
阿里Qwen3-Omni重磅发布:多模态AI进入“全优不偏科”时代
令人惊叹的是,Qwen3-Omni在音频和视频任务上取得统治级表现的同时,在文本和图像任务上的性能并未丝毫受损,甚至在某些任务上超越了参数量更大的单模态模型。这表明它不仅能看懂图片,还能进行基于视觉信息的复杂推理。最令人印象深刻的是,在需要同时理解音频和视觉信息的DailyOmni测试中,Qwen3-Omni获得75.8分,超过Gemini-2.5-Flash-Thinking的72.7分。处理视
在人工智能飞速发展的今天,多模态能力已成为通往通用人工智能(AGI)的必争之地。然而,长期以来,多模态大模型一直面临着一个难以逾越的障碍——“模态权衡”难题:当一个模型在图像识别上表现突出时,其文本理解能力往往不尽如人意;当语音处理能力增强时,视频分析性能却可能大打折扣。

这种“跷跷板效应”严重制约了AI系统的实用性和发展前景。直到2025年9月,阿里通义千问团队发布Qwen3-Omni,这一僵局被彻底打破。作为业界首个原生端到端全模态AI模型,Qwen3-Omni在不牺牲任何单模态性能的前提下,首次实现了文本、图像、音频和视频四大模态的全面领先,标志着多模态AI正式进入“全优不偏科”的新时代
Qwen3-Omni:
全能型AI的里程碑
Qwen3-Omni是阿里通义千问团队推出的突破性多模态模型,其核心目标是打造一个真正的“六边形战士”。该模型在36个音视频基准测试中,斩获32项开源模型最佳效果,其中22项达到总体SOTA水平,性能超越了Gemini-2.5-Pro等闭源模型。
令人惊叹的是,Qwen3-Omni在音频和视频任务上取得统治级表现的同时,在文本和图像任务上的性能并未丝毫受损,甚至在某些任务上超越了参数量更大的单模态模型。这一成就彻底推翻了“鱼与熊掌不可兼得”的传统认知,证明了全能且全优的多模态AI系统并非遥不可及。
该模型支持处理长达40分钟的音频内容,具备119种文本语言交互能力,并实现了234毫秒的端到端首包延迟,为实时交互应用奠定了坚实基础。
革命性架构:Thinker-Talker MoE设计
Qwen3-Omni最引人注目的创新是其独特的Thinker-Talker MoE架构。这一设计灵感来源于人类大脑的分工协作机制,将复杂的认知过程分解为两个相对独立但又紧密协作的部分。
Thinker组件作为模型的“思考者”,基于混合专家架构,负责处理文本、图像、音频、视频所有模态输入,并生成文本响应。它是模型处理逻辑、知识和推理的“大脑”,确保了在处理音视频任务时,核心的文本与图像能力不受干扰。
Talker组件则扮演“表达者”的角色,同样基于MoE架构,但专注于流式语音生成。它直接接收来自Thinker的高维特征,而非文本输出,这使得外部模块可以介入Thinker的文本输出,增强了系统可扩展性和安全性。
这种解耦设计的优势在于,Thinker可以专注于深度理解和推理,而Talker则可以优化生成效率和质量。两者通过MoE机制进行协调,既保持了专业化分工的优势,又确保了整体的一致性。
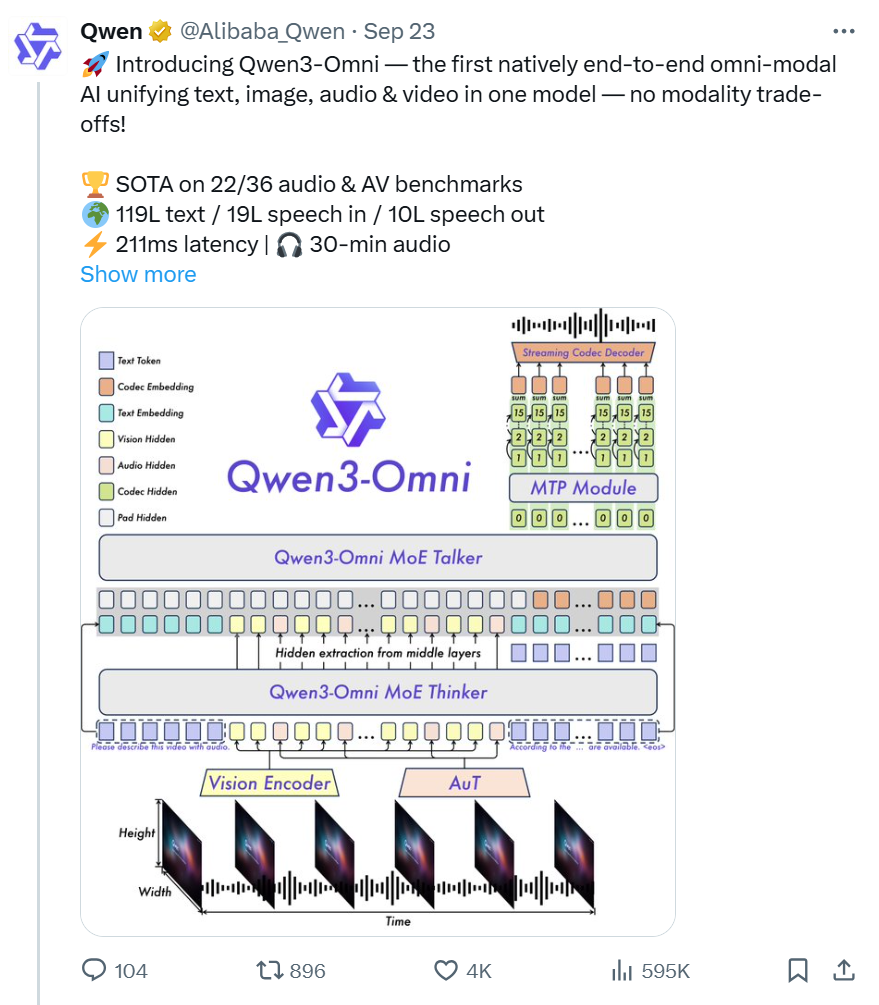
Qwen3-Omni通过Vision Encoder和AuT音频编码器将图文音视频输入编码为隐藏状态,由MoE Thinker负责文本生成与语义理解,再由MoE Talker结合MTP模块,实现超低延迟的流式语音生成。
关键技术突破:
五大创新铸就卓越性能
研究团队提出了一个完整的技术方案来复现o3类模型的能力,主要包括三个核心组件:
01
音频编码器AuT:重新定义音频理解
Qwen3-Omni开发了全新的AuT音频编码器,这个编码器从零开始,使用2000万小时的音频数据训练而成。如果一个人不停地听这些音频,需要连续听2283年才能听完。
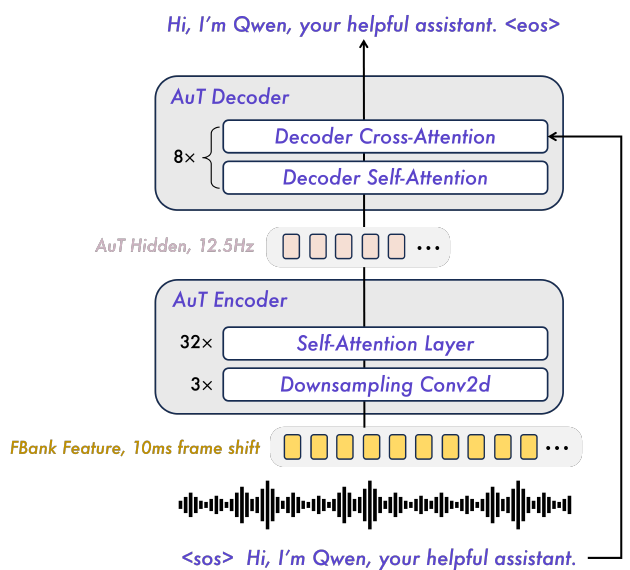
AuT采用基于Attention的编码器-解码器架构,采用块状窗口注意力机制,支持实时预填充缓存,有效降低了流式处理的延迟。通过Conv2D对Fbank特征进行8倍下采样,将音频token速率降低到12.5Hz,平衡了性能和实时效率。
02
多码本语音生成:让AI说话更自然
在语音合成方面,Qwen3-Omni采用了多码本创新技术,将语音信息分解为多个层次。第一层码本处理基本的语音内容,确保语义正确;第二层处理音调和语调变化;第三层处理更细致的声学特征,如音色特点、呼吸声等细节。
这种分层处理让系统可以先输出基本的语音内容,然后逐层添加更多细节。用户能够立即听到回应,而语音质量会在短时间内快速提升到最佳状态。
03
超低延迟流式处理:
234毫秒的极致响应
为实现极致的低延迟,模型在语音生成环节进行了多项创新。Talker采用多码本方案来表示语音,自回归预测第一个码本,然后通过轻量级MTP模块并行预测剩余残差码本。
系统还采用轻量级因果卷积网络替代计算密集的DiT作为声码器,显著降低了从声学编码到波形的合成延迟和计算量。这些优化使得系统可以在Talker生成第一个token后立即开始合成音频,无需等待上下文块,实现了理论上单并发234毫秒的端到端首包延迟。
04
多模态位置编码TM-RoPE:
理解时空关系
Qwen3-Omni引入了TM-RoPE技术,将传统的位置编码分解为时间、高度和宽度三个维度。处理视频时,AI不仅知道每个画面的时间位置,还知道画面中每个像素的空间位置,以及音频中每个片段对应的时间点。
这种设计让Qwen3-Omni能够处理任意长度的音视频输入,突破了以往系统只能处理固定长度片段的限制。现在它可以一次性理解长达40分钟的音频或视频内容,就像人类可以完整理解一部电影的情节发展一样。
05
三阶段训练策略:
循序渐进培养全能AI
Qwen3-Omni的训练分为三个渐进阶段:感知对齐阶段固定语言模型参数,只训练视觉和音频编码器;综合学习阶段解冻所有参数,使用约2万亿token的大规模数据集进行训练;长上下文扩展阶段将最大token长度从8192扩展到32768,增加长音频和长视频比例。
这种渐进式训练策略确保了模型既有扎实的基础感知能力,又有强大的综合跨模态理解能力。
性能测试数据:用实力证明领先地位
01
文本任务表现
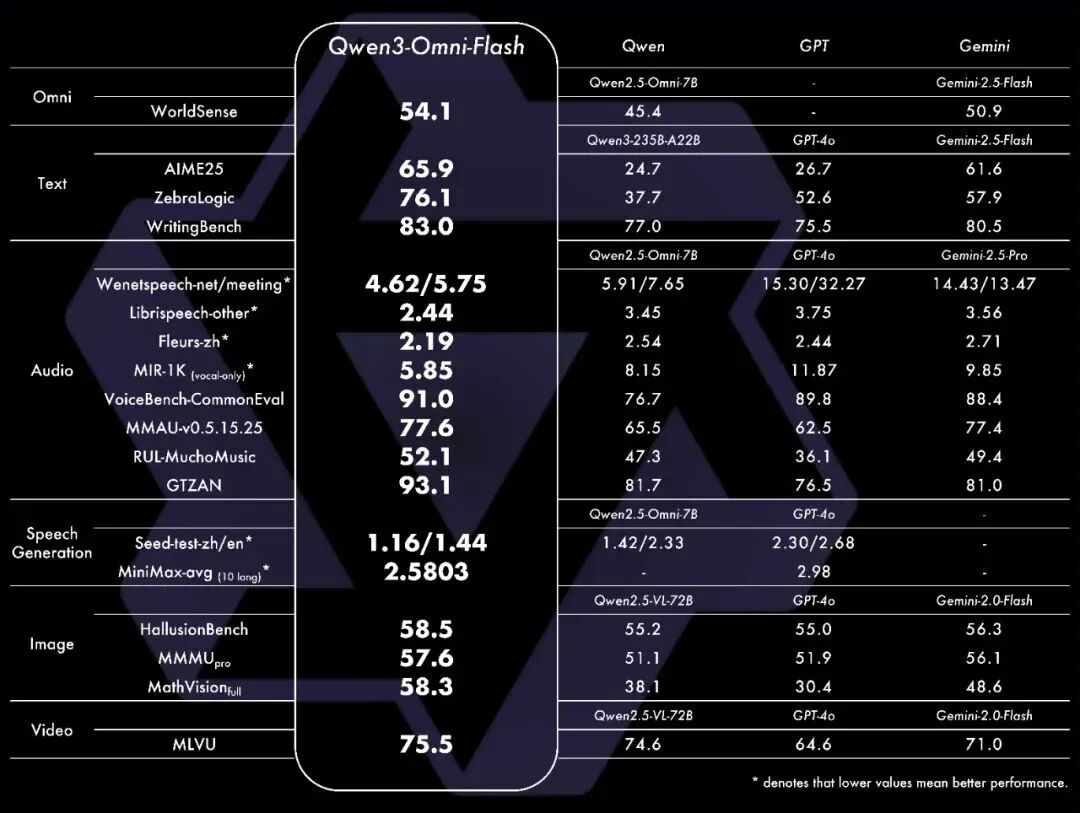
在权威文本评测中,Qwen3-Omni表现突出:在MMLU-Redux和AIME25测试中分别获得85.9和64.0的高分,与参数量更大的单模态模型Qwen3-235B-A22B表现接近。在GPQA推理测试中达到69.6分,超越GPT-4o的66.9分。
02
音频任务统治力
Qwen3-Omni在音频领域的表现尤为惊艳:中文语音识别WER仅4.62%,英文为5.75%,远低于Voxtral、Seed-ASR等专业系统。在音乐理解任务RUL-MuchoMusic测试中得分52.0,超过Gemini-2.5-Pro的49.4分
03
视觉任务稳定性
在视觉理解方面,Qwen3-Omni在MMMU-Pro理工科推理测试中获得57.6分,MathVista数学视觉任务拿到75.9分,均高于GPT-4o和Gemini-2.0-Flash。这表明它不仅能看懂图片,还能进行基于视觉信息的复杂推理。
04
跨模态协同效应
最令人印象深刻的是,在需要同时理解音频和视觉信息的DailyOmni测试中,Qwen3-Omni获得75.8分,超过Gemini-2.5-Flash-Thinking的72.7分。这证明了其在基础多模态整合和复杂推理方面的巨大潜力。
开启多模态AI新纪元
Qwen3-Omni的发布不仅是技术上的突破,更是多模态AI发展的重要里程碑。它证明了通过创新的架构设计和训练策略,AI系统完全可以实现全面发展而不偏科。这种“无性能衰减的统一多模态架构”为整个行业指明了前进方向。
随着Qwen3-Omni在Apache 2.0协议下全面开源,全球开发者可以基于这一领先技术构建更丰富的上层应用,加速多模态AI在各行各业的落地。从智能客服到在线教育,从内容创作到医疗辅助,Qwen3-Omni的强大能力将为无数场景注入新的活力。


中科创新烁智(CSCITech)
更多推荐



 3
3 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)