微服务之分布式跟踪系统(springboot+zipkin)
一、zipkin是什么
zipkin是一个开放源代码分布式的跟踪系统,由Twitter公司开源,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。它的理论模型来自于Google Dapper 论文。
每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,显示了多少跟踪请求通过每个服务,该系统让开发者可通过一个 Web 前端轻松的收集和分析数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。
二、什么需要分布式跟踪系统(zipkin)
当代的互联网的服务,通常都是用复杂的、大规模分布式集群来实现的。特别是随着微服务架构和容器技术的兴起(加速企业敏捷,快速适应业务变化,满足架构的高可用和高扩展),互联网应用往往构建在不同的服务之上,这些服务,有可能是由不同的团队开发、可能使用不同的编程语言来实现、有可能布在了几千台服务器,横跨多个不同的数据中心。因此,就需要一些可以帮助理解系统行为、用于快速分析性能问题的工具。先是Google开发其分布式跟踪系统并且发表了Dapper 论文,然后由Twitter参照Dapper论文设计思想开发zipkin分布式跟踪系统,同时开源出来。
zipkin通过采集跟踪数据可以帮助开发者深入了解在分布式系统中某一个特定的请求时如何执行的。假如说,我们现在有一个用户请求超时,我们就可以将这个超时的请求调用链展示在UI当中。我们可以很快度的定位到导致响应很慢的服务究竟是什么。如果对这个服务细节也很很清晰,那么我们还可以定位是服务中的哪个问题导致超时。同时,通过服务调用链路能够快速定位系统的性能瓶颈。
三、zipkin下载与启动
在本节中,我们将介绍下载和启动zipkin实例,以便在本地检查zipkin。有三种安装方法:使用官网自己打包好的Jar运行,Docker方式或下载源代码自己打包Jar运行(因为zipkin使用了springboot,内置了服务器,所以可以直接使用jar运行)。zipkin推荐使用docker方式运行,我后面会专门写一遍关于docker的运行方式,而源码运行方式好处是有机会体验到最新的功能特性,但是可能也会带来一些比较诡异的坑,所以不做讲解,下面我直接是使用官网打包的jar运行过程:
(1) 下载jar文件
- wget -O zipkin.jar 'https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec'
不过,我在运行的过程中,发现无法下载。然后我通过翻墙软件,下载了其最新的jar文件(zipkin-server-1.17.1-exec.jar),我这里也提供其下载地址。
(2) 启动实例
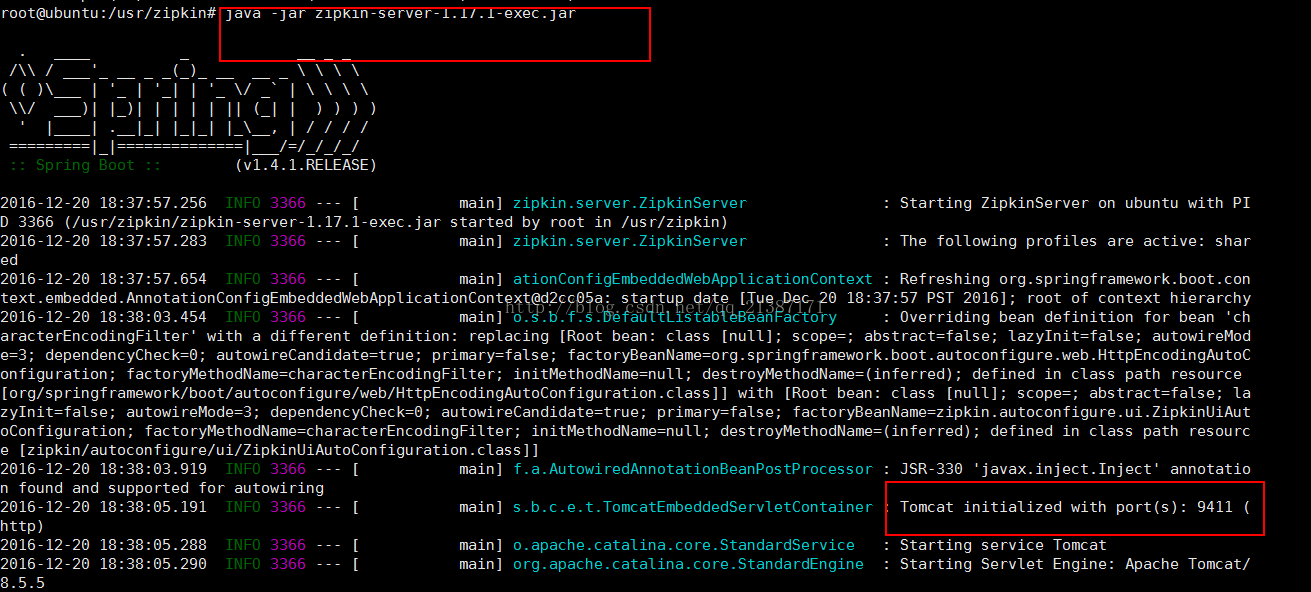
Java-jar zipkin-server-1.17.1-exec.jar或者java -jar zipkin.jar(注意需要安转JDK8或者以上的版本),启动成功如下图所示:
(3) 查看运行效果
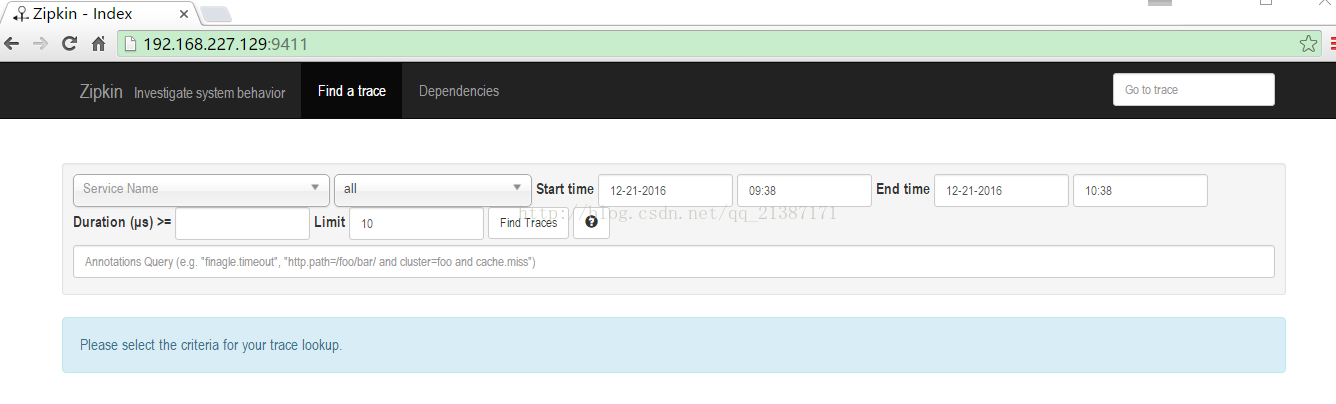
通过上图,我们发现zipkin使用springboot,并且启动的端口为9411,然后我们通过浏览器访问,效果如下:
四、zipkin的架构与核心概念
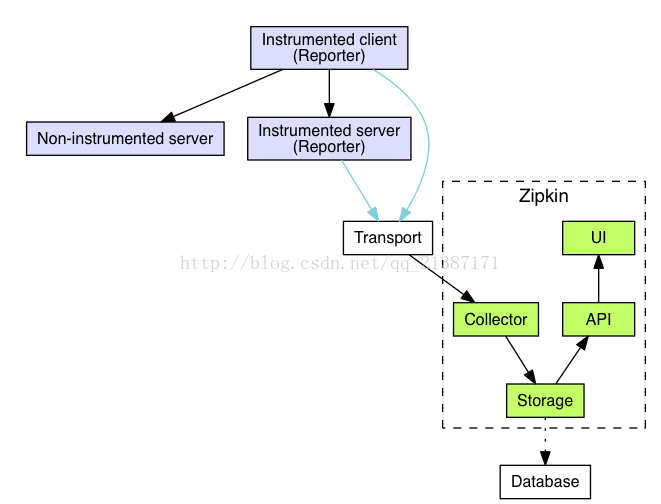
将数据发送到zipkin的已检测应用程序中的组件称为Reporter。它通过几种传输方式之一将跟踪数据发送到zipkin收集器,zipkin收集器将跟踪数据保存到存储器。稍后,存储由API查询以向UI提供数据。为了保证服务的调用链路跟踪,zipkin使用传输ID,例如,当正在进行跟踪操作并且它需要发出传出http请求时,会添加一些headers信息以传播ID,但它不能用于发送详细信息(操作名称、数据等)。其架构图如下所示:
A、Span
基本工作单元,一次链路调用创建一个span,通过一个64位ID标识它,span通过还有其他的数据,例如描述信息,时间戳,key-value对的(Annotation)tag信息,parent-id等,其中parent-id 可以表示span调用链路来源,通俗的理解span就是一次请求信息。
B、 Trace
类似于树结构的Span集合,表示一条调用链路,存在唯一标识。
C、 Annotation
注解,用来记录请求特定事件相关信息(例如时间),通常包含四个注解信息:
(1)cs - ClientStart,表示客户端发起请求
(2)sr - Server Receive,表示服务端收到请求
(3)ss - Server Send,表示服务端完成处理,并将结果发送给客户端
(4)cr - Client Received,表示客户端获取到服务端返回信息
D、 Transport
收集被trace的services的spans,并且传输给zipkin的collector,有三个主要传输:HTTP,Kafka和Scribe。
E、 Collector
zipkincollector会对一个到来的被trace的数据(span)进行验证、存储并设置索引。
F、 Storage
存储,zipkin默认的存储方式为in-memory,即不会进行持久化操作。如果想进行收集数据的持久化,可以存储数据在Cassandra,因为Cassandra是可扩展的,有一个灵活的模式,并且在Twitter中被大量使用,我们使这个组件可插入。除了Cassandra,我们原生支持ElasticSearch和MySQL。其他后端可能作为第三方扩展提供。
G、QueryService
一旦数据被存储和索引,我们需要一种方法来提取它。查询守护程序提供了一个用于查找和检索跟踪的简单JSON API,此API的主要使用者是WebUI。
H、 WebUI
展示页面,提供了一个漂亮的界面来查看痕迹。 Web UI提供了一种基于服务,时间和注释查看trace的方法(通过Query Service)。注意:在UI中没有内置的身份验证。
五、分布式跟踪系统实践(springboot+zipkin)
5.1场景设置与分析
现在有一个服务A调用服务B,服务B又分别调用服务C和D,整个链路过程的关系图如下所示:

其调用工作流程调用链路详细图:
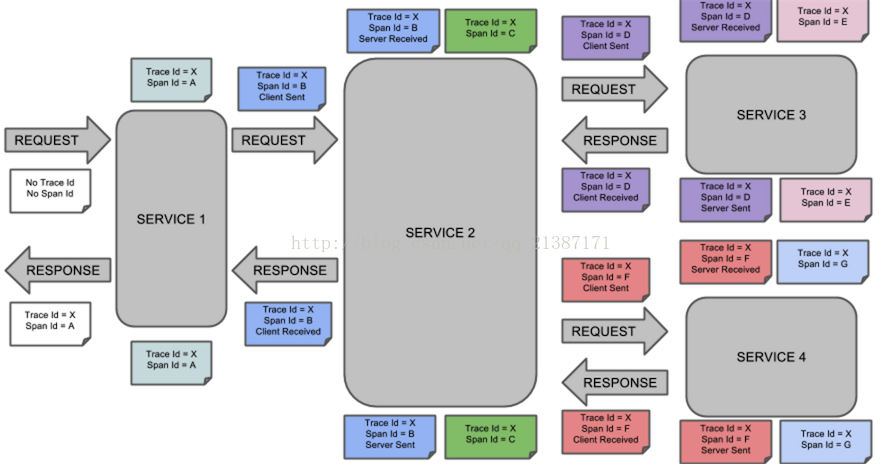
上图表示一请求链路,一条链路通过TraceId唯一标识,Span标识发起的请求信息,各span通过parent id 关联起来,parentId==null,表示该span就是root span,如下图所示:
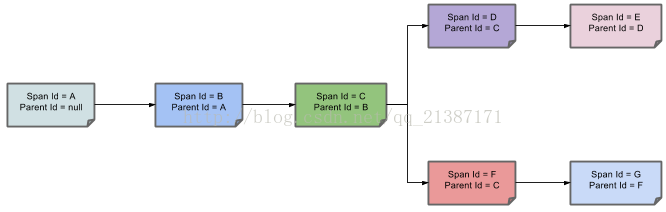
zipkin提供了各种语言的客户端(Java、Go、Scala、Ruby、JavaScript),使用它们想zipkin汇报数据。
5.2 代码编写
下面我以Java的客户端Brave为例完成上面四个服务调用代码编写,源代码下载地址:https://github.com/dreamerkr/mircoservice.git文件夹springboot+zipkin下面,具体如下:
(1) serivce1
a、 springboot启动类
- <span style="font-size:14px;">@SpringBootApplication
- @EnableAutoConfiguration
- public class Application {
-
- public static void main(String[] args) {
- SpringApplication.run(Application.class, args);
- }
- }</span>
b、zipkin收集与配置类
-
-
-
-
-
-
- @Configuration
- public class ZipkinConfig {
-
-
- @Bean
- public SpanCollector spanCollector() {
- Config config = HttpSpanCollector.Config.builder()
- .compressionEnabled(false)
- .connectTimeout(5000)
- .flushInterval(1)
- .readTimeout(6000)
- .build();
- return HttpSpanCollector.create("http://localhost:9411", config, new EmptySpanCollectorMetricsHandler());
- }
-
-
- @Bean
- public Brave brave(SpanCollector spanCollector){
- Builder builder = new Builder("service1");
- builder.spanCollector(spanCollector);
- builder.traceSampler(Sampler.create(1));
- return builder.build();
- }
-
-
-
- @Bean
- public BraveServletFilter braveServletFilter(Brave brave) {
- BraveServletFilter filter = new BraveServletFilter(brave.serverRequestInterceptor(),
- brave.serverResponseInterceptor(), new DefaultSpanNameProvider());
- return filter;
- }
-
-
- @Bean
- public OkHttpClient okHttpClient(Brave brave){
- OkHttpClient httpClient = new OkHttpClient.Builder()
- .addInterceptor(new BraveOkHttpRequestResponseInterceptor(
- brave.clientRequestInterceptor(),
- brave.clientResponseInterceptor(),
- new DefaultSpanNameProvider())).build();
- return httpClient;
- }
- }
c、 服务1业务代码
- @Api("service的API接口")
- @RestController
- @RequestMapping("/service1")
- public class ZipkinBraveController {
-
-
- @Autowired
- private OkHttpClient client;
-
- @ApiOperation("trace第一步")
- @RequestMapping("/test")
- public String service1() throws Exception {
- Thread.sleep(100);
- Request request = new Request.Builder().url("http://localhost:8082/service2/test").build();
- Response response = client.newCall(request).execute();
- return response.body().string();
- }
-
- }
d、pom文件
- <dependencies>
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter</artifactId>
- <version>1.3.5.RELEASE</version>
- </dependency>
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-web</artifactId>
- <version>1.3.5.RELEASE</version>
- </dependency>
- <dependency>
- <groupId>io.zipkin.brave</groupId>
- <artifactId>brave-core</artifactId>
- <version>3.9.0</version>
- </dependency>
- <!-- <dependency>
- <groupId>io.zipkin.reporter</groupId>
- <artifactId>zipkin-reporter-urlconnection</artifactId>
- <version>0.2.0</version>
- </dependency>
- -->
- <dependency>
- <groupId>io.zipkin.brave</groupId>
- <artifactId>brave-spancollector-http</artifactId>
- <version>3.9.0</version>
- </dependency>
- <dependency>
- <groupId>io.zipkin.brave</groupId>
- <artifactId>brave-web-servlet-filter</artifactId>
- <version>3.9.0</version>
- </dependency>
- <dependency>
- <groupId>io.zipkin.brave</groupId>
- <artifactId>brave-okhttp</artifactId>
- <version>3.9.0</version>
- </dependency>
-
- <dependency>
- <groupId>io.springfox</groupId>
- <artifactId>springfox-swagger2</artifactId>
- <version>2.6.1</version>
- </dependency>
- <dependency>
- <groupId>io.springfox</groupId>
- <artifactId>springfox-swagger-ui</artifactId>
- <version>2.6.1</version>
- </dependency>
- </dependencies>
e、application.properties
- application.name: service1
-
- server.port: 8081
(2) serivce2
pom文件和启动类与service1是一样的,配置类ZipkinConfig把service1改成service2,application.properties改name为service2、改端口为8082,服务2业务代码如下:
- @Api("service的API接口")
- @RestController
- @RequestMapping("/service2")
- public class ZipkinBraveController {
-
- @Autowired
- private OkHttpClient client;
-
- @ApiOperation("trace第二步")
- @RequestMapping("/test")
- public String service1() throws Exception {
- Thread.sleep(200);
- Request request3 = new Request.Builder().url("http://localhost:8083/service3/test").build();
- Response response3 = client.newCall(request3).execute();
-
- Request request4 = new Request.Builder().url("http://localhost:8084/service4/test").build();
- Response response4 = client.newCall(request4).execute();
- return response3.toString()+":"+response4.toString();
- }
-
- }
(3) serivce3
pom文件和启动类与service1是一样的,配置类ZipkinConfig把service1改成service3,application.properties改name为service3、改端口为8083,服务3业务代码如下:
- @Api("service的API接口")
- @RestController
- @RequestMapping("/service3")
- public class ZipkinBraveController {
-
- @ApiOperation("trace第三步")
- @RequestMapping("/test")
- public String service1() throws Exception {
- Thread.sleep(300);
- return "service3";
- }
-
- }
- }
(4) serivce4
pom文件和启动类与service1是一样的,配置类ZipkinConfig把service1改成service4,application.properties改name为service4、改端口为8084,服务4业务代码如下:
- @Api("service的API接口")
- @RestController
- @RequestMapping("/service4")
- public class ZipkinBraveController {
-
- @ApiOperation("trace第四步")
- @RequestMapping("/test")
- public String service1() throws Exception {
- Thread.sleep(300);
- return "service4";
- }
-
- }
5.3运行效果
(1)分别启动每个服务,然后访问服务1,浏览器访问(http://localhost:8081/service1/test)
(2)输入zipkin地址,每次trace的列表
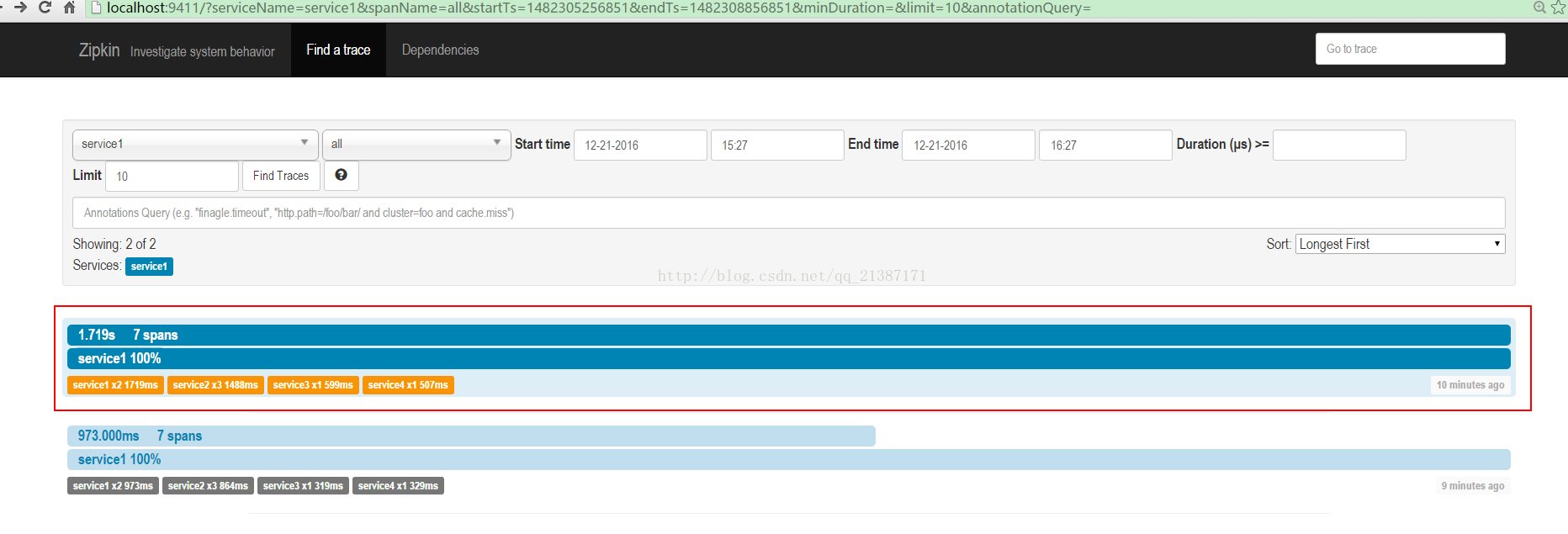
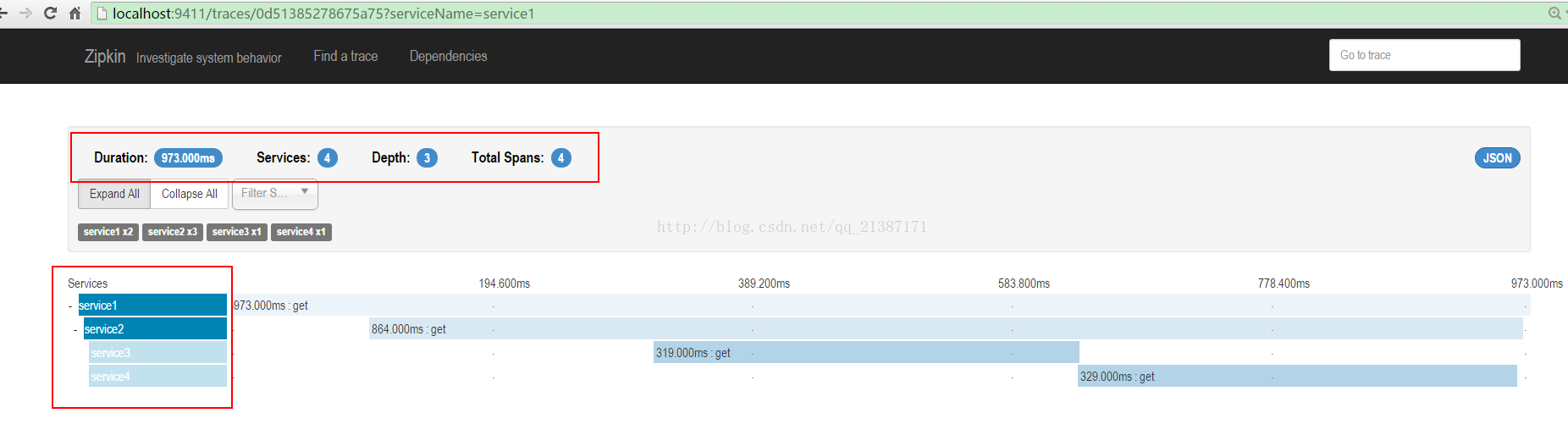
点击其中的trace,可以看trace的树形结构,包括每个服务所消耗的时间:
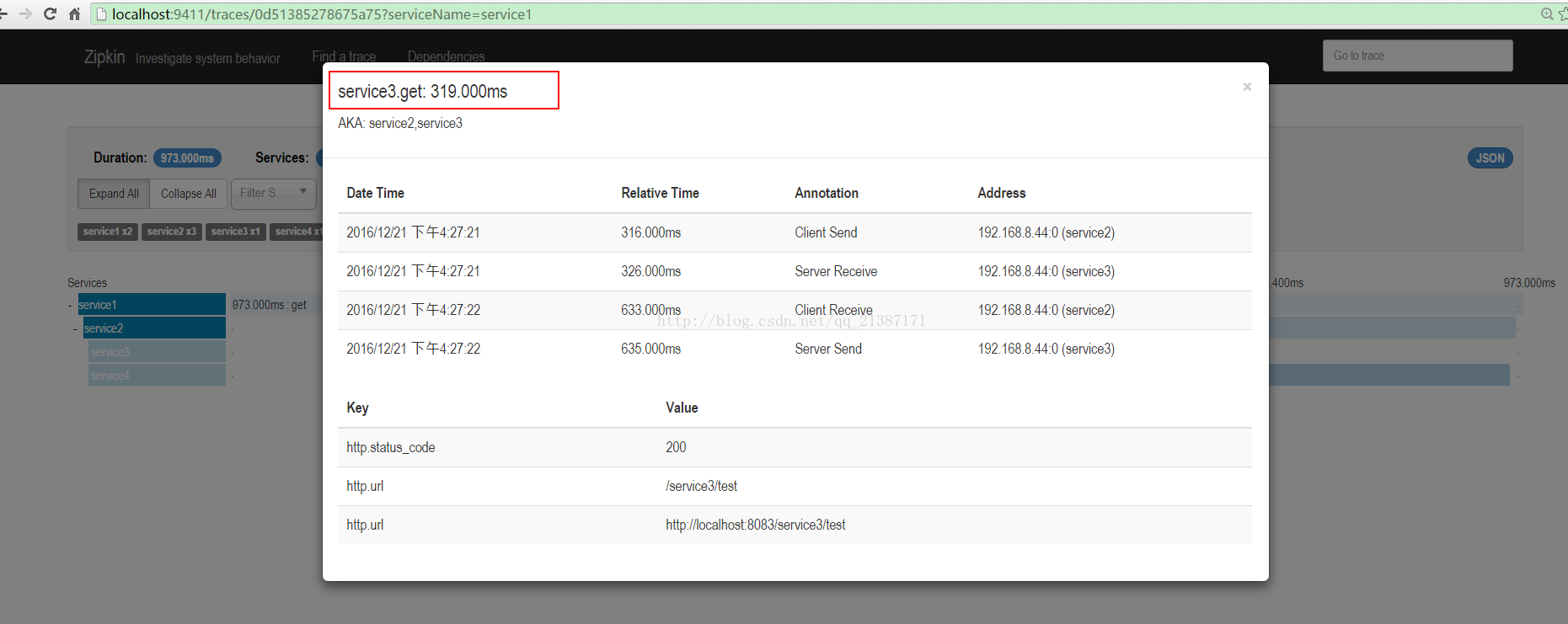
点击每个span可以获取延迟信息:
同时可以查看服务之间的依赖关系:
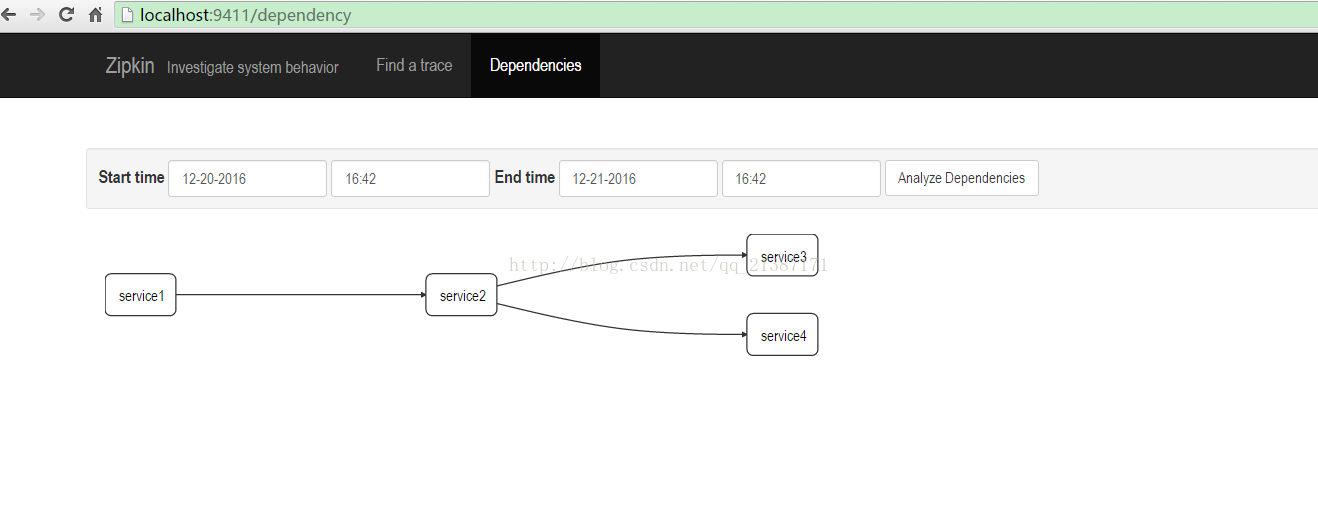
本篇主要与大家分享zipkin进行简单的服务分布式跟踪,但是收集的数据都在内存里面,重新启动后数据丢失,但是zipkin还提供了Cassandra、mysql、ElasticSearch等多种存储方式,下面章节做讲解《微服务之分布式跟踪系统(springboot+zipkin+mysql)》




 0
0 0
0


 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)