使用 AWS EKS 配置 prometheus-operator helm 图表
Prometheus 是一种流行的开源监控和警报工具,特别适用于 Kubernetes 环境。有很多文章解释了 Prometheus 的惊人功能,所以本文的目的是帮助大家弄清楚如何配置 prometheus-operator helm chart,对于初学者来说似乎有相当复杂的文档。

首先可以找到prometheus-operatorhelm chart。
在过去的几周里,Github 存储库的维护者不断改进文档。这些改进包括一些来之不易的配置 helm chart 的方法以及一些我们必须非常努力才能弄清楚的技巧。即使在您找到了配置它的方法之后,EKS 对这个特定的舵图也有奇怪的问题,需要额外的自定义配置。
为了将 helm chart 安装到您的集群,
helm install stable/prometheus-operator --name prometheus-operator --namespace monitoring
这将在您的集群中创建一个命名空间监控并安装以下内容。
1.普罗米修斯
2.格拉法纳
- 警报管理器
这还添加了节点导出器,用于跟踪来自您的工作节点的数据并将它们发送到 Prometheus。
然而,故事并没有到此结束。默认提供的配置将非常基本。例如,存储在 Prometheus 中的数据不是持久的,并且入口没有定义。您必须代理仪表板才能访问它们。
当您在互联网上搜索如何配置 helm chart 时,您会发现 values.yaml 文件需要使用所需的配置进行编辑。
该文件可以在这里找到。
以下是我们配置的一些您可能会觉得有用的东西。
警报管理器配置:
Alertmanager 用于将 Prometheus 触发的警报转发到 Pagerduty 等警报工具。我们在 Zolo 使用 Zenduty。如果您不想与任何付费规则相关联,您可以随时与 Slack 集成。在 values.yaml 文件中找到 Alertmanager 配置指令块并按以下方式更新它。
## Alertmanager configuration directives
## ref: https://prometheus.io/docs/alerting/configuration/#configuration-file
## https://prometheus.io/webtools/alerting/routing-tree-editor/
##
config:
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'devops'
routes:
# suppress
- match:
alertname: Watchdog
receiver: 'null'
- match:
deployment: 'backend'
receiver: 'backend'
- match_re:
pod: '(backend.*)'
receiver: 'backend'
- match:
deployment: 'frontend'
receiver: 'frontend'
- match_re:
pod: '(frontend.*)'
receiver: 'frontend'
receivers:
# suppress
- name: 'null'
# devops
- name: 'devops'
webhook_configs:
- url: 'https://www.zenduty.com/api/integration/prometheus/<key>/'
# backend
- name: 'backend'
webhook_configs:
- url: 'https://www.zenduty.com/api/integration/prometheus/<key>/'
# frontend
- name: 'frontend'
webhook_configs:
- url: 'https://www.zenduty.com/api/integration/prometheus/<key>/'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
默认情况下,所有警报都会发送到 DevOps 接收器。只有前端 pod 警报会发送到前端接收器,就像后端 pod 警报会发送到后端接收器一样。每个接收器都配置有一个唯一的 webhook。这些 webhook 会根据提供的配置触发 SMS 和电话呼叫相关的待命开发人员。这些警报工具非常直观,具有强大的支持,并且使用升级策略对其进行配置是小菜一碟。
警报管理器入口:
如果您不想每次都通过 localhost 代理 Alertmanager 仪表板,您可以像下面这样配置入口。
ingress:
enabled: true
annotations: {
kubernetes.io/ingress.class: "nginx",
nginx.ingress.kubernetes.io/whitelist-source-range: "172.16.254.1"
}
labels: {}
## Hosts must be provided if Ingress is enabled.
##
hosts:
- alertmanager.example.com
## Paths to use for ingress rules - one path should match the alertmanagerSpec.routePrefix
##
paths:
- /
这确保域alertmanager.example.com仅在给定的 IP 地址上可用。这是必要的,因为没有固有的身份验证机制。这个入口遵循标准的基于 Nginx 的 Kubernetes Ingress。
附加普罗米修斯规则:
Prometheus 默认带有许多有用的规则,这些规则基本上会在违反这些规则时触发警报。但这些只是最低限度。在网上研究了几篇 SRE 文章后,我发现以下链接非常有用。Awesome Prometheus AlertsMonitoring Distributed SystemsHow to monitor Golden signals in Kubernetes。
为了将自定义规则添加到现有的 Prometheus 配置,请在 additionalPrometheusRules 块中进行更改。
## Provide custom recording or alerting rules to be deployed into the cluster.
##
additionalPrometheusRules:
- name: custom-rules-file
groups:
- name: custom-node-exporter-rules
rules:
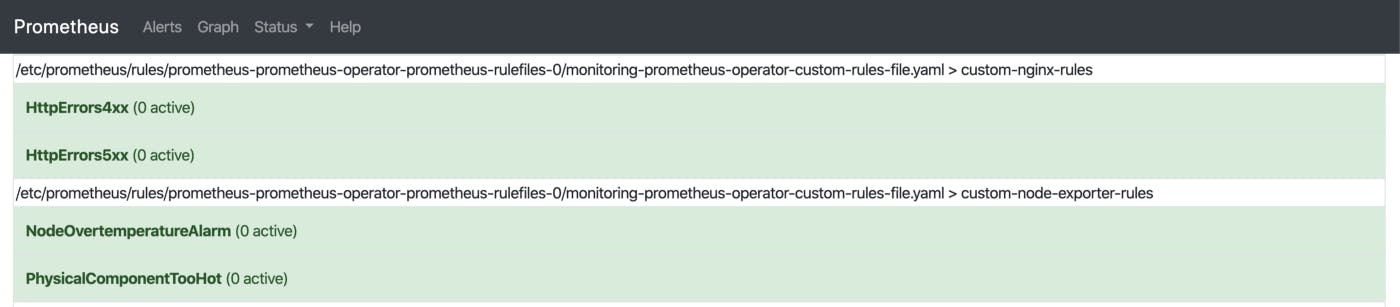
- alert: PhysicalComponentTooHot
expr: node_hwmon_temp_celsius > 75
for: 5m
labels:
severity: warning
annotations:
summary: "Physical component too hot (instance {{ $labels.instance }})"
description: "Physical hardware component too hot\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: NodeOvertemperatureAlarm
expr: node_hwmon_temp_alarm == 1
for: 5m
labels:
severity: critical
annotations:
summary: "Node overtemperature alarm (instance {{ $labels.instance }})"
description: "Physical node temperature alarm triggered\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
例如,当物理组件过热时,上面的块会触发警报。
Grafana 入口:
Grafana 是一个开源监控和分析解决方案。这与 Prometheus 深度集成,并提供了非常有用的预定义仪表板。
要通过自定义域访问 Grafana,请更新入口配置,
ingress:
## If true, Grafana Ingress will be created
##
enabled: true
## Annotations for Grafana Ingress
##
annotations: {
kubernetes.io/ingress.class: "nginx",
nginx.ingress.kubernetes.io/whitelist-source-range: "172.16.254.1"
}
# kubernetes.io/ingress.class: nginx
# kubernetes.io/tls-acme: "true"
## Labels to be added to the Ingress
##
labels: {}
## Hostnames.
## Must be provided if Ingress is enable.
##
# hosts:
# - grafana.domain.com
hosts:
- grafana.example.com
## Path for grafana ingress
path: /
根据上述配置,Grafana 仪表板将通过上述 IP 地址通过grafana.example.com访问。 Grafana 有一个身份验证系统,因此您可以选择将其公开。
普罗米修斯入口:
就像 Alertmanager 和 Grafana 一样,Prometheus 仪表板也可以通过自定义域访问。
ingress:
enabled: true
annotations: {
kubernetes.io/ingress.class: "nginx",
nginx.ingress.kubernetes.io/whitelist-source-range: "172.16.254.1"
}
labels: {}
## Hostnames.
## Must be provided if Ingress is enabled.
##
# hosts:
# - prometheus.domain.com
hosts:
- prometheus.example.com
## Paths to use for ingress rules - one path should match the prometheusSpec.routePr
##
paths:
- /
报废和评估间隔:
您可以通过更新 prometheusSpec 块来更新抓取和评估间隔。
## Settings affecting prometheusSpec
## ref: https://github.com/coreos/prometheus-operator/blob/master/Documentation/api.md#prometheusspec
##
prometheusSpec:
## Interval between consecutive scrapes.
##
scrapeInterval: 15s
## Interval between consecutive evaluations.
##
evaluationInterval: 15s
Prometheus 的## 持久卷:
默认情况下,Prometheus 使用工作节点提供的卷来存储数据。但我们可以将其配置为使用持久卷,以确保即使 Prometheus 宕机或重启时数据也不会丢失。
## Prometheus StorageSpec for persistent data
## ref: https://github.com/coreos/prometheus-operator/blob/master/Documentation/user-guides/storage.md
##
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: gp2
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 50Gi
由于我们使用的是 AWS,因此 gp2 将是 storageClassName。根据您的需要请求存储大小。
EKS 具体更改:
当你使用默认配置设置 Prometheus 时,你会看到很多不必要的警报。例如,KubeScheduler 没有关闭,KubeController 没有响应等,这是因为 Prometheus 节点导出器无法从控制平面上运行的服务获取指标。
以下是我们可以在 values.yaml 文件中禁用的一些警报。,
## Component scraping the kube controller manager
##
kubeControllerManager:
enabled: false
## Component scraping kube scheduler
##
kubeScheduler:
enabled: false
## Component scraping kube proxy
##
kubeProxy:
enabled: false
最后,为了更新 helm 部署,我们运行以下命令。
helm upgrade -f values.yaml prometheus-operator stable/prometheus-operator
如果是第一次运行 helm chart,也可以运行以下命令,
helm install stable/prometheus-operator \
— name prometheus-operator \
— namespace monitoring -f values.yaml
这些命令确保 helm chart 配置了 values.yaml 文件中添加的自定义更改。
清理:
假设您犯了一个错误并想要清除整个部署并重新启动,您将必须运行以下命令。,
#!/usr/bin/env bash
helm delete --purge prometheus-operator
kubectl delete namespace monitoring
kubectl delete crd alertmanagers.monitoring.coreos.com
kubectl delete crd podmonitors.monitoring.coreos.com
kubectl delete crd prometheuses.monitoring.coreos.com
kubectl delete crd prometheusrules.monitoring.coreos.com
kubectl delete crd servicemonitors.monitoring.coreos.com
如您所见,我们正在删除很多 CustomResourceDefinition。尽管它们是在 helm chart 部署期间创建的,但应单独删除它们。
如果您对 DevOps 或 Fullstack 感兴趣,并且发现像 ServiceMesh、基础设施自动化、事件循环和微前端这样的术语和我们一样令人兴奋,请发送电子邮件至join-tech@zolostays.com联系我们。我们很乐意带您出去喝杯咖啡☕ 讨论您与我们合作的可能性。

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献20439条内容
已为社区贡献20439条内容

所有评论(0)