在 Kubernetes 上使用 Jupyter Notebook 和 HDFS 运行 Spark
Kublr 和 Kubernetes 可以帮助您更轻松地部署和管理您喜爱的数据科学工具。 Hadoop分布式文件系统(HDFS)承担着存储大数据的重任; Spark 提供了许多强大的数据处理工具;而 Jupyter Notebook 是事实上的标准 UI,用于动态管理查询和结果的可视化。 Kublr 和 Kubernetes 使部署、扩展和管理它们变得容易——在生产中,并以一种稳定的方式使用故障转移机制和发生故障时的自动恢复。
我们创建了一个教程来演示为动态 Spark 工作负载设置和配置 Kubernetes 集群。这种配置的主要好处是降低成本和高性能。如何使用 Kubernetes 降低成本并提高性能?简短的回答是自动缩放可以降低成本,而关联规则可以提高性能。
Spark 优于 Hadoop 和 MapReduce,主要是因为它的内存重用和缓存。它的速度非常快,但只要您为工作人员提供足够的 RAM。当它在计算过程中将数据溢出到磁盘并保留在那里而不是内存时,获取查询结果会变得更慢。因此,有理由希望为 Spark 工作人员保留尽可能多的可用内存。但是,保持一个由裸机或虚拟机组成的静态数据中心具有足够的内存容量来运行最繁重的查询是非常昂贵的。由于需要峰值资源容量的查询并不频繁,因此尝试在静态集群中容纳最大所需容量将是资源和金钱的浪费。
更好的解决方案是创建一个动态的 Kubernetes 集群,该集群将按需使用所需的资源,并在不再需要繁重的工作时释放它们。这是一个很好的解决方案,可以涵盖许多常见情况,例如每天只运行一次的摘要查询,但会在整个集群中消耗 15 TB 的内存以按时完成计算并将摘要报告呈现给客户的门户。将 15 TB 的内存作为静态集群(如果我们考虑 AWS,这相当于 30 个巨大的裸机或 60-80 个超大型虚拟机),当您的平均每日内存需求仅为 1 左右时,成本会很高-2 TB 并且在波动。
教程:Kubernetes 上的动态 Spark 工作负载
我们将使用以下工具:
-
Jupyter Notebook 和 Python 3.6 用于查询
-
Spark 2.4.0 (Hadoop 2.6) 用于数据处理
-
Kublr 创建的 Kubernetes 集群
设置的特点:
Jupyter 笔记本
-
PySpark 已安装
-
笔记本持久化(存储在 EBS 磁盘上)
HDFS(可选)
-
默认安装包括:
-
2 个 namenod,1 个活动和 1 个备用,每个具有 100 GB 卷
-
4 个数据节点
-
3 个日志节点,每个节点有 20 GB 卷
-
3 个 zookeeper 服务(以确保只有一个 namenode 处于活动状态),每个具有 5 GB 卷
-
HDFS 客户端吊舱
-
持久数据
-
可靠性:即使所有 pod 都失败了,也会自动恢复,并且之前存储的数据可用。但是,不能保证在 Jupyter Notebook 使用 HDFS 期间进行透明的故障转移,至少因为活动和备用名称节点可以交换。
Spark 2.4.0 (Hadoop 2.6)
-
Kubernetes 创建与用户请求一样多的工作人员在 Jupyter Notebook 中创建 SparkContext
-
当用户在 Jupyter Notebook 中停止 SparkContext 或 Python3 内核时,Kubernetes 会自动删除 worker
-
即使在计算期间,Kubernetes 也会自动恢复失败的工作人员。恢复的工作人员接手并完成因故障中断的工作,因此故障转移对用户是透明的。
-
支持多用户工作:每个用户可以创建自己的独立worker
-
数据局部性: 数据处理的方式是,存储在HDFS节点上的数据由在同一个Kubernetes节点上执行的Spark工作人员处理,从而显着降低网络使用率和更好的性能。
自动伸缩 Kubernetes 集群
-
没有更多资源供 Spark Worker 使用时自动创建更多 Kubernetes 节点(横向扩展)
-
负载低时自动缩容,降低成本
为 Jupyter Notebook 和 Spark 工作者准备 Docker 镜像
为 Jupyter Notebook 和 Spark workers 准备 Docker 镜像 我们已经为本教程准备了所有必要的镜像。如果这对您有用,请跳到本教程的下一部分。
如果您想自定义 Docker 映像(例如,使用更新版本的组件或您的生产设置中所需的某些文件)从这里开始。
克隆我们的演示仓库,并切换到正确的文件夹:
git clone https://github.com/kublr/demos.git
cd demos/demo9-jupyter-pyspark
然后,下载并解压 Spark 发行版。您可以使用以下命令:
wget http://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.6.tgz
tar xvzf spark-2.4.0-bin-hadoop2.6.tgz
rm spark-2.4.0-bin-hadoop2.6.tgz
为方便起见,让我们为发行版创建一个名为 spark 的简短符号链接:
ln -s spark-2.4.0-bin-hadoop2.6 spark
您希望使用 Spark 和 Python 构建 Docker 映像**<您的帐户>/spark-py:2.4.0-hadoop-2.6**。此后,在以下命令中将 kublr 替换为您的 Docker Hub 帐户名并运行它:
(cd spark && bin/docker-image-tool.sh -r docker.io/kublr -t 2.4.0-hadoop-2.6 build)
将映像推送到 Docker Hub,以便 Kubernetes 能够从中创建工作 pod。您可能必须首先调用 docker login 才能上传新图像。登录后,上传:
docker push kublr/spark-py:2.4.0-hadoop-2.6
完成 Spark 镜像创建后,您可以在“jupyter/Dockerfile”文件中自定义 Jupyter Notebook 镜像,然后使用以下命令构建并推送镜像(将 Docker Hub 帐户名替换为所需的):
docker build -t kublr/pyspark-notebook:spark-2.4.0-hadoop-2.6 -f jupyter/Dockerfile .
docker push kublr/pyspark-notebook:spark-2.4.0-hadoop-2.6
在这个阶段,您拥有自定义的 Spark 工作人员映像以在集群中生成数百个工作人员,并拥有 Jupyter Notebook 映像以使用熟悉的 Web UI 与 Spark 和集群中的数据进行交互。
使用 Kublr 创建 Kubernetes 集群
在以下示例中,我们将使用 Amazon Web Services (AWS) 来运行我们的集群。还有许多其他选项可供选择(例如 Azure、GCP、裸机、VMware 云和 vSphere)。您甚至可以在本教程中使用现有集群。
要管理必要的 AWS 资源,例如 EC2 实例、弹性负载均衡器和 Route53 DNS 记录,需要一组有效的 AWS IAM 凭证。
您可以在 Kublr 管理仪表板的“凭据”部分创建它们。准备就绪后,导航到“集群”部分,单击“添加集群”并继续填写所需的详细信息:
-
为您的集群命名。
-
单击“AWS”提供商(或者,如果您在另一个提供商上创建,请选择它,然后直观地处理所有其他详细信息。接下来要选择的字段会因一个提供商而异,但相对而言是自我的解释性的。
-
选择 AWS IAM 凭证以创建集群。
4.使用可用区域列表中的任何区域
5.您可以保留选择的操作系统,Ubuntu 16.04。
- 单个主集群可用于测试目的。
7.主实例类型默认为t2.medium,测试应该够用了。但是,如果您想在集群中添加更多组件,这可能会给 master 带来更重的负载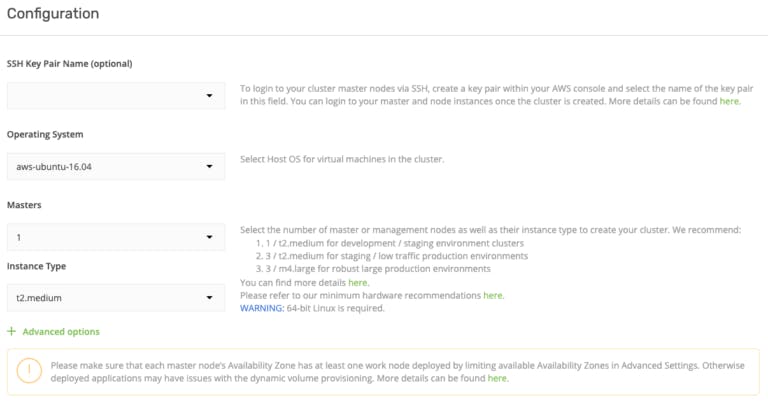
-
在“创建节点”部分,将节点数字段留空,我们将在底部启用自动缩放,因此该字段值无关紧要。
-
选择worker的实例类型为t2.xlarge。我们将使用相当多的组件。
-
选择任何可用区——它不会影响我们的设置。
11.启用自动缩放!这是 Kublr 的 Kubernetes 设置中最强大的功能之一。无论您选择哪个云提供商来部署集群,都将配置自动扩展。
- 将最小节点数设置为“2”,将最大节点数设置为“4”(或更多,如果您想更大规模地试验这种机制)。这是什么意思?当 Spark 工作负载增加时,Kubernetes 将通知底层基础设施(在我们的例子中是 AWS API)它需要更多的工作节点。然后将按需创建工作节点。当 Spark 工作负载再次减少时,Kubernetes 会通知 AWS API。通过关闭所有空闲节点来缩减集群,从而显着降低成本。自动缩放不需要保持高容量的机器池 24/7 可用
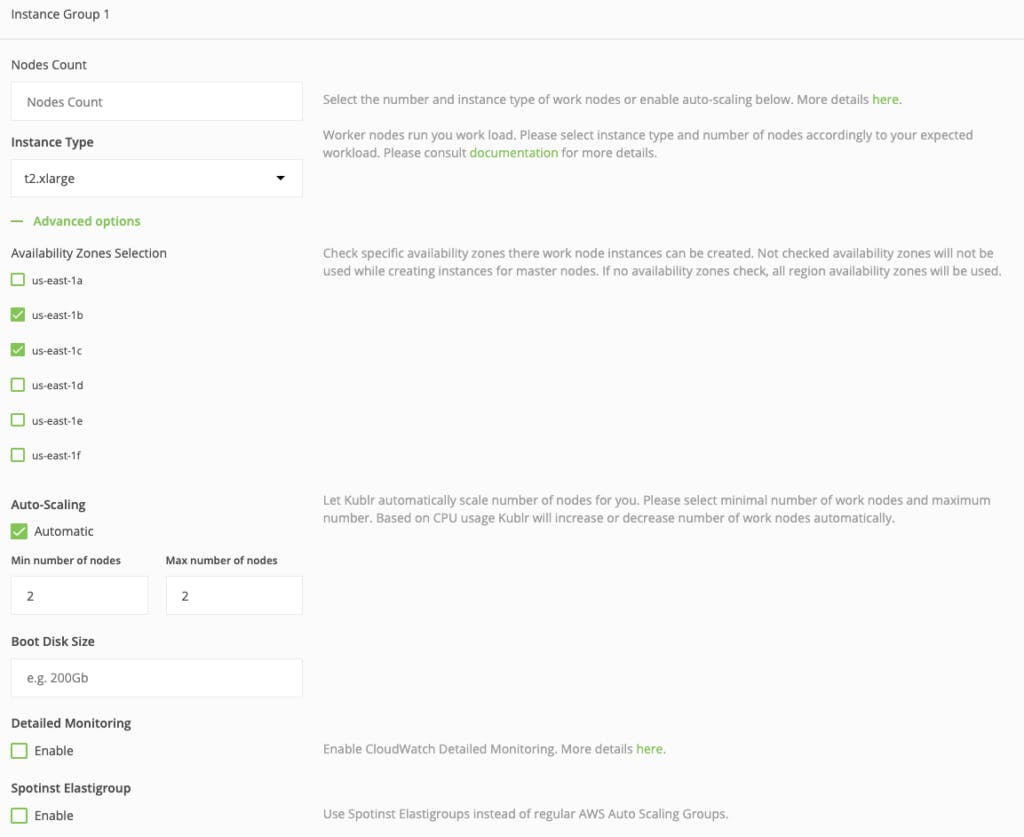
至此,工作节点的伸缩组的配置就完成了,但是让我们花点时间来强调一个非常有效的降低成本的特性......
现在找到名为“Spotinst Elastigroup”的复选框。如果您不熟悉 Spotinst(如果您不熟悉,请不要担心——这是一项相对较新的服务),您甚至可能不会注意到它。猜猜看,选中那个小框可能会将您的基础架构成本降低 70%!
此选项激活 Kublr 的 Spotinst 集成。 Spontinst 将通过在 AWS Spot 市场上自动出价来管理您的实例,并以价格的一小部分使用空闲的 AWS 容量。好的!但是 - 是的,恐怕有一个但是 - 有一个问题,但有一个解决方法。这些实例可能会在两分钟通知内终止。当 Spotinst Elastigroup 收到这样的“通知”时,可以调用自定义脚本的触发事件,以便您可以在 Kubernetes 集群中运行清理或“排水节点”。
终止的实例将被 Spotinst 自动替换,同时竞标其他实例大小或区域(所有这些都有设置)。如果您有兴趣尝试此选项,请阅读 Elastigroup](https://api.spotinst.com/introducing-elastigroup/)的[官方文档。获取您的 Spotinst API 令牌并启用该复选框。它会要求您提供“Spotinst 帐户令牌”。在那里使用 API 密钥,Kublr 将处理该集群的其余 Elastigroup 配置。
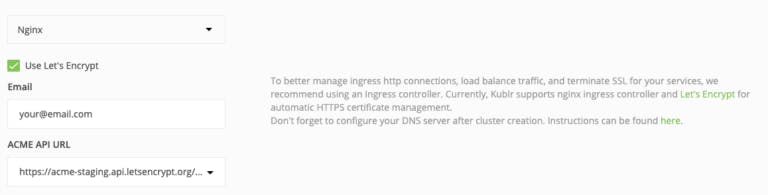
让我们回到演示集群设置的其余部分。需要入口控制器才能将 Jupyter Notebook 公开到 Internet,因此展开集群设置的“入口控制器”部分。要为您的端点配置 HTTPS,请选择 Use Let's Encrypt 并提供所需的参数(如下例所示)。否则,将使用自签名 SSL 证书,并且 Web 浏览器会抱怨安全性。对于本教程,没关系,因此您可以将其留空,然后按“确认并安装”。
 创建可能需要 15 分钟或更长时间,具体取决于底层云提供商。当集群启动并运行时,Kublr 仪表板如下所示:
创建可能需要 15 分钟或更长时间,具体取决于底层云提供商。当集群启动并运行时,Kublr 仪表板如下所示:
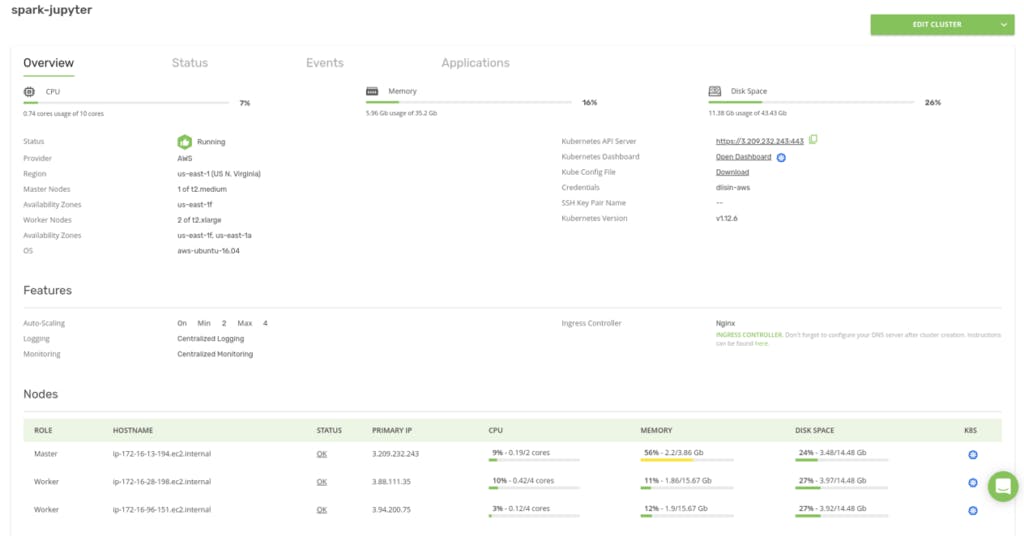 请注意,集群包含一个“Master”和两个“Worker”节点,这是我们在自动扩展设置中指定的最小工作节点数。
请注意,集群包含一个“Master”和两个“Worker”节点,这是我们在自动扩展设置中指定的最小工作节点数。
要在新集群中使用 kubectl 和 helm,您需要从 Kublr 仪表板下载 Kube 配置文件。将其本地保存在操作员工作站上的 ~/.kube/config 中(可能是您的笔记本电脑,或者如果您通过堡垒工作,则可能是堡垒主机)。
最后,让我们打开 Kubernetes Dashboard。单击打开仪表板。 需要认证。要从下载的 ~/.kube/config 文件中获取令牌,请运行:
需要认证。要从下载的 ~/.kube/config 文件中获取令牌,请运行:
cat ~/.kube/config | grep token
此命令打印类似于:
- name: spark-jupyter-admin-token
token: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
“token”值是我们授权所需要的。只需将其复制粘贴到登录表单中,然后单击“登录”: 或者,如果单击SKIP,您可以在只读模式下使用 Kubernetes Dashboard。它将以匿名用户身份登录仪表板,默认情况下为只读模式。您将无法查看某些资源(例如“秘密”)或更改它们——这种模式不太方便。
或者,如果单击SKIP,您可以在只读模式下使用 Kubernetes Dashboard。它将以匿名用户身份登录仪表板,默认情况下为只读模式。您将无法查看某些资源(例如“秘密”)或更改它们——这种模式不太方便。
安装 Jupyter Notebook
现在,我们有一个最小的工作集群。 Spark 和其他组件尚未安装。让我们从 Jupyter Notebook 开始。这是热身的简单第一步。使用此示例清单克隆 Kublr 演示存储库:github.com/kublr/demos/tree/master/demo9-ju..。我们将使用 Helm 作为 Helm 图表安装它。
首先在服务器上升级 Tiller,以防你的本地“helm”版本默认比集群中的版本新:
helm init --upgrade
稍等一下,它会升级。从官方上游位置以图表形式安装 Jupyter Notebook。 my-pyspark-notebook 是此图表“实例”的示例名称。你可以给它起任何名字,当你检查集群中安装了什么时,它会出现在“helm list”中:
helm install -n my-pyspark-notebook charts/pyspark-notebook
请注意:如果 Kubernetes 仪表板在创建 Pod 的过程中短时间显示这样的错误,完全可以:
pod has unbound immediate PersistentVolumeClaims (repeated 2 times)
AttachVolume.Attach failed for volume "pvc-82ebda50-6a58-11e9-80e4-02a82483ac0c" : "Error attaching EBS volume \"vol-02b63505fb00f7240\"" to instance "i-02b46ac14d1808b6d" since volume is in "creating" state
创建这些 pod 的卷时,它将消失。一切完成后,您将能够看到 Pod 和 Jupyter Notebook 的“服务”。
将自定义域名与入口主机名关联
当您在 AWS 中创建集群时,Kubernetes 会为入口控制器分配一个动态负载均衡器。无论是 nginx 控制器还是 AWS ELB 控制器都没有关系。您仍然需要找出它的名称和 DNS 地址。使用以下命令获取入口控制器主机名:
kubectl get service -n kube-system kublr-feature-ingress-nginx-ingress-controller -o 'jsonpath={.status.loadBalancer.ingress[0].hostname}'
它的作用是从“kube-system”命名空间中的集群中读取“服务”定义,并显示我们请求的字段的值:
{.status.loadBalancer.ingress[0].hostname}
对于 AWS,它应该打印出类似以下 ELB 地址的内容:
aa5e1e16a543111e9ae3d0e6004935f1-473611111.us-east-1.elb.amazonaws.com.
配置您的域,使其指向该主机名——您可以创建“CNAME”或“A”别名记录。如果您的 DNS 托管区域位于 Route53 中,则最好创建一个别名。您不会为名称解析付费(有关这两种类型的 Route53 记录之间的更多差异,请参阅此处)。
访问 Jupyter Notebook Web 界面
要导航到 Web UI,我们需要找到正在运行的 Jupyter 实例及其登录令牌。在单个命令中执行此操作的一种快速方法是:
1.将域名保存在K8S_DOMAIN环境变量中
- 在活动的 Jupyter pod 中运行 “jupyter notebook list” 命令并构造一个正确的登录 URL,如下所示:
kubectl exec $(kubectl get pods -l app.kubernetes.io/instance=my-pyspark-notebook -o go-template --template '{{(index .items 0).metadata.name}}') jupyter notebook list \
| grep 'http://0.0.0.0:8888/' \
| awk '{print $1}' \
| sed "s|http://0.0.0.0:8888|https://$K8S_DOMAIN|"
这个命令做了三件事:
-
找到需要的 pod 的名字,
-
执行命令“jupyter notebook list”查看活跃的 Jupyter 会话及其令牌,
-
将通用 localhost 地址替换为您的自定义域名,以获得带有令牌的正确链接。
在 Web 浏览器中打开此 URL。为避免可能的 DNS 缓存问题,请等待几分钟,然后再打开 Jupyter Notebook。
运行 Spark 工作负载 通过单击“新建”->“Python 3”在 Jupyter 中创建 Python 3 笔记本:
创建 Spark 上下文并注意突出显示的代码注释以了解示例的每个部分的作用。我们使用了“#”,您仍然可以将以下所有代码复制粘贴到 UI 中并运行它:
import pyspark
# After we imported the package,
# create the SparkConf object for configuration:
conf = pyspark.SparkConf()
# Kubernetes is a Spark master in our setup.
# It creates pods with Spark workers, orchestrates those
# workers and returns final results to the Spark driver
# (“k8s://https://” is NOT a typo, this is how Spark knows the “provider” type).
conf.setMaster("k8s://https://kubernetes.default.svc.cluster.local:443")
# Worker pods are created from this docker image.
# If you use another image, specify its name instead.
conf.set("spark.kubernetes.container.image", "kublr/spark-py:2.4.0-hadoop-2.6")
# Authentication (required to create worker pods):
conf.set("spark.kubernetes.authenticate.caCertFile", "/var/run/secrets/kubernetes.io/serviceaccount/ca.crt")
conf.set("spark.kubernetes.authenticate.oauthTokenFile", "/var/run/secrets/kubernetes.io/serviceaccount/token")
# Replace `my-pyspark-notebook` by the actual name
# of the Jupyter release in Helm (run “helm list” to see releases):
conf.set("spark.kubernetes.authenticate.driver.serviceAccountName", "my-pyspark-notebook")
# 2 pods/workers will be created. Customize it if necessary.
conf.set("spark.executor.instances", "2")
# Below, the DNS alias for the Spark driver come in handy.
# Replace `my-pyspark-notebook` by the release name, again:
conf.set("spark.driver.host", "my-pyspark-notebook-spark-driver.default.svc.cluster.local")
# Next we set the port. You are free to use another number.
# If this port is busy, spark-shell tries to bind to another port.
conf.set("spark.driver.port", "29413")
# And last, we create the SparkContext and pass it the config object,
# to launch the workers!
sc = pyspark.SparkContext(conf=conf)
结果,应该创建两个 Spark 工作 pod:
第一次,当 Kubernetes 将 Docker 映像下载到将运行它的主机时,工作 pod 创建可能需要几秒钟。现在您可以在 Spark 集群上进行计算,例如:
rdd = sc.parallelize(range(100000000))
rdd.sum()
它应该返回 4999999950000000。如果它有效,您就知道 Spark 是可操作的。
为了确保所有 pod 都参与了计算,我们可以读取它们的日志。对这些 pod 执行“kubectl logs”命令,或者只是在 Kubernetes 仪表板中打开它们的日志。这是一个示例,我们可以看到两个 pod('...exec-1' 和'...exec-2')都参与了此计算:
pyspark-shell-1553840280618-exec-1:
2019-03-29 06:21:38 INFO CoarseGrainedExecutorBackend:54 - Got assigned task 0
2019-03-29 06:21:38 INFO Executor:54 - Running task 0.0 in stage 0.0 (TID 0)
2019-03-29 06:21:38 INFO TorrentBroadcast:54 - Started reading broadcast variable 0
2019-03-29 06:21:38 INFO TransportClientFactory:267 - Successfully created connection to my-pyspark-notebook-spark-driver.default.svc.cluster.local/100.96.0.10:40161 after 2 ms (0 ms spent in bootstraps)
2019-03-29 06:21:38 INFO MemoryStore:54 - Block broadcast_0_piece0 stored as bytes in memory (estimated size 3.9 KB, free 413.9 MB)
2019-03-29 06:21:38 INFO TorrentBroadcast:54 - Reading broadcast variable 0 took 119 ms
2019-03-29 06:21:38 INFO MemoryStore:54 - Block broadcast_0 stored as values in memory (estimated size 5.7 KB, free 413.9 MB)
2019-03-29 06:21:40 INFO PythonRunner:54 - Times: total = 2137, boot = 452, init = 51, finish = 1634
2019-03-29 06:21:40 INFO Executor:54 - Finished task 0.0 in stage 0.0 (TID 0). 1468 bytes result sent to driver
pyspark-shell-1553840281184-exec-2:
2019-03-29 06:21:38 INFO CoarseGrainedExecutorBackend:54 - Got assigned task 1
2019-03-29 06:21:38 INFO Executor:54 - Running task 1.0 in stage 0.0 (TID 1)
2019-03-29 06:21:38 INFO TorrentBroadcast:54 - Started reading broadcast variable 0
2019-03-29 06:21:38 INFO TransportClientFactory:267 - Successfully created connection to my-pyspark-notebook-spark-driver.default.svc.cluster.local/100.96.0.10:40161 after 1 ms (0 ms spent in bootstraps)
2019-03-29 06:21:38 INFO MemoryStore:54 - Block broadcast_0_piece0 stored as bytes in memory (estimated size 3.9 KB, free 413.9 MB)
2019-03-29 06:21:38 INFO TorrentBroadcast:54 - Reading broadcast variable 0 took 115 ms
2019-03-29 06:21:38 INFO MemoryStore:54 - Block broadcast_0 stored as values in memory (estimated size 5.7 KB, free 413.9 MB)
2019-03-29 06:21:40 INFO PythonRunner:54 - Times: total = 2108, boot = 433, init = 52, finish = 1623
2019-03-29 06:21:40 INFO Executor:54 - Finished task 1.0 in stage 0.0 (TID 1). 1425 bytes result sent to driver
此外,清理资源也是一个好习惯。你可以通过运行:sc.stop()
此命令删除 worker pod,效果与关闭 notebook 内核相同。
将 HDFS 部署到 Kubernetes 集群
为了加快数据处理速度,请将 Hadoop 分布式文件系统部署到此集群。 HDFS 的架构允许高吞吐量和更快的“寻找”所需的数据块,以便在数据驻留在磁盘上的同一节点上处理数据。
虽然该机制的描述超出了本文的范围,但您可以在此处](https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html#Introduction)阅读有关此架构[的好处的更多信息。
为方便起见,HDFS on Kubernetes项目包含一个现成的 Helm 图表,用于在 Kubernetes 集群上部署 HDFS。默认设置包括:
-
2 个名称节点,1 个活动和 1 个备用,每个具有 100 GB 卷
-
4 个数据节点
-
3 个日志节点,每个 20 GB 卷
-
3 个 Zookeeper 服务器(以确保只有一个 namenode 处于活动状态),每个具有 5 GB 卷
-
HDFS 客户端 pod
要部署它,请克隆示例 repo,然后切换到该文件夹:
git clone https://github.com/apache-spark-on-k8s/kubernetes-HDFS.git
cd kubernetes-HDFS
要稍后访问 HDFS Web UI,您需要编辑属性 dfs.namenode.http-address.hdfs-k8s.nn0 和 **dfs.namenode.http-address.hdfs-k8s.nn1 ** 在这个文件中 “charts/hdfs-config-k8s/templates/configmap. yaml”, 像这样:
<property>
<name>dfs.namenode.http-address.hdfs-k8s.nn0</name>
<value>0.0.0.0:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.hdfs-k8s.nn1</name>
<value>0.0.0.0:50070</value>
</property>
这里我们复制了设置 HDFS 所需的命令,但它们可能会过时,所以看到最新版本的来源。
helm repo add incubator \
https://kubernetes-charts-incubator.storage.googleapis.com/
helm dependency build charts/hdfs-k8s
helm install -n my-hdfs charts/hdfs-k8s
我们使用默认版本名称 my-hdfs,但您不必这样做。如果您使用其他名称,请在遵循本指南章节时替换它。
安装 Helm 版本时,会创建一些 pod、配置映射、守护程序集和其他资源。虽然此处未涵盖所有这些的详细描述,但您可以在线找到该信息。整个过程可能需要一些时间,因为 pod has unbound immediate PersistentVolumeClaims 和/或自动缩放等临时错误。一切准备就绪后,您应该可以使用端口转发访问 HDFS Web UI:
kubectl port-forward service/my-hdfs-namenode 50070:50070
然后 UI 在localhost:50070可用。您可以通过导航查看系统的当前状态。 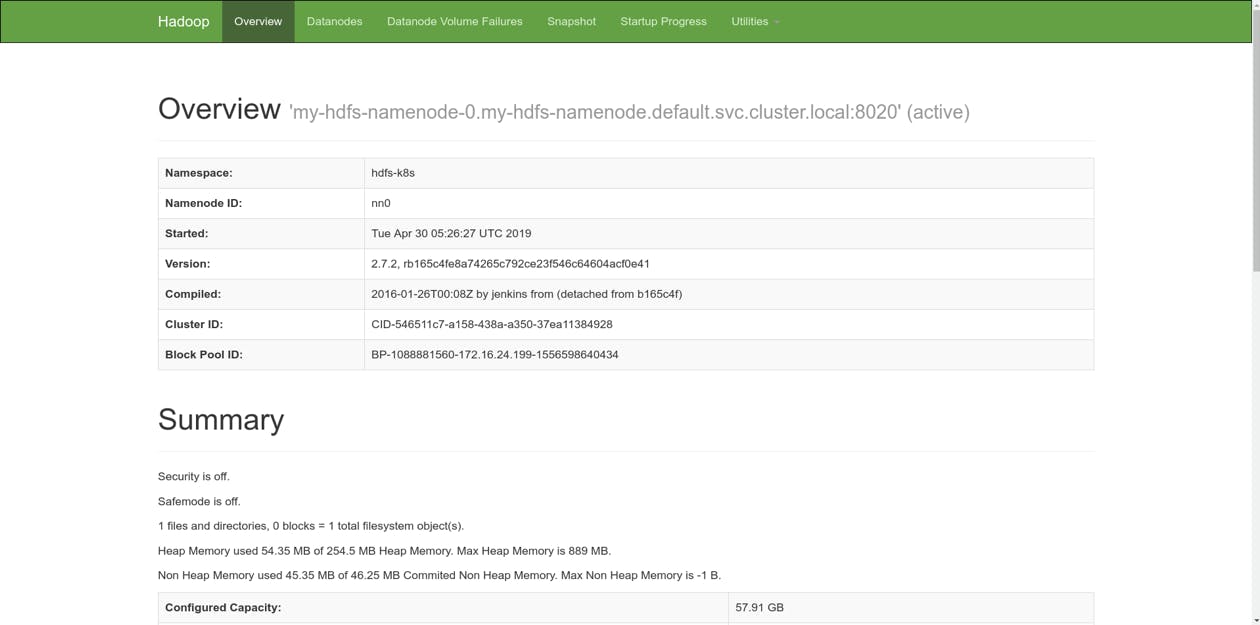 现在我们要创建一个新的 Spark 会话:
现在我们要创建一个新的 Spark 会话:
from pyspark.sql import SparkSession
sparkSession = SparkSession.builder \
.master("k8s://https://kubernetes.default.svc.cluster.local:443") \
.config("spark.kubernetes.container.image", "kublr/spark-py:2.4.0-hadoop-2.6") \
.config("spark.kubernetes.authenticate.caCertFile", "/var/run/secrets/kubernetes.io/serviceaccount/ca.crt") \
.config("spark.kubernetes.authenticate.oauthTokenFile", "/var/run/secrets/kubernetes.io/serviceaccount/token") \
.config("spark.kubernetes.authenticate.driver.serviceAccountName", "my-pyspark-notebook") \
.config("spark.executor.instances", "2") \
.config("spark.driver.host", "my-pyspark-notebook-spark-driver.default.svc.cluster.local") \
.config("spark.driver.port", "29413") \
.getOrCreate()
sc = sparkSession.sparkContext
描述一些数据:
df = sparkSession.createDataFrame(sc.parallelize(range(10000000)).map(lambda i: ((i, i * 2))))
此后,我们将从 helm install 和其他人创建的专用 pod 执行 HDFS 命令。在这里我们得到它的名字:
_CLIENT=$(kubectl get pods -l app=hdfs-client,release=my-hdfs -o name | cut -d/ -f 2)
如果您按照上述方式部署了 HDFS,则应该有 2 个名称节点。让我们检查一下:
kubectl exec $_CLIENT -- hdfs haadmin -getServiceState nn0
它打印活动。那么,另一个呢?
kubectl exec $_CLIENT -- hdfs haadmin -getServiceState nn1
输出:待机。
这意味着,我们有一个活动的主节点和一个处于备用模式的副本。让我们将数据保存为 HDFS 上的 CSV 文件。我们必须使用主节点的主机名来完成,因为处于待机模式的节点无法接受写入请求。
df.write.csv("hdfs://my-hdfs-namenode-0.my-hdfs-namenode.default.svc.cluster.local/user/hdfs/test/example.csv")
通过 Spark worker pod 日志,我们可以确保所有的 pod 都参与了计算和写入:
pyspark-shell-1554099778487-exec-1:
2019-04-01 06:25:27 INFO CoarseGrainedExecutorBackend:54 - Got assigned task 2
2019-04-01 06:25:27 INFO Executor:54 - Running task 1.0 in stage 1.0 (TID 2)
2019-04-01 06:25:27 INFO TorrentBroadcast:54 - Started reading broadcast variable 1
2019-04-01 06:25:27 INFO MemoryStore:54 - Block broadcast_1_piece0 stored as bytes in memory (estimated size 53.4 KB, free 413.9 MB)
2019-04-01 06:25:27 INFO TorrentBroadcast:54 - Reading broadcast variable 1 took 18 ms
2019-04-01 06:25:27 INFO MemoryStore:54 - Block broadcast_1 stored as values in memory (estimated size 141.1 KB, free 413.7 MB)
2019-04-01 06:25:28 INFO CodeGenerator:54 - Code generated in 214.957469 ms
2019-04-01 06:25:28 INFO SQLHadoopMapReduceCommitProtocol:54 - Using output committer class org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2019-04-01 06:25:46 INFO PythonRunner:54 - Times: total = 19412, boot = 8, init = 42, finish = 19362
2019-04-01 06:25:47 INFO FileOutputCommitter:439 - Saved output of task 'attempt_20190401062528_0001_m_000001_0' to hdfs://my-hdfs-namenode-0.my-hdfs-namenode.default.svc.cluster.local/user/hdfs/test/example.csv/_temporary/0/task_20190401062528_0001_m_000001
2019-04-01 06:25:47 INFO SparkHadoopMapRedUtil:54 - attempt_20190401062528_0001_m_000001_0: Committed
2019-04-01 06:25:47 INFO Executor:54 - Finished task 1.0 in stage 1.0 (TID 2). 2727 bytes result sent to driver
pyspark-shell-1554099779266-exec-2:
2019-04-01 06:25:27 INFO CoarseGrainedExecutorBackend:54 - Got assigned task 1
2019-04-01 06:25:27 INFO Executor:54 - Running task 0.0 in stage 1.0 (TID 1)
2019-04-01 06:25:27 INFO TorrentBroadcast:54 - Started reading broadcast variable 1
2019-04-01 06:25:27 INFO TransportClientFactory:267 - Successfully created connection to /100.96.3.8:35072 after 2 ms (0 ms spent in bootstraps)
2019-04-01 06:25:27 INFO MemoryStore:54 - Block broadcast_1_piece0 stored as bytes in memory (estimated size 53.4 KB, free 413.9 MB)
2019-04-01 06:25:27 INFO TorrentBroadcast:54 - Reading broadcast variable 1 took 127 ms
2019-04-01 06:25:27 INFO MemoryStore:54 - Block broadcast_1 stored as values in memory (estimated size 141.1 KB, free 413.7 MB)
2019-04-01 06:25:28 INFO CodeGenerator:54 - Code generated in 291.154539 ms
2019-04-01 06:25:29 INFO SQLHadoopMapReduceCommitProtocol:54 - Using output committer class org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2019-04-01 06:25:47 INFO PythonRunner:54 - Times: total = 19679, boot = 411, init = 52, finish = 19216
2019-04-01 06:25:47 INFO FileOutputCommitter:439 - Saved output of task 'attempt_20190401062528_0001_m_000000_0' to hdfs://my-hdfs-namenode-0.my-hdfs-namenode.default.svc.cluster.local/user/hdfs/test/example.csv/_temporary/0/task_20190401062528_0001_m_000000
2019-04-01 06:25:47 INFO SparkHadoopMapRedUtil:54 - attempt_20190401062528_0001_m_000000_0: Committed
2019-04-01 06:25:47 INFO Executor:54 - Finished task 0.0 in stage 1.0 (TID 1). 2727 bytes result sent to driver
让我们回顾一下 HDFS 中的文件:
kubectl exec $_CLIENT -- hdfs dfs -ls /user/hdfs/test/example.csv
它应该打印类似的东西
Found 3 items
-rw-r--r-- 3 root supergroup 0 2019-04-01 06:25 /user/hdfs/test/example.csv/_SUCCESS
-rw-r--r-- 3 root supergroup 78333335 2019-04-01 06:25 /user/hdfs/test/example.csv/part-00000-8de1982a-d9f9-4632-82bc-2f623b6b51ca-c000.csv
-rw-r--r-- 3 root supergroup 85000000 2019-04-01 06:25 /user/hdfs/test/example.csv/part-00001-8de1982a-d9f9-4632-82bc-2f623b6b51ca-c000.csv
正如我们所见,它由 2 个部分组成,一个用于每个 Spark worker。
现在让我们读取文件(我们应该看到打印了“10000000”),以便 pod 读取它:
sparkSession.read.csv("hdfs://my-hdfs-namenode-0.my-hdfs-namenode.default.svc.cluster.local/user/hdfs/test/example.csv").count()
读取也在两个 Spark pod 上执行,我们现在可以看到:
pyspark-shell-1554099778487-exec-1:
019-04-01 08:37:41 INFO CoarseGrainedExecutorBackend:54 - Got assigned task 4
2019-04-01 08:37:41 INFO Executor:54 - Running task 0.0 in stage 3.0 (TID 4)
2019-04-01 08:37:41 INFO TorrentBroadcast:54 - Started reading broadcast variable 6
2019-04-01 08:37:41 INFO TransportClientFactory:267 - Successfully created connection to /100.96.2.12:32964 after 2 ms (0 ms spent in bootstraps)
2019-04-01 08:37:41 INFO MemoryStore:54 - Block broadcast_6_piece0 stored as bytes in memory (estimated size 6.5 KB, free 413.9 MB)
2019-04-01 08:37:41 INFO TorrentBroadcast:54 - Reading broadcast variable 6 took 55 ms
2019-04-01 08:37:41 INFO MemoryStore:54 - Block broadcast_6 stored as values in memory (estimated size 12.3 KB, free 413.9 MB)
2019-04-01 08:37:41 INFO CodeGenerator:54 - Code generated in 22.953308 ms
2019-04-01 08:37:41 INFO FileScanRDD:54 - Reading File path: hdfs://my-hdfs-namenode-0.my-hdfs-namenode.default.svc.cluster.local/user/hdfs/test/example.csv/part-00001-8de1982a-d9f9-4632-82bc-2f623b6b51ca-c000.csv, range: 0-85000000, partition values: [empty row]
2019-04-01 08:37:41 INFO CodeGenerator:54 - Code generated in 6.817728 ms
2019-04-01 08:37:41 INFO TorrentBroadcast:54 - Started reading broadcast variable 5
2019-04-01 08:37:41 INFO MemoryStore:54 - Block broadcast_5_piece0 stored as bytes in memory (estimated size 20.9 KB, free 413.9 MB)
2019-04-01 08:37:41 INFO TorrentBroadcast:54 - Reading broadcast variable 5 took 9 ms
2019-04-01 08:37:41 INFO MemoryStore:54 - Block broadcast_5 stored as values in memory (estimated size 296.3 KB, free 413.6 MB)
2019-04-01 08:37:42 INFO Executor:54 - Finished task 0.0 in stage 3.0 (TID 4). 1624 bytes result sent to driver
pyspark-shell-1554099779266-exec-2:
2019-04-01 08:37:41 INFO Executor:54 - Running task 1.0 in stage 3.0 (TID 5)
2019-04-01 08:37:41 INFO TorrentBroadcast:54 - Started reading broadcast variable 6
2019-04-01 08:37:41 INFO MemoryStore:54 - Block broadcast_6_piece0 stored as bytes in memory (estimated size 6.5 KB, free 413.9 MB)
2019-04-01 08:37:41 INFO TorrentBroadcast:54 - Reading broadcast variable 6 took 7 ms
2019-04-01 08:37:41 INFO MemoryStore:54 - Block broadcast_6 stored as values in memory (estimated size 12.3 KB, free 413.9 MB)
2019-04-01 08:37:41 INFO CodeGenerator:54 - Code generated in 20.519085 ms
2019-04-01 08:37:41 INFO FileScanRDD:54 - Reading File path: hdfs://my-hdfs-namenode-0.my-hdfs-namenode.default.svc.cluster.local/user/hdfs/test/example.csv/part-00000-8de1982a-d9f9-4632-82bc-2f623b6b51ca-c000.csv, range: 0-78333335, partition values: [empty row]
2019-04-01 08:37:41 INFO CodeGenerator:54 - Code generated in 14.180708 ms
2019-04-01 08:37:41 INFO TorrentBroadcast:54 - Started reading broadcast variable 5
2019-04-01 08:37:41 INFO MemoryStore:54 - Block broadcast_5_piece0 stored as bytes in memory (estimated size 20.9 KB, free 413.9 MB)
2019-04-01 08:37:41 INFO TorrentBroadcast:54 - Reading broadcast variable 5 took 20 ms
2019-04-01 08:37:41 INFO MemoryStore:54 - Block broadcast_5 stored as values in memory (estimated size 296.3 KB, free 413.6 MB)
2019-04-01 08:37:42 INFO Executor:54 - Finished task 1.0 in stage 3.0 (TID 5). 1668 bytes result sent to driver
访问 Spark Web UI
您还可以选择通过在终端中启动 Kubernetes 代理来打开对 Spark UI 的访问:
kubectl proxy
然后在localhost:8001/api/v1/namespaces/default/se..观察 Spark(将 my-pyspark-notebook 替换为 Jupyter 版本的实际名称)。 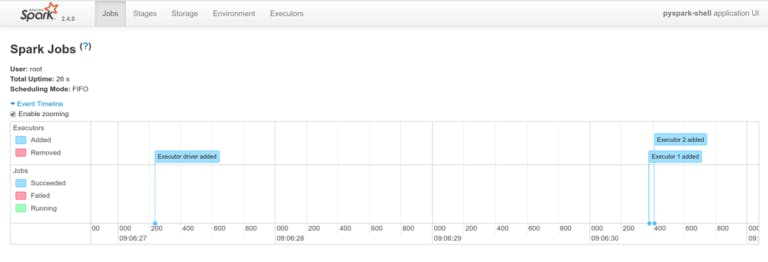 这是用于本地开发和测试目的的快速破解(使用 kube 代理访问 Kubernetes 集群中的服务)。如果您想向其他人公开这些仪表板,则应设置适当的入口规则并将域名指向该入口控制器地址。
这是用于本地开发和测试目的的快速破解(使用 kube 代理访问 Kubernetes 集群中的服务)。如果您想向其他人公开这些仪表板,则应设置适当的入口规则并将域名指向该入口控制器地址。
Spark pod 的资源请求和限制
Pod 内存和 CPU 消耗限制和请求,在 Spark 上下文创建期间设置,以后无法修改。默认情况下,它们分别设置为 1408Mi 和 1 CPU。
要自定义 CPU 限制,请设置 spark.kubernetes.executor.limit.cores. 示例:conf.set("spark.kubernetes.executor.limit.cores", "2") CPU 请求值,设置 spark.kubernetes.executor.request.cores. 示例:conf.set("spark.kubernetes.executor.request.cores", "0.5")
内存请求和限制不能单独配置。要自定义它们,请设置 spark.executor.memory: 示例:conf.set("spark.executor.memory", "2g")
Kubernetes 集群自动伸缩
至此,我们终于接近了最激动人心的功能设置!当 Kubernetes 需要为其 Spark 工作 pod 提供更多资源时,Kubernetes 集群自动缩放器将自动处理底层基础设施提供商的缩放。
让我们创建一个包含更多执行器的 Spark 上下文:
import pyspark
conf = pyspark.SparkConf()
conf.setMaster("k8s://https://kubernetes.default.svc.cluster.local:443")
conf.set("spark.kubernetes.container.image", "kublr/spark-py:2.4.0-hadoop-2.6")
conf.set("spark.kubernetes.authenticate.caCertFile", "/var/run/secrets/kubernetes.io/serviceaccount/ca.crt")
conf.set("spark.kubernetes.authenticate.oauthTokenFile", "/var/run/secrets/kubernetes.io/serviceaccount/token")
conf.set("spark.kubernetes.authenticate.driver.serviceAccountName", "my-pyspark-notebook")
conf.set("spark.executor.instances", "10")
conf.set("spark.driver.host", "my-pyspark-notebook-spark-driver.default.svc.cluster.local")
conf.set("spark.driver.port", "29413")
sc = pyspark.SparkContext(conf=conf)
一些 pod 资源不足,因为没有足够的 Kubernetes 工作节点来容纳所有这些 pod,所以它们无法启动: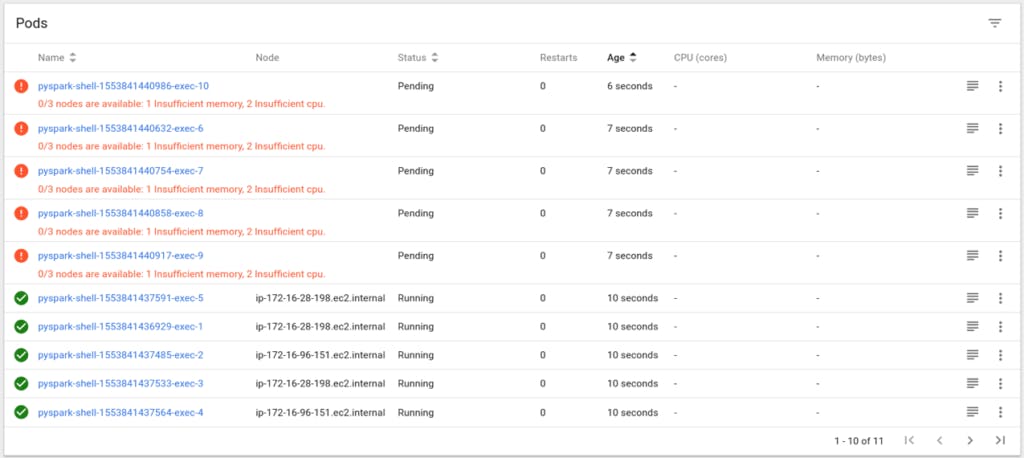
不要恐慌!我们配置了集群,让它自动扩展,记得吗?给 Kublr 和 Kubernetes 5 到 10 分钟的时间来创建更多节点。
他们来了: 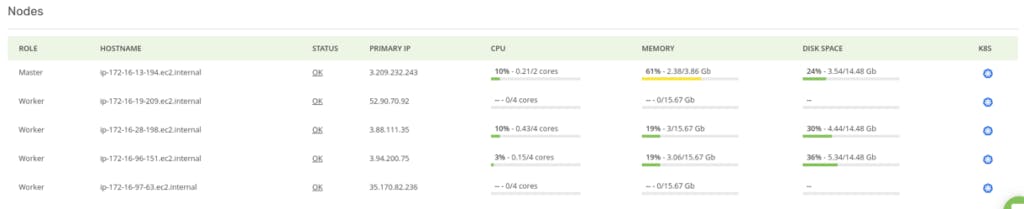
最后,所有 pod 都已启动并运行!现在假设我们已经完成了计算,想要关闭 Spark 上下文并释放资源,执行:sc.stop()
由于不需要额外的节点,自动缩放器将缩减集群。这也需要大约 10 分钟。
如果您在创建集群时使用 Spotinst,您的节省会更高。 Kublr 的 Spotinst 集成确保每次产生这些工作负载时,Spotinst 都会识别额外的资源需求并要求更多机器。 Spotinst 将使用其价格预测算法出价。他们能够非常精确地围兜,从而快速检索所需的 VM 实例。潜在的节省可能是巨大的,而扩展所需的时间很短,甚至不存在。
AWS 上的 Spot 实例非常适合像 Spark 工作者这样的短期工作负载(短期是指数小时到数天)。我们已经看到现场实例连续运行数周,有时甚至数月——这完全取决于实例大小。有些实例的需求较高,而有些实例的需求较低。那些公众需求低的实例大小可能会在收到终止信号之前继续运行数月。对于每小时的负载峰值,这是不费吹灰之力的。只有好处,没有什么可失去的。也就是说,只要我们谈论的是无状态应用程序,我们就可以轻松地添加新机器并终止旧机器,而不会对数据造成风险。
Spark 和其他类似的繁重但短期的处理操作是适合自动缩放的工作负载类型的完美示例。 Kublr 简化了跨云的多个集群的设置和操作,这些集群从一个单一的玻璃面板分布在不同的区域。自己试试吧— 对开发人员和 QA 人员免费!

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 0
0 0
0- 0



 已为社区贡献20439条内容
已为社区贡献20439条内容

所有评论(0)