
详解元组、列表、字典、集合<一>
下面我们要了解以下数据类型元组列表字典集合一、元组(tuple)1.元组的创建(可以把元组看作一个容器,任何数据类型都可以放在里面)通过赋值方法创建元组In [5]: t = ("hello",2.3,2,True,{1:"hello",2:"world"},)In [6]: type(t)Out[6]: tupleIn [7]: t = (1)In [8]: type(t)O
下面我们要了解以下数据类型
- 元组
- 列表
- 字典
- 集合
一、元组(tuple)
1.元组的创建(可以把元组看作一个容器,任何数据类型都可以放在里面)
- 通过赋值方法创建元组
In [5]: t = ("hello",2.3,2,True,{1:"hello",2:"world"},)
In [6]: type(t)
Out[6]: tuple
In [7]: t = (1)
In [8]: type(t)
Out[8]: int
In [9]: t = (1,) #定义单个元组,一定要在这个元组后面加","
In [10]: type(t)
Out[10]: tuple
- 通过工厂方法创建元组
In [15]: t = tuple("hello")
In [16]: type(t)
Out[16]: tuple
2.元组的操作
- 索引
In [17]: t = ("hello",2.3,2,True,{1:"hello",2:"world"},)
In [18]: print t[0] #正向索引
hello
In [19]: print t[-1] #反向索引
{1: 'hello', 2: 'world'}
In [20]: print t[4][1] #取索引值为4的字典中key为1的value
hello- 切片
In [24]: t = ("hello",2.3,2,True,{1:"hello",2:"world"},)
In [25]: print t[2:4] #只取索引为2,3的元素
(2, True)
In [26]: print t[::-1] #逆转元组的元素
({1: 'hello', 2: 'world'}, True, 2, 2.3, 'hello')
- 连接
In [33]: t = (1,1.2,True,"hello")
In [34]: t1 = ((True,"hello",1),1+2j)
In [35]: print t1+t
((True, 'hello', 1), (1+2j), 1, 1.2, True, 'hello')
- 重复
In [39]: t = (1,1.2,True,"hello")
In [40]: print t*2 #自己指定重复次数
(1, 1.2, True, 'hello', 1, 1.2, True, 'hello')
- 成员操作符(这里常用于一些判断语句)
In [41]: t = (1,1.2,True,"hello")
In [42]: "hello" in t
Out[42]: True
In [43]: "hello" not in t
Out[43]: False
这里元组的一些操作,如索引、切片可以类比字符串的特性来学习,详见我的字符串详解这篇博客
- 元组的循环(元组是一个可迭代对象)
In [44]: vip = ("lucy","lili","xixi")
In [45]: for i in vip: #循环输出元组的各个元素
....: print i
....:
lucy
lili
xixi
test:端口扫描器
In [47]: ips = ("172.25.254.1","172,.25.254.13")
In [48]: ports = (20,21,80)
In [49]: for ip in ips: #for循环的嵌套
....: for port in ports:
....: print "[+] Scaning %s:%d" %(ip,port)
....:
[+] Scaning 172.25.254.1:20
[+] Scaning 172.25.254.1:21
[+] Scaning 172.25.254.1:80
[+] Scaning 172,.25.254.13:20
[+] Scaning 172,.25.254.13:21
[+] Scaning 172,.25.254.13:80
3.元组的常用方法
- count()
括号里是元组的value,返回这个value出现的次数,若是该value不在这个元组内,则返回0
In [60]: t = (1,2,3,4,4,"hello")
In [61]: t.count(4) #统计4出现的次数
Out[61]: 2
In [62]: t.count(6)
Out[62]: 0
- index()
查看该方法的帮助帮助文档,括号里可以填该元组的一个value,也可以选填该value的范围(start,stop),默认step为1是,范围是从索引为start到stop-1,返回的是该value的第一个索引
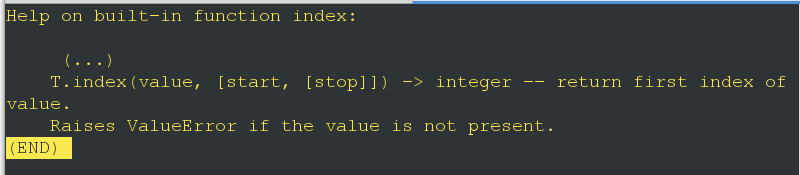
In [72]: t = (1,1,1,1,1,1)
In [73]: t.index(1) #不指定value的范围
Out[73]: 0
In [74]: t.index(1,1,3) #指定value的范围在索引为1-2之间
Out[74]: 1
In [75]: t.index(1,2,4) #指定该value的范围在索引为2-3之间
Out[75]: 2
4.元组可用的内置方法
- cmp()
两个元组间第一个元素ASCII码的比较,左边大于右边的元组,返回1,左边小于右边的元组,则返回-1,若是左右两边元组相等,则返回0
In [83]: cmp(("a",12),(1,2))
Out[83]: 1
- max()
同上,但返回的是值大的元组
In [85]: max(("hello",2),(3,4))
Out[85]: ('hello', 2)- min()
同上,但返回的是值小的元组
In [86]: min(("hello",2),(3,4))
Out[86]: (3, 4)
枚举的使用
采用元组套元组的方式,存储成绩信息:
scores = (
("Math",90),
("English",91),
("Chinese",93.1)
)利用枚举和for循环输出信息
print "科目编号\t科目名称\t\t成绩"
for index,value in enumerate(scores):
print "%3d\t\t%s\t\t%.2f" %(index,value[0],value[1])
结果
科目编 科目名称 成绩
0 Math 90.00
1 English 91.00
2 Chinese 93.10- zip()
令元组a的元素和元组b的元素一一对应,若是两个元组的元数个数不等,则以元素少的元组为标准,一一匹配完为止
In [99]: subjects = ("chinese","math","english")
In [100]: scores = (93.1,90)
In [101]: print zip(subjects,scores)
[('chinese', 93.1), ('math', 90)]
二、列表(list)
列表是打了激素的数组,因为数组只能存储同一种数据类型的结构,而列表可以存储是可以存储多种数据类型的结构
1.定义列表
In [103]: li = [(1,2,3),"hello", [True,"world",666],1.2]
In [104]: print li
[(1, 2, 3), 'hello', [True, 'world', 666], 1.2]
In [105]: type(li)
Out[105]: list
2.列表的操作(和元组比较)
- 索引(类似于元组,不赘述)
In [111]: li = [(1,2,3),"hello", [True,"world",666],1.2]
In [112]: print li[2][0]
True列表是可变数据类型,可以修改元素
In [106]: li = [(1,2,3),"hello", [True,"world",666],1.2]
In [107]: li[0] = 1 #令列表索引值为0的元素变为1
In [108]: li #列表被修改
Out[109]: [1, 'hello', [True, 'world', 666], 1.2]
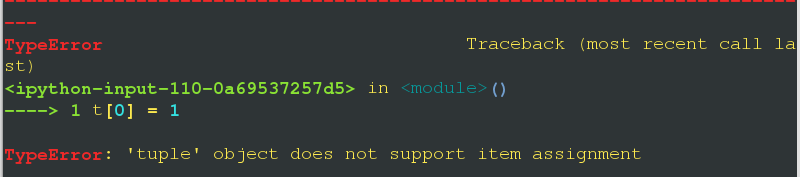
元组是不可变数据类型,不可以修改元素
In [110]: t =(0,1)
In [111]: t[0] = 1 #报错,如下图
切片(类似于元组,不赘述)
连接(类似于元组,不赘述)
重复(类似于元组,不赘述)
- 成员操作符(类似于元组,不赘述)
3.列表的增删查改
列表的一些方法,以下增删查改等会应用

- 增
append()追加元素到列表的最后
# ip 白名单
allow_ip = ["172.25.254.1","172.25.254.3", "172.25.254.26" ]
allow_ip.append("172.25.254.250")
print allow_ip
执行效果:
['172.25.254.1', '172.25.254.3', '172.25.254.26', '172.25.254.250']insert()增加元素到列表的指定位置
allow_ip = ["172.25.254.1","172.25.254.3", "172.25.254.26" ]
allow_ip.insert(0, "192.168.1.253")
执行效果:
['192.168.1.253', '172.25.254.1', '172.25.254.3', '172.25.254.2
6', '172.25.254.250']extend()增加多个元素到列表最后
# ip 白名单
allow_ip = ["172.25.254.1","172.25.254.3", "172.25.254.26" ]
allow_ip.extend(["172.25.254.45", "172.25.56.21"])
执行效果:
['192.168.1.253', '172.25.254.1', '172.25.254.3', '172.25.254.2
6', '172.25.254.250', '172.25.254.45', '172.25.56.21']- 删
1.删除列表中遇到的第一个 value 值,如果该value值不存在,则报错
#语法格式:li.remove(value)
li = [1,2,45,6,8,0,1]
li.remove(1)
print li
执行效果:
[2, 45, 6, 8, 0, 1]
2.删除列表中第 i 个索引值;
#语法格式: del li[index]
li = [1,2,45,6,8,0,1]
del li[5]
print li
执行效果:
[1, 2, 45, 6, 8, 1]
test:删除除了第一个元素之外的其他索引值
li = [1,2,45,6,8,0,1]
del li[1::]
print li
执行效果:
[1]
3.根据索引删除一个元素,并返回该元素,如果括号内没有值,默认删除最后一个元素,若是超过范围的index,则报错
#语法格式:li.pop(index)
li = [1,2,45,6,8,0,1]
li.pop(1)
print li
运行效果:
[1, 45, 6, 8, 0, 1]
4.删除列表对象
li = [1,2,45,6,8,0,1]
del li- 查
1.统计某个元素在列表中出现的次数
li = [1,2,45,6,8,0,1]
print li.count(1)
运行效果:
2
2.找到某个值在列表中的索引值
li = [1,2,45,6,8,0,1]
print li.index(1,1) #value值为1,该值范围的起始索引为1
运行效果:
6- 改
# 通过列表的索引,对列表某个索引值重新赋值
li = [1,2,45,6,8,0,1]
li[1] = True
print li
运行效果:
[1, True, 45, 6, 8, 0, 1]ok,我们详讲了增删查改所用到的一些方法,那我们还有sort()和reverse()方法没有详讲,那下面就可以详讲一下这两个方法
- sort() — 排序
若都是数字,按照数字大小排序 ;若是字母的话,按照 ASCII 码来排序;
ps:查看对应的 ASCII 码 ? ord(‘a’)
li = [1,2,45,6,8,0,1]
li.sort()
print li
运行效果:
[0, 1, 1, 2, 6, 8, 45]- reverse()—逆转
我们实现逆转除了前面讲的切片方式,也可以使用改方法
li = [1,2,45,6,8,0,1]
li.reverse()
print li
运行效果:
[1, 0, 8, 6, 45, 2, 1]4.元组讲了那么多,那我们来一道练习题吧~
用户登录程序版本:
- 用户名和密码分别保存在列表中;
- 用户登录时,判断该用户是否注册;
- 用户登录时,为防止黑客暴力破解, 仅有三次机会;
- 如果登录成功,显示登录成功(exit(), break).
知识点学习:
python中特有的while….else…语句
如果满足while后面的语句,执行while循环的程序, 如果不满足,执行else里面的程序.
运行效果:

代码如下:
usernames = ["freya","lili"]
passwords = ["123","456"]
trycount = 0
while trycount < 3:
username = raw_input("username:").strip()
if not username in usernames:
print "用户名不存在!!!"
break
password = raw_input("password:").strip()
index = usernames.index(username)
if password == passwords[index]:
print "登录成功!!!"
break
else:
print "密码不正确!!!"
trycount +=1
else:
print "已超过三次,稍后再试!!!"5.列表构建栈和队列数据结构
- 栈—–先进后出(LIFO-first in last out)
类似于往箱子里面放书
代码如下:
#定义一个空列表
list = []
info = """
***********栈操作***********
1).入栈
2).出栈
3).栈长度
4).查看栈
5).退出
"""
while True:
print info
choice = raw_input("your choice:").strip()
if choice == "1":
value = raw_input("入栈元素:").strip()
list.append(value) #使用追加的方法,新入栈的元素就在栈尾
print "%s成功入栈!!!" %(value)
if choice == "2":
if not list:
print "栈为空!!!"
continue
value = list.pop() #该删除方式没有参数时默认删除最后一个栈元素
print "%s出栈成功!!!" %(value)
if choice == "3":
if not list:
print "栈为空!!!"
continue
print "栈的长度为%d" %(len(list)) #使用内置方法len()
if choice == "4":
if not list:
print "栈为空!!!"
continue
print "序号\t栈元素"
for index,value in enumerate(list):
print "%d\t%s" %(index,value)
if choice == "5":
exit()
else:
print "输入合法操作数!!!"- 队列—–先进先出(FIFO)
类似于去餐厅买饭排队
代码如下:
list = []
info = """
***********队列操作***********
1).入队
2).出队
3).队长度
4).查看队
5).退出
"""
while True:
print info
choice = raw_input("your choice:").strip()
if choice == "1":
value = raw_input("入队元素:").strip()
list.append(value)
print "%s成功入队!!!" % (value)
if choice == "2":
if not list:
print "队为空!!!"
continue
value = list.pop(0) #由于队是先进先出,指定要删除的value的索引号,可以达到该效果
print "%s出队成功!!!" % (value)
if choice == "3":
if not list:
print "队为空!!!"
continue
print "队的长度为%d" % (len(list))
if choice == "4":
if not list:
print "队为空!!!"
continue
print "序号\t队元素"
for index, value in enumerate(list):
print "%d\t%s" % (index, value)
if choice == "5":
exit()
else:
print "输入合法操作数!!!"ok~,总结栈和队的操作,就是在出队和出栈时候pop()使用上的小小区别
未完待续~~~~

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)