failedJobsHistoryLimit"`}
并发策略
在这里,我们通过添加以下行来处理并发策略:
_// +kubebuilder:validation:Enumu003dAllow;Forbid;Replace
_type ConcurrencyPolicy 字符串
常量 (
// AllowConcurrent 允许 CronJobs 并发运行。 AllowConcurrent ConcurrencyPolicy u003d "Allow" _// ForbidCurrent ForbidConcurrent 禁止并发运行,如果上一个则跳过下一个运行
// 还没有完成。_ ForbidCurrent ConcurrencyPolicy u003d "Forbid" // ReplaceConcurrent ReplacementConcurrent 取消当前正在运行的作业并用新的作业替换它。 ReplaceConcurrent ConcurrencyPolicy u003d ** “代替”
**)
Cron 作业状态
现在我们需要设计保持观察状态的状态。
类型 CronJobStatus 结构 {
_
// +可选
_ Active []corev1.ObjectReference `json:"active,omitempty"` // +optional LastScheduleTime *metav1.Time `json:"LastScheduleTime,omitempty"`}
Cron 作业模式
键入 CronJob 结构 {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
规范 CronJobSpec `json:"spec,omitempty"`
状态 CronJobStatus `json:"status,omitempty"`
}
Cron 作业列表
// CronJobList 包含一个 CronJob 列表
类型 CronJobList 结构 {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
项目[]CronJob `json:"items"`
}
然后我们通过将 CronJob 和 CronJobList 注册到我们的 SchemaBuilder 来初始化它们
函数初始化(){
SchemeBuilder.Register(&CronJob{}, &CronJobList{})
}
cron job\types.to 文件的最终产品应如下所示:
控制器(cronjob_controller.go)
在这里,控制器的工作是:
1.加载命名的CronJob
2.列出所有活跃的工作,并更新状态
3.清理旧工作
4.检查作业是否暂停
-
获取下一次预定运行
-
如果按计划运行新作业(如果它没有超过截止日期并且被并发策略阻止)
-
当我们看到正在运行的作业或下一次计划运行时重新排队
依赖
此控制器将使用以下依赖项,最后一个 batchv1 是对我们之前构建的 API 的引用(名称可能会因选择的包名称而异):
进口 (
“语境”
“fmt”
“种类”
“时间”
“github.com/robfig/cron”
kbatch "k8s.io/api/batch/v1"
corev1 "k8s.io/api/core/v1"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" "k8s.io/apimachinery/pkg/runtime"
参考“k8s.io/client-go/tools/reference”
ctrl “sigs.k8s.io/controller-runtime” “sigs.k8s.io/controller-runtime/pkg/client”
“sigs.k8s.io/controller-runtime/pkg/log”
batchv1 **“tutorial.cronjob.io/project/api/v1”
**)
时钟
Cron Job 程序中最重要的部分是时钟,下面我们创建时钟。
_/*
我们将模拟时钟,以便在测试时更容易及时跳转,
“真正的”时钟只调用 `time.Now`。
*/
_type realClock struct{}
func (_ realClock) Now() time.Time { return time.Now() }
_// 时钟知道如何获取当前时间。
// 它可以用来伪造测试时间。
_类型时钟接口 {
现在()时间。时间
}
// +kubebuilder:docs-gen:collapseu003dClock
现在我们将时钟添加到我们的 Cron Job Reconciler 中:
_// CronJobReconciler 协调一个 CronJob 对象
_type CronJobReconciler struct {
客户.客户
方案 *runtime.Scheme
钟
}
RBAC 权限
由于我们现在正在创建和管理作业,因此我们添加了 RBAC 权限。
_//+kubebuilder:rbac:groupsu003dbatch.tutorial.cronjob.io,resourcesu003dcronjobs,verbsu003dget;list;watch;create;update;patch;delete
//+kubebuilder:rbac:groupsu003dbatch.tutorial.cronjob.io,resourcesu003dcronjobs/status,verbsu003dget;update;patch
//+kubebuilder:rbac:groupsu003dbatch.tutorial.cronjob.io,resourcesu003dcronjobs/finalizers,verbsu003dupdate
**//+kubebuilder:rbac:groupsu003dbatch,resourcesu003djobs,verbsu003dget;list;watch;create;update;patch;delete
//+kubebuilder:rbac:groupsu003dbatch,resourcesu003djobs/status,verbsu003dget_**
注意:确保组名与您的组名匹配,您可以在 groupversion_info.go 文件中找到组名。
GroupVersion u003d schema.GroupVersion{组:“batch.tutorial.cronjob.io”,版本:“v1”}
协调器逻辑
协调逻辑的第一步是创建一个变量来注释计划时间。
曾是 (
scheduleTimeAnnotation u003d **"batch.tutorial.kubebuilder.io/scheduled-at"
**)
现在让我们进入我们的协调函数,这是所有动作发生的地方。我们的 reconciler 函数看起来像这样,如果您将项目命名为其他名称,那么您将看不到 CronJobReconciler,它将是其他名称。
func (r *CronJobReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
要跟踪将要发生的事情,请在 reconcile 函数下方初始化一个记录器
日志 :u003d log.FromContext(ctx)
- 按名称加载 CronJob
我们将获取我们在 API (cronjob_types.go) 中创建的 CronJob 结构并将其放入名为 cronJob 的变量中。如果我们无法获取它,我们有一个适当的方法来处理它。
**var cron Job 批处理 1.CronJob
**if err :u003d r.Get(ctx, req.NamespacedName, &cronJob);错误!u003d无{
log.Error(err, "无法获取 CronJob")
返回 ctrl.Result{},client.IgnoreNotFound(err)
}
2\。列出所有活动作业并更新状态
**var childJobs kbatch.JobList
**if err :u003d r.List(ctx, &childJobs, client.InNamespace(req.Namespace), client.MatchingFields{jobOwnerKey: req.Name});错误!u003d无{
log.Error(err, "无法列出子作业")
返回 ctrl.Result{},错误
}
查找工作的活动列表
var activeJobs []*kbatch.Job
是成功的 Jobs []*batch.Job
var failedJobs []*kbatch.Job
var mostRecentTime *time.Time // 查找最后一次运行,以便我们可以更新状态
如果作业的“完成”或“失败”条件标记为真,则将其标记为“完成”。
isJobFinished :u003d func(job *kbatch.Job) (bool, kbatch.JobConditionType) {
for _, c :u003d range job.Status.Conditions {
if (c.Type u003du003d kbatch.JobComplete || c.Type u003du003d kbatch.JobFailed) && c.Status u003du003d corev1.ConditionTrue {
return true, c.Type
}
}
返回_false_, **""
**}
// +kubebuilder:docs-gen:collapseu003disJobFinished
从之前添加的注解中提取预定时间(记住reconcile函数之前的scheduledTimeAnnotation)
getScheduledTimeForJob :u003d func(job *kbatch.Job) (*time.Time, error) {
timeRaw :u003d job.Annotations[scheduledTimeAnnotation] if len(timeRaw) u003du003d 0 {
返回零,零
}
timeParsed, err :u003d time.Parse(time.RFC3339, timeRaw) if err !u003d nil {
返回零,错误
}
返回 &timeParsed,无
}
// +kubebuilder:docs-gen:collapseu003dgetScheduledTimeForJob
运行作业列表、活动、失败和完成,并相应地填充我们的活动、失败和成功标记。使用预定时间并使用它来计算最近的时间。然后取最近的时间算出最后的预定时间
for i, job :u003d range childJobs.Items {
_, finishedType :u003d isJobFinished(&job)
switch finishedType {
case "": _// 正在进行的_activeJobs u003d append(activeJobs, &childJobs.Items[i])
case kbatch.JobFailed:
failedJobs u003d append(failedJobs, &childJobs.Items[i])
case kbatch.JobComplete:
successfulJobs u003d append(successfulJobs, &childJobs.Items[i])
}
_// 我们会将启动时间存储在注释中,因此我们将从
// 活动作业本身。_ scheduledTimeForJob, err :u003d getScheduledTimeForJob(&job)
如果 错误!u003d nil {
log.Error(err, "unable to parse schedule time for child job", "job", &job)
继续 }
如果 scheduleTimeForJob !u003d nil {
如果 mostRecentTime u003du003d nil {
mostRecentTime u003d scheduleTimeForJob
} else if mostRecentTime.Before(*scheduledTimeForJob) {
mostRecentTime u003d scheduleTimeForJob
}
}
}if mostRecentTime !u003d nil {
cronJob.Status.LastScheduleTime u003d &metav1.Time{时间:*mostRecentTime}
} 别的 {
cronJob.Status.LastScheduleTime u003d nil
}
cronJob.Status.Active u003d nil
for _, activeJob :u003d range activeJobs {
jobRef, err :u003d ref.GetReference(r.Scheme, activeJob)
如果 错误!u003d nil {
log.Error(err, "无法引用活动作业", "作业", activeJob)
继续 }
cronJob.Status.Active u003d append(cronJob.Status.Active, *jobRef)
}
记录我们观察到的工作数量。
log.V(1).Info("job count", "active jobs", len(activeJobs), "successful jobs", len(successfulJobs), "failed jobs", len(failedJobs))
更新状态
如果 err :u003d r.Status().Update(ctx, &cronJob);错误!u003d无{
log.Error(err, "无法更新 CronJob 状态")
返回 ctrl.Result{},错误
}
3\。根据历史限制清理旧作业
_// 注意:删除这些是“尽力而为”——如果我们在某个特定的问题上失败了,
// 我们不会为了完成删除而重新排队。
_if cronJob.Spec.FailedJobsHistoryLimit !u003d nil {
sort.Slice(failedJobs, func(i, j int) bool {
如果 failedJobs[i].Status.StartTime u003du003d nil {
返回 failedJobs[j].Status.StartTime !u003d nil
}
返回 failedJobs[i].Status.StartTime.Before(failedJobs[j].Status.StartTime)
})
for i, job :u003d range failedJobs {
如果 int32(i) >u003d int32(len(failedJobs))-*cronJob.Spec.FailedJobsHistoryLimit {
休息 }
if err :u003d r.Delete(ctx, job, client.PropagationPolicy(metav1.DeletePropagationBackground)); client.IgnoreNotFound(err) !u003d nil {
log.Error(err, "unable to delete old failed job", "job", job)
} 别的 {
log.V(0).Info("已删除旧的失败作业", "作业", 作业)
}
}
}
4\。检查我们是否被暂停
如果 cronJob.Spec.Suspend !u003d nil && *cronJob.Spec.Suspend {
log.V(1).Info("cronjob 暂停,跳过")
返回 ctrl.Result{},无
}
5\。获取下一次计划运行
getNextSchedule :u003d func(cronJob *batchv1.CronJob, now time.Time) (lastMissed time.Time, next time.Time, err error) {
sched, err :u003d cron.ParseStandard(cronJob.Spec.Schedule)
如果 错误!u003d nil {
return time.Time{}, time.Time{}, fmt.Errorf("Unparseable schedule %q: %v", cronJob.Spec.Schedule, err)
}
var earlyTime time.Time
if cronJob.Status.LastScheduleTime !u003d nil {
最早时间 u003d cronJob.Status.LastScheduleTime.Time
} 别的 {
最早时间 u003d cronJob.ObjectMeta.CreationTimestamp.Time
}
如果 cronJob.Spec.StartingDeadlineSeconds !u003d nil {
// 控制器不会安排低于此点的任何内容 schedulingDeadline :u003d now.Add(-time.Second * time.Duration(*cronJob.Spec.StartingDeadlineSeconds))
if schedulingDeadline.After(earliestTime) {
最早时间 u003d 调度截止日期
}
}
if earlyTime.After(now) {
return time.Time{}, sched.Next(now), nil
}
开始:u003d 0
for t :u003d sched.Next(earliestTime); !t.After(现在); t u003d sched.Next(t) {
lastMissed u003d t 开始++
如果开始 > 100 {
return time.Time{}, time.Time{}, fmt.Errorf("错过的开始时间太多 (> 100)。设置或减少 .spec.startingDeadlineSeconds 或检查时钟偏差。")
}
}
return lastMissed, sched.Next(now), nil
}
// +kubebuilder:docs-gen:collapseu003dgetNextSchedule
6\。如果新作业按计划运行,没有超过截止日期,并且被并发策略阻止
**missedRun, nextRun, err :u003d getNextSchedule(&cronJob, r.Now())
**如果错误!u003d nil {
log.Error(err, "unable to figure out CronJob schedule") return ctrl.Result{}, nil
}
scheduledResult :u003d ctrl.Result{RequeueAfter: nextRun.Sub(r.Now())} log u003d log.WithValues("now", r.Now(), "next run", nextRun)
_/*
6:如果新作业按计划运行,没有超过截止日期,并且没有被我们的并发策略阻止
如果我们错过了一次运行,并且我们仍在开始运行的最后期限内,我们将需要运行一项工作。
*/
_**如果错过Run.IsZero() {
** log.V(1).Info("没有即将到来的预定时间,睡到下一个")
返回预定结果,无
}
_// 确保我们开始运行还不算太晚
_log u003d log.WithValues("当前运行",missedRun)
**tooLate :u003d _false
_if cronJob.Spec.StartingDeadlineSeconds !u003d nil {
tooLate u003dmissRun.Add(time.Duration(*cronJob.Spec.StartingDeadlineSeconds)* time.Second).Before(r.Now())**
}
**如果太晚{
** log.V(1).Info("错过了上次运行的开始截止日期,一直睡到下一次")
返回预定结果,无
}**如果 cronJob.Spec.ConcurrencyPolicy u003du003d batchv1.ForbidConcurrent && len(activeJobs) > 0 {
** log.V(1).Info("并发策略阻止并发运行,跳过", "num active", len(activeJobs))
返回预定结果,无
}
**如果 cronJob.Spec.ConcurrencyPolicy u003du003d batchv1.ReplaceConcurrent {
对于 _, activeJob :u003d range activeJobs {
** _// 我们不关心作业是否已经被删除
_ if err :u003d r.Delete(ctx, activeJob, client.PropagationPolicy(metav1.DeletePropagationBackground)); client.IgnoreNotFound(err) !u003d nil { log.Error(err, "unable to delete active job", "job", activeJob)
返回 ctrl.Result{},错误
}
}
}
根据 CronJob 的模板构建作业
**constructJobForCronJob :u003d func(cronJob *batchv1.CronJob, scheduledTime time.Time) (*kbatch.Job, error) {
名称 :u003d fmt.Sprintf("%s-%d", cronJob.Name, scheduleTime.Unix())**
工作 :u003d &kbatch.Job{
对象元:metav1.ObjectMeta{
标签:make(map[string]string),
注释:make(map[string]string),
姓名:姓名,
命名空间:cronJob.Namespace,
},
规范:*cronJob.Spec.JobTemplate.Spec.DeepCopy(),
}
**for k, v :u003d range cronJob.Spec.JobTemplate.Annotations {
作业.注解[k] u003d v
}
job.Annotations[scheduledTimeAnnotation] u003d scheduledTime.Format(time.RFC3339)
对于 k, v :u003d 范围 cronJob.Spec.JobTemplate.Labels {
工作.标签[k] u003d v
}
if err :u003d ctrl.SetControllerReference(cronJob, job, r.Scheme);错误!u003d无{
返回零,错误
}**
返工,无
}
// +kubebuilder:docs-gen:collapseu003dconstructJobForCronJob_// 实际完成工作...
_**job, err :u003dconstructJobForCronJob(&cronJob,missRun)
**如果错误!u003d nil {
log.Error(err, **"**无法从模板构造作业")
_// 在我们对规范进行更改之前不要打扰重新排队_return scheduledResult, nil
}
_// ...并在集群上创建它
_**if err :u003d r.Create(ctx, job);错误!u003d无{
** log.Error(err, "unable to create Job for CronJob", "job", job)
返回 ctrl.Result{},错误
}
log.V(1).Info("为 CronJob 运行创建的作业", "job", job)
7\。当我们看到正在运行的作业或下一次计划运行时重新排队
返回预定结果,无
设置
曾是 (
jobOwnerKey u003d ".metadata.controller"
apiGVStr u003d batchv1.GroupVersion.String()
)
**func (r *CronJobReconciler) SetupWithManager(mgr ctrl.Manager) 错误 {
** // 设置一个真正的时钟,因为我们不在测试中 **if r.Clock u003du003d nil {
r.Clock u003d realClock{}
}**
如果 err :u003d mgr.GetFieldIndexer().IndexField(context.Background(), &kbatch.Job{}, jobOwnerKey, func(rawObj client.Object) []string {
// 获取作业对象,提取所有者... **job :u003d rawObj.(*kbatch.Job)
所有者 :u003d metav1.GetControllerOf(job)**
如果所有者 u003du003d 无 {
返回零
}
_// ...确保它是一个 CronJob ...
_ if owner.APIVersion !u003d apiGVStr || owner.Kind !u003d "CronJob" { return nil
}
_// ...如果是,则返回它_return []string{owner.Name}
});错误!u003d无{
返回错误
}
返回 ctrl.NewControllerManagedBy(mgr)。
对于(&batchv1.CronJob{})。
欧文斯(& batch.Job{})。
完成(r)
}
现在你有了它,你已经完成了你的 API 和控制器。最后,您的所有 ~/controllers/cronjob_controller.go 应该看起来像下面的代码:
检查点:https://github.com/moza88/cronjob-kubebuilder-tutorial/tree/2_create_api
Webhook
现在我们要创建 admission webhook,有两种类型的 mutating 和 validating webhook。
变异的准入 webhook 在对象被创建或更新时对其进行变异,然后再存储它。
验证准入 webhook 在对象被创建或更新时验证它,然后再存储它。
! swz 100105 swz 100106 swz 100104
您可以通过运行以下命令轻松地为您的 webhook 创建组件:
kubebuilder 创建 webhook --group batch --version v1 --kind CronJob --defaulting --programmatic-validation
这将修改您的项目,例如创建 cronjob_webhook.go API、带有几个 yml 的 webhook 文件夹、certmanager 文件夹(在配置下),并编辑 main.go 文件以注册 webhook。
依赖
cronjob webhook API 将使用以下依赖项:
进口 (
“github.com/robfig/cron”
apierrors“k8s.io/apimachinery/pkg/api/errors”
“k8s.io/apimachinery/pkg/runtime”
“k8s.io/apimachinery/pkg/runtime/schema”
验证工具“k8s.io/apimachinery/pkg/util/validation”
“k8s.io/apimachinery/pkg/util/validation/field”
ctrl“sigs.k8s.io/controller-runtime”
logf "sigs.k8s.io/controller-runtime/pkg/log"
“sigs.k8s.io/controller-runtime/pkg/webhook”
)
为 webhook 设置记录器
var cronjoblog = logf.Log.WithName("cronjob-resource")
使用管理器设置 webhook。
func (r *CronJob) SetupWebhookWithManager(mgr ctrl.Manager) 错误 {
返回 ctrl.NewWebhookManagedBy(mgr)。
对于(r)。
完全的()
}
使用 webhook.Defaulter 为 CRD 设置默认值。 Default 方法将改变接收器,设置默认值。
var _ webhook.Defaulter u003d &CronJob{} func (r *CronJob) Default() {
cronjoblog.Info("default", "name", r.Name) if r.Spec.ConcurrencyPolicy u003du003d "" {
r.Spec.ConcurrencyPolicy u003d AllowConcurrent
}
如果 r.Spec.Suspend u003du003d nil {
r.Spec.Suspend u003d new(bool)
}
如果 r.Spec.SuccessfulJobsHistoryLimit u003du003d nil {
r.Spec.SuccessfulJobsHistoryLimit u003d new(int32)
*r.Spec.SuccessfulJobsHistoryLimit u003d 3
}
如果 r.Spec.FailedJobsHistoryLimit u003du003d nil {
r.Spec.FailedJobsHistoryLimit u003d new(int32)
*r.Spec.FailedJobsHistoryLimit u003d 1
}
}
通过处理创建、更新、删除验证来验证 CRD。
var _ webhook.Validator u003d &CronJob{}// ValidateCreate 实现 webhook.Validator,因此将为该类型注册一个 webhook
func (r *CronJob) ValidateCreate() 错误 {
cronjoblog.Info("validate create", "name", r.Name)return r.validateCronJob()
}// ValidateUpdate 实现了 webhook.Validator,因此将为该类型注册一个 webhook
func (r *CronJob) ValidateUpdate(old runtime.Object) error {
cronjoblog.Info("验证更新", "名称", r.Name)return r.validateCronJob()
}// ValidateDelete 实现了 webhook.Validator,因此将为该类型注册一个 webhook
func (r *CronJob) ValidateDelete() 错误 {
cronjoblog.Info("validate delete", "name", r.Name)// TODO(user):在删除对象时填写你的验证逻辑。
返回零
}
使用下面定义的 validateCronJobName 和 validateCronJobSpec 方法验证 CronJob 的名称和规范。
func (r *CronTab) 验证 Cron Job() 错误 {
var allErrs field.ErrorList
如果错误:u003d r.validateCronJobName();错误!u003d无{
警报 u003d 追加(警报,错误)
}
if error.validate CronJob Spec();错误!u003d无{
警报 u003d 追加(警报,错误)
}
如果 len(allErrs) u003du003d 0 {
返回零
}
return apierrors.NewInvalid(schema.GroupKind{Group: "batch.tutorial.kubebuilder.io", Kind: "CronJob"}, r.Name, allErrs)
}
使用 kubebuilder 验证标记来验证规范(以// +kubebuilder:validation为前缀)
func (r *CronTab) 验证 CronJob Spec() *field.Error {
// 来自 kubernetes API 机制的字段助手帮助我们很好地返回
// 结构化验证错误。
返回 validateScheduleFormat(
r.Spec.Schedule,
field.NewPath("spec").Child("schedule"))
}
使用 RobFigcron库确保 cronjob 计划格式正确。
//验证计划是否格式正确
func validateScheduleFormat(schedule string, fldPath *field.Path) *field.Error {
如果 _, err :u003d cron.ParseStandard(schedule);错误!u003d无{
return field.Invalid(fldPath, schedule, err.Error())
}
返回零
}
验证作业名称,其长度最多应为 52 个字符。
//验证 Cron 作业名称,它们最多只能是 52 个字符
func (r *CronTab) 验证 CronJob Name() *field.Error {
如果 len(r.ObjectMeta.Name) > validationutils.DNS1035LabelMaxLength-11 {
// 与所有 Kubernetes 对象一样,作业名称长度为 63 个字符
//(必须适合 DNS 子域)。 cronjob 控制器追加
// 创建时 cronjob (`-$TIMESTAMP`) 的 11 个字符后缀
// 一份工作。作业名称长度限制为 63 个字符。因此 cronjob
// 名称的长度必须 <u003d 63-11u003d52。如果我们不在这里验证这一点,
// 然后作业创建将在稍后失败。
return field.Invalid(field.NewPath("metadata").Child("name"), r.Name, "必须不超过 52 个字符")
}
返回零
}
// +kubebuilder:docs-gen:collapseu003d验证对象名称
如果您想深入了解 webhook,请查看 Slack 关于 webhook 的文章。
[
一个简单的 Kubernetes 准入 Webhook - Slack 工程
在向我们的 Kubernetes 计算平台添加最近的功能时,我们需要对基于......的新创建的 Pod 进行变异。
松弛工程
](https://slack.engineering/simple-kubernetes-webhook/)

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 0
0 0
0- 0



 已为社区贡献20439条内容
已为社区贡献20439条内容

所有评论(0)