
基于Jenkins的自动构建系统开发
1 绪论1.1 课题的研究背景随着IT行业的不断发展,软件开发的复杂度也随着不断提高。与此同时,软件的开发团队也越来越庞大,而如何更好地协同整个团队进行高效准确的工作,从而确保软件开发的质量已经慢慢成为了开发过程中不可回避的问题。在软件开发中,不同的功能模块一般由不同的开发成员负责,同一功能模块的各层代码也可能是不同的开发成员编写,经验告诉我们,模块之间的问题是最难解决的
1 绪论
1.1 课题的研究背景
随着IT行业的不断发展,软件开发的复杂度也随着不断提高。与此同时,软件的开发团队也越来越庞大,而如何更好地协同整个团队进行高效准确的工作,从而确保软件开发的质量已经慢慢成为了开发过程中不可回避的问题。
在软件开发中,不同的功能模块一般由不同的开发成员负责,同一功能模块的各层代码也可能是不同的开发成员编写,经验告诉我们,模块之间的问题是最难解决的,也是最耗费时间的。它需要多个开发人员相互协作找出问题,而协作过程中的沟通所消耗的时间成本是相当高的。而且还可能因为沟通的不足导致模块返工。
事实上,在持续集成被提出来之前的传统开发方法中常常出现这种情况:由不同程序员开发的单个小模块可以单独工作,但把它们集成为一个大的系统则可能失败。而且集成失败往往是把集成放在开发周期后期,甚至是在项目快结束前单列的一个“总装阶段”。众所周知,问题发现的越晚,其修复的成本也就越高,耗时越长,而且经过新的修复工作后可能诞生新的错误,因此整个系统需要再次进行集成和测试,从而导致整个软件的生产周期漫长且不可预知。
上述传统开发方法带来的高集成成本和长开发周期将直接带来了显著的影响:首先是无法为客户提供稳定的产品,其次降低了开发团队的士气。开发团队士气降低将进一步导致产品开发的不顺,进而形成开发的恶性循环。
为了解决由传统开发方法带来的弊端,人们开始采用“早集成、常集成”的持续集成策略。从最初的分阶段集成,到后来的“每日构建”[1] , 再发展到现在的持续集成(Continuous Integration,CI)[2]。持续集成通过自动化构建、自动化测试以及自动化部署加上较高的集成频率保证了开发系统中的问题能迅速被发现和修复,降低了集成失败的风险,使得系统在开发中始终保持在一个稳定健康的集成状态。
1.2 课题的意义和目的
研究基于Jenkins的软件自动构建系统的目的与意义在于:
首先,持续集成服务器是自动构建系统中关键的一部分。Jenkins是一个开源项目,它提供了一种易于使用的持续集成系统,使开发者从繁杂的集成中解脱出来,专注于更为重要的业务逻辑实现上。同时 Jenkins 能实施监控集成中存在的错误,提供详细的日志文件和提醒功能,还能用图表的形式形象地展示项目构建的趋势和稳定性。[3]Jenkins还能通过自定义安装插件来实现多种多样的功能,目前Jenkins拥有超过600种的插件,基本可以满足你的大多数需求。Jenkins可以算是最近比较热门的持续集成服务器,许多公司和开源项目都在使用Jenkins,比如Facebook、GitHub、Yahoo!、Apache、Ubuntu等。
其次,中小型软件企业数量众多,其开发团队和项目也大多是中小型的,因此有大量可以采用轻量开发方法的空间。持续集成是轻量开发方法中一个非常重要的实践,是保证团队开发步调一致和保证开发质量的重要手段。将持续集成指导下的自动构建系统融合到开发过程中将大幅度提高软件质量,降低开发成本[4]。
再者,可将自动构建系统引入高校计算机类专业的教育环节中。一方面老师可以通过实际的软件项目来引导学生体验软件开发的实际流程,提高学生的兴趣和实践能力。另一方面也能让外界对校内进行的开发项目有直观的认识,提升学校知名度。
1.3 本课题的研究范围
本课题研究主体确定为基于Jenkins的软件自动构建系统。主要对持续集成这一实践进行调查和分析,研究如何实现软件的自动化编译,自动化测试,自动化部署以及文档自动化生成及发布。在此基础上结合Jenkins持续集成服务器和Gerrit代码源码管理系统实现一个稳定的软件自动构建系统。
2 持续集成相关理论
2.1 极限编程的概述
2.1.1 极限编程的产生
2001年,为了解决许多公司的软件团队陷入不断增长的过程泥潭,一批业界专家一起概括出了一些可以让软件开发团队具有快速工作、响应变化能力的价值观和原则,他们称自己为敏捷联盟。敏捷开发过程的方法很多,主要有:SCRUM,Crystal,特征驱动软件开发(Feature Driven Development,简称FDD),自适应软件开发(Adaptive Software Development,简称ASD),以及最重要的极限编程(eXtreme Programming,简称XP)。极限编程(XP)是于1998年由Smalltalk社群中的大师级人物Kent Beck首先倡导的。
2.1.2 极限编程
极限编程(XP)是敏捷方法中最著名的一个。它是由一系列简单却互相依赖的实践组成。这些实践结合在一起形成了一个胜于部分结合的整体。
下面是极限编程的有效实践:
(1)完整团队 XP项目的所有参与者(开发人员、客户、测试人员等)一起工作在一个开放的场所中,他们是同一个团队的成员。这个场所的墙壁上随意悬挂着大幅的、显著的图表以及其他一些显示他们进度的东西。
(2)计划游戏计划是持续的、循序渐进的。每2周,开发人员就为下2周估算候选特性的成本,而客户则根据成本和商务价值来选择要实现的特性。
(3)客户测试作为选择每个所期望的特性的一部分,客户可以根据脚本语言来定义出自动验收测试来表明该特性可以工作。
(4)简单设计团队保持设计恰好和当前的系统功能相匹配。它通过了所有的测试,不包含任何重复,表达出了编写者想表达的所有东西,并且包含尽可能少的代码。
(5)结对编程所有的产品软件都是由两个程序员、并排坐在一起在同一台机器上构建的。
(6)测试驱动开发编写单元测试是一个验证行为,更是一个设计行为。同样,它更是一种编写文档的行为。编写单元测试避免了相当数量的反馈循环,尤其是功功能能验证方面的反馈循环。程序员以非常短的循环周期工作,他们先增加一个失败的测试,然后使之通过。
(7)改进设计随时利用重构方法改进已经腐化的代码,保持代码尽可能的干净、具有表达力。
(8)持续集成团队总是使系统完整地被集成。一个人拆入(Check in)后,其它所有人责任代码集成。
(9)集体代码所有权任何结对的程序员都可以在任何时候改进任何代码。没有程序员对任何一个特定的模块或技术单独负责,每个人都可以参与任何其它方面的开发。
(10)编码标准,系统中所有的代码看起来就好像是被单独一人编写的。
(11)隐喻,将整个系统联系在一起的全局视图;它是系统的未来影像,是它使得所有单独模块的位置和外观变得明显直观。如果模块的外观与整个隐喻不符,那么你就知道该模块是错误的。
(12)可持续的速度,团队只有持久才有获胜的希望。他们以能够长期维持的速度努力工作,他们保存精力,他们把项目看作是马拉松长跑,而不是全速短跑。 极限编程是一组简单、具体的实践,这些实践结合在形成了一个敏捷开发过程。极限编程是一种优良的、通用的软件开发方法,项目团队可以拿来直接采用,也可以增加一些实践,或者对其中的一些实践进行修改后再采用。
2.1.3 极限编程的核心价值
极限编程中有四个核心价值是我们在开发中必须注意的:沟通(Communication)、简单(Simplicity)、反馈(Feedback)、勇气(Courage)、此外还扩展了第五个价值观:谦逊(Modesty)。 XP用“沟通、简单、反馈、勇气和谦逊”来减轻开发压力和包袱;无论是术语命名、专著叙述内容和方式、过程要求,都可以从中感受到轻松愉快和主动奋发的态度和气氛。这是一种帮助理解和更容易激发人的潜力的手段。XP用自己的实践,在一定范围内成功地打破了软件工程“必须重量”才能成功的传统观念。
2.2 持续集成
2.2.1 经典软件开发方法的集成方式比较
软件集成是一个软件开发过程,在这个过程中,通过管理和技术手段,将已开发出的软件组件或代码单元,整合成完整的软件产品,并对该产品进行测试和验证以确保产品符合用户需求,通常也被称作系统集成或集成测试。因此集成方式对于软件开发的重要性不言而喻。下面对几种经典的软件开发模型的集成方式进行比较:
瀑布模型[5]是最早出现的软件开发模型,其过程是从上一项活动接收该项活动的工作对象作为输入,利用这一输入实施该项活动应完成的内容给出该项活动的工作成果,并作为输出传给下一项活动。同时评审该项活动的实施,若确认,则继续下一项活动;否则返回前面,甚至更前面的活动。如下图所示。
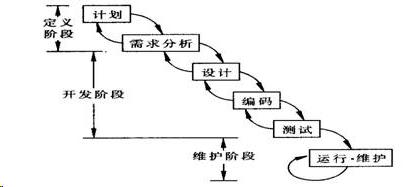
图2. 1 瀑布模型
从上可知瀑布模型本质是一种线性顺序模型。在开始下一阶段工作前必须完成上一阶段的所有工作。而后一阶段出现了问题要从前一阶段重新确认解决。所以当问题发现的越晚,解决问题所需要付出的代价就越高。
相对应的,瀑布模型的集成方式可总结为两个步骤:首先是每个模块的需求分析、设计、编码、测试和调试,相当于单元模块开发;然后是将各单元模块进行系统集成。
各个模块在系统集成前并没有一起工作过,因此首次系统集成必然出现许多新问题,一旦出现问题,则所有模块都需要进行调试。一般把这种集成方式成为Big-Bang集成。这种集成方式前提是模块之间的独立性较高,而现代软件开发中开发人员之间的相互合作依赖程度越来越高,几乎不可能存在相互独立的模块。而且很多bug都是在后期的集成中才发现的,这样将直接导致高昂的系统修复代价,严重影响了开发进度,同时使得项目开发进度和现状难以预估。因此Big-Bang集成方式只适用于模块间相互独立的小型项目。
随后Rational公司提出了Rational统一过程(简称RUP)。RUP方法中,通过迭代将整个项目的开发目标划分成为一些更易于完成和达到的阶段性小目标,这些小目标都有一个定义明确的阶段性评估标准。迭代就是为了完成一定的阶段性目标而所从事的一些列开发活动。在每个迭代开始前都要根据项目当前的状态和所要达到的阶段性目标制定迭代计划,整个迭代过程包含了分析、设计、编码和测试等开发活动,迭代完成后需要对完成的结果进行评估,并以此为依据来制定下一次迭代的目标,如下图所示。
 图2. 2 RUP递增迭代模型
图2. 2 RUP递增迭代模型
迭代RUP的集成模式步骤分为三步[6]:
(1)开发系统中一个小的功能模块,它可以说最小的功能块,但应该是系统中一个关键部分,彻底检查调试,然后将该模块作为一个核心,在它基础上设计系统的其他部分模块;
(2)设计、编码、检查和调试程序;
(3)将这些新程序代码集成到已经彻底测试的核心模块上。检查、调试核心模块和这些新程序的组合,在加入新程序之前,一定要确保组合工作正确,如果其余工作已被完成,重复过程从第二部开始。
整个集成过程是一个递增的过程,通常把这种集成方法称为“递增迭代”集成。
递增迭代集成能容易的确定错误位置——错误一定在新程序功能模块上。而且由于每次只集成少量代码程序,因此出现的问题数量也大大减少,降低由于多个问题相互作用产生新问题或者问题间相互掩盖的风险。大大提高的开发效率。
由于迭代递增过程中没有量化迭代间隔和每次增加人物的工作量,从而在实践中容易出现“迭而不增”和“增而不迭”两种错误。“迭而不增”变成简单的重复,并没有增加实际的功能;“增而不迭”变回了简单的线性模型
微软过程模型(MSF)[7]和“每日构建”集成模式是上述问题的解决方法之一。微软过程模型是由微软公司根据自身实践经验为企业设计的一套有关软件开发的准则。MSF过程模型是一种基于阶段的,由里程碑驱动的,递进的软件开发模型。
MSF过程模型建议项目组首先创建、测试和提供包含核心功能的产品模块,然后再向其中添加功能,提出后续版本。一般被称为递进的版本发布策略。每个版本代表一个开发阶段,这种做法更有利于产品的质量,也更便于在开发过程中对项目进行调整。MSF要求项目组在开发过程中迅速完成每一次递增过程,并在每一次开发周期中都能切实的增加产品的特性,提高产品质量。
MSF其对应的集成模式为“每日构建”(Daily Build)。每日构建包括以下步骤:
(1)定期检查源代码库;
(2)如果源代码库中发生改变将触发构建和后续测试;
(3)给源代码库的当前构建作一个标签,以便将来可以在当前够的基础上进行重新构建;
(4)给相应开发人员发送构建情况反馈。
MSF把集成变成了简单的工作,并把迭代间隔量化为每天,迭代的增量为每天的工作量,解决了迭代递增集成中容易出现的问题。
2.2.2 持续集成过程
技术的发展开始呈现出高速化的姿态,在此驱动下,软件开发也必须实现快速化的开发以适应技术的发展。此时敏捷开发便出现了,简单的说,敏捷开发是一种以人为核心、迭代、循序渐进的开发方法。它以适应性的过程来代替传统的预测性的过程,在很大程度上满足了现代商业软件业务复杂、需求多变、时间要求紧迫等特点。
相比瀑布式开发漫长严格的开发周期,敏捷开发要求在几周或者几个月的时间内完成相对较小的功能,强调的是能将尽早将尽量小的可用的功能交付使用,并在整个项目周期中持续改善和增强。而相比同样强调较短开发周期的迭代式开发,敏捷开发的周期更短,并更注重队伍中的高度协作。
而极限编程作为敏捷开发的方法之一,其中有一项最佳实践,即持续集成。极限编程认为:项目每天可以构建多次,而不只一次,每日构建是最低要求。一个完全自动化的过程应该让项目每天完成多次构建,这是可行的。在工作几个小时的开发后,就要对刚才工作的代码进行集成和测试,并快速获得反馈。持续集成虽然是出自极限编程的实践,但随着持续集成的发展,它已经开始作为一种优秀的软件开发实践应用于各种开发方法中。
持续集成[8]与“每日构建”相比有几点不同:首先,持续集成比每日构建的集成频率更高,具体依据项目而定;再者持续集成在集成失败后向开发人员提供快速的反馈,让开发人员可以迅速修复错误,而不仅仅是在成功构建后提供一个稳定的版本;最后持续集成鼓励开发人员频繁的提交代码修改并得到尽快的反馈,每次修改的代码量减少后,出现问题的修复也变得容易和迅速。
2.2.3 持续集成的原则
业界普遍认同的持续集成的原则[9]包括:
(1)需要版本控制软件保障团队成员提交的代码不会导致集成失败。常用的版本控制软件有 ClearCase、CVS、Subversion、Git 等;
(2)开发人员必须及时向版本控制库中提交代码,也必须经常性地从版本控制库中更新代码到本地;
(3)需要有专门的集成服务器来执行集成构建。根据项目的具体实际,集成构建可以被软件的修改来直接触发,也可以定时启动,如每半个小时构建一次;
(4)必须保证构建的成功。如果构建失败,修复构建过程中的错误是优先级最高的工作。一旦修复,需要手动启动一次构建。
2.2.4 持续集成的价值
(1)一天中进行多次的集成,并做了相应的测试,这样有利于检查缺陷,了解软件的健康状况。
(2)减少重复的过程可以节省时间、费用和工作量。说起来简单,做起来难。这些浪费时间的重复劳动可能在我们的项目活动的任何一个环节发生,包括代码编译、数据库集成、测试、审查、部署及反馈。通过自动化的持续集成可以将这些重复的动作都变成自动化的,无需太多人工干预,让人们的时间更多的投入到动脑筋的、更高价值的事情上。
(3)持续集成可以在任何时间发布可以部署的软件。从外界来看,这是持续集成最明显的好处,我们可以对改进软件品质和减少风险说起来滔滔不绝,但对于客户来说,可以部署的软件产品是最实际的资产。利用持续集成,您可以经常对源代码进行一些小改动,并将这些改动和其他的代码进行集成。如果出现问题,项目成员马上就会被通知到,问题会第一时间被修复。不采用持续集成的情况下,这些问题有可能到交付前的集成测试的时候才发现,有可能会导致延迟发布产品,而在急于修复这些缺陷的时候又有可能引入新的缺陷,最终可能导致项目失败。
(4)持续集成让我们能够注意到趋势并进行有效的决策。如果没有真实或最新的数据提供支持,项目就会遇到麻烦,每个人都会提出他最好的猜测。通常,项目成员通过手工收集这些信息,增加了负担,也很耗时。持续集成系统为项目构建状态和品质指标提供了及时的信息,有些持续集成系统可以报告功能完成度和缺陷率。再者由于经常集成,我们可以看到一些趋势,如构建成功或失败、总体品质以及其它的项目信息。
(5)持续集成可以建立开发团队对开发产品的信心,因为他们清楚的知道每一次构建的结果,他们知道他们对软件的改动造成了哪些影响,结果怎么样。而长期稳定的成功构建将极大的鼓舞团队的士气。
2.2.5 持续集成的应用
(1)团队开发。工程化软件开发中的开发团队规模往往上百人,且工程中又有许多分支,这时就需要统一的工程管理措施来确保准确有效的开发工作。
(2)作为许多流行的软件开发理论的基础组成部分,例如敏捷开发,Staging Delivery,RUP 中的迭代开发等。拿敏捷开发来说,敏捷开发是一种以人为核心、迭代、循序渐进的开发方法。在敏捷开发中,软件项目的构建被切分成多个子项目,各个子项目的成果都经过测试,具备集成和可运行的特征。换言之,就是把一个大项目分为多个相互联系,但也可独立运行的小项目,并分别完成,在此过程中软件一直处于可使用状态。
(3)运营与开发。像淘宝之类网站在进行开发、测试(压力测试、兼容性测试等)、上线(同时要装到N台服务器上)、数据维护等均需要运用到持续集成技术。
2.2.6 持续集成的常见工具
持续集成概念发展的十多年间,早已经出现了许多用以支持这一概念的工具,这些工具的组合使用为软件开发提供了强大的支持。
一般来说,持续集成工具可以分为两大类:自动化构建工具和构建计划安排工具。
(1)自动化构建工具
自动化构建工具有这样一些基本功能:代码编译、组件打包、程序执行和文件操作。编译源代码是构建的主要工作之一,为了提高效率,编译应该根据相应的源代码是否发生改变而有条件地执行。组件打包是将编译的结果和其他需要包含的文件组织在一起,形成可以部署的组件。构建工具应该知道何时需要重新打包。程序执行是指构建工具能够在它支持的平台上,调用所有提供命令行接口的程序。构建工具应该支持创建、拷贝、删除文件和目录等操作。
某些自动化构建工具还有一些扩展功能:执行开发者测试、版本控制工具集成、文档集成、部署功能、代码品质分析、支持扩展、多平台构建、加速构建。虽然构建工具可以通过命令行执行的方式来集成构建工具和测试工具,但如果它提供更直接的集成方式,开发者就更省力。同样,如果构建工具能够直接与版本控制工具集成,开发者也会觉得更方便。文档集成是指构建工具能够自动从源代码中抽取并生成API文档。构建工具还可以将打包好的组件自动部署到目标测试环境中去。构建工具一般通过一些第三方插件,支持对代码品质进行分析。而提供插件接口,是构建工具实现可扩展性的通用方式。如果您开发的软件需要在多个平台上构建并测试,那么构建工具对多平台的支持就会带来极大的方便。对于较大的代码集,一次构建可能需要好几个小时,这为持续集成带来了一些挑战。有的构建工具支持加速构建,即在多个构建服务器的多个处理器上进行分布式构建。
常见的自动化构建工具包括Ant、NAnt、MSBuild、make、Maven、Rake、Doxygen等。
(2)构建计划安排工具
构建计划安排工具,通常也叫做持续集成服务器,其基本功能为:构建执行、版本控制集成、构建工具集成、提供反馈、为构建打上标签。构建计划安排工具的核心功能就是在特定时间执行自动化的构建,这可以通过轮询版本控制库、计划驱动或事件通知等方式来实现。大部分构建计划安排工具都支持大多数流行的版本控制系统,也支持大多数流行的构建工具。构建计划安排工具至少支持通过电子邮件提供反馈信息,有一些工具可以通过即时消息、手机短信或其他设备来提供反馈。大多数构建计划安排工具会提供某种类型的升序计数,作为构建版本的标签。
某些构建计划安排工具还有一些扩展功能:支持项目间依赖关系、提供用户界面、制品发布、安全。如果项目间存在依赖关系,您可能希望在被依赖的项目重新构建时,重新构建依赖于它的项目。设计良好的用户界面会在工作时为您节约时间。制品发布是指除了得到可部署的组件之外,一些成熟的某些构建计划安排工具可以将文档、测试结果、品质分析结构和其他测量指标数据格式化,便于查看。有一些工具提供了身份认证和授权等安全方面的功能,允许您指定谁能查看结果和修改配置。
常见的构建计划安排工具包括AnthillPro、Continuum、CruiseControl、CruiseControl.NET、Draco.NET、Luntbuild、Jenkins等。
(3)其他与持续集成相关的工具
现代软件开发中必然有一个源码管理系统来管理项目代码,不然代码的存储将会杂乱无章。而一个完整的持续集成系统中必然也少不了这一工具。源码管理系统也可称为版本管理工具,主要分为两种:集中式和分布式。集中式版本管理代表为Subversion(SVN),分布式的代表为:Git。Git还可以配合代码审核工具Gerrit实现强制代码审核功能。Gerrit通过网页的形式方便负责人对开发者提交的代码进行审核、评论等,省去了审核人需要自行下载代码在本地查看提交变化的流程。进一步方便了版本管理。Gerrit可结合持续集成服务器,为每次代码变更触发一次自动编译,若自动编译无法通过,则直接review不通过,省去审核人时间。
2.2.7 持续集成常见方案
一个完整的持续集成系统由以下几部分组成:
(1)一个自动构建过程,包括自动编译、分发、部署和测试等。可使用ANT或者Maven等工具;
(2)一个代码存储库,即需要版本控制软件来保障代码的可维护性,同时作为构建过程的素材库。例如Subversion、Git、CVS;
(3)一个持续集成服务器。Cruise Control、Jenkins等。
按照该组成,你可以选用自己喜欢的工具来设计你自己的持续集成系统方案。比如PMS平台(JIRA+CruiseControl+Subversion)[10]、Git+Jenkins+Gerrit[11]等。
3 基于Jenkins的软件自动构建系统方案设计
3.1 基于Jenkins的自动构建系统方案
自动构建系统由持续集成服务器、版本控制工具、构建工具构成。版本控制工具保证项目源码处于有序的管理中,方便开发人员随时获取和提交变更。构建工具实现项目的自动构建、自动测试、自动部署等功能。持续集成服务器将三者结合起来共同完成从监测到版本改变、到自动编译改变的代码再到自动运行所有的单元测试用例,并输出结果,完成自动化测试和监测代码正确性的功能。持续集成发展至今,相关的工具也多种多样。而且采用不同的工具来搭建自动构建系统,将带来不尽相同的效果,但目的都是一样的——最大程度的简化软件开发的过程。下面说明一下本设计采用的方案。
(1)持续集成服务器
持续集成服务器有十来种,但是常用的是CruiseControl和Jenkins。本设计中选用Jenkins,具体原因如下:
Jenkins容易安装和配置,而且提供了直观灵活的基于web的用户界面配置管理方案;
Jenkins具有强大的插件框架,目前已经拥有超过600中插件可供使用;
Jenkins支持多种构建语言,包括Python等;
Jenkins集成了RSS/Email通知机制;
Jenkins支持分布式构建。
Jenkins的特点还有许多,相较之下CruiseControl则较为厚重,而且配置需要通过config.xml来完成,界面比Jenkins要逊色许多,且扩展性没有Jenkins来的强大(不得不说Jenkins作为一个开源项目,其插件的开发做得非常出色)。因此,虽然Jenkins作为一个后起之秀能渐渐取代当初流行的CruiseControl自有其道理在。
(2)版本控制管理工具
当下热门的版本控制管理工具基本分为两种:分布式和集中式的。其中分布式代表为Git,集中式的代表为Subversion(SVN)。下面我们来对比一下两者特点。
SVN可谓是集中式版本控制集大成者。集中式版本控制中,每个人都可以一定程度上看到项目中其他人正在做些什么。而管理员也可以轻松掌握开发者的权限,但是如果中央服务器宕机了,那么所有的开发者都无法进行提交更新、还原、对比也无法协同工作,这样对项目开发带来了极大的风险。最可怕的是出现数据丢失的情况。
Git的分布式版本控制相比于集中式版本控制最大的不同是不需要集中式的版本库,每个人都工作在通过克隆建立的本地版本库中。也就是每个人都拥有一个完整的版本库,开发者可以在本地库上做任何操作。加上多样的协同工作模型(版本库间的推送,拉回,补丁等)让分布式版本控制极大的促进了多人参加的协同工作。由于不用联网,使得工作处理速度极快。尽管Git无法像SVN一样对项目进行精细的授权,但是通过加入代码审核工具Gerrit也能实现详细的授权管理。
综上所述,本设计采用Git作为版本控制工具。
(3)构建工具
在构建工具的选择依基本是选择Ant或者使用更为强大的Maven,或者使用自己编写的构建脚本。下面就Ant来阐述一下其优点:首先,因为Ant使用JAVA实现,所以是跨平台的;其次,与make相比,Ant语法清晰,使用简单;再者,Ant配合插件使用能够实现许多功能。
(4)代码检测
对于JAVA项目可以使用FindBugs进行静态代码检测。FindBugs是检查JAVA字节码,即*.class文件,可以帮助开发人员提高代码质量以及排除隐含的缺陷。
(5)测试
对于测试工具的使用,依据项目而定。如果是C/C++项目则使用CppUnit,若是JAVA项目则使用JUnit。两者都是XUnit的成员,当然除了CppUnit和JUnit之外,XUnit还有PythonUnit等,均是基于测试驱动开发的测试框架,能让我们得以快速的进行单元测试。在进行单元测试后,还可以通过Emma工具来进行单元测试的代码覆盖率的统计,方便之后对单元测试的完善。
本设计选用一台机器作为持续集成服务器主机,通过持续集成服务器Jenkins来进行设置。选用另一台机器作为持续集成服务器的子机,用来分担主机的任务压力。并选用一台机器专门作为代码仓库,由代码审核工具Gerrit进行管理。持续集成服务器监视代码仓库,一旦代码仓库中有代码修改提交,则自动从代码仓库拉下代码,执行自动构建、代码检测、测试并把结果通过web和E-mail的形式及时反馈给开发人员。
一旦自动构建系统能稳定的运行,将给开发团队带来比较稳定且快速的开发效率,使得原本艰难的集成工作变成一件能在十来分钟内(只考虑编译测试)自动完成的轻松事,有效降低了由于bug过晚发现导致修改代价过高的风险,进而提高软件质量,鼓舞团队士气。
3.2 基于Jenkins的自动构建系统方案的工作过程
下面我们基于以上的模型来描述一下该自动构建系统的工作过程。
首先,开发人员使用Git从代码仓库中拉下项目源码,并在本地进行工作。在几个小时工作后,准备向代码库提交修改代码。提交过程分为两步:首先,开发人员在本地调试成功打算提交时,需要将最新的代码库同步到本机中,并检查与最新的更改是否发生冲突,如果发生冲突则需要进行修改或者与其他修改者进行协商解决冲突。然后在本地能够成功构建后再提交修改代码。由于我们设置了代码审核服务器来管理Git仓库,因此提交的代码先进入代码审核环节,在没有持续集成服务器的情况下,代码审核需要审核人手动进行修改代码的review(拉下代码、构建、审核等),review后若代码满足要求就可以进行submit,代码才正式merge进代码仓库中。在引入持续集成服务器后我们可以设置Gerrit的触发事件,在每次有新的代码提交时,自动触发构建任务,并将结果反馈给Gerrit代码审核服务器,Gerrit将根据反馈结果决定对本次代码修改采取的动作,成功则将本次变更merge到代码库中,否则打回本次修改,开发人员也会受到构建结果的通知。下图简要描述了该持续集成过程。

图3. 2 持续集成流程
3.3 选用Jenkins插件
在前面两节中我们详细描述了本设计中持续集成系统方案的核心工具的选用和其工作流程,但事实上,每个使用持续集成技术的公司,他们的持续集成系统都有他们自己的特色和要求。这时候Jenkins强大丰富的插件框架就能体现出它得天独厚的扩展能力:超过600种插件和可自主开发的开源环境让你深深体会到:只有想不到,没有做不到。下面我们来介绍一下本设计方案中采用了哪些Jenkins的插件和第三方软件的支持。
(1)自动文档生成之Doxygen
Doxygen是一种开源跨平台的,以类似JavaDoc风格描述的文档系统,完全支持C、C++、Java、Objective-C和IDL语言,部分支持PHP、C#。注释的语法与Qt-Doc、KDoc和JavaDoc兼容。Doxgen可以从一套归档源文件开始,生成HTML格式的在线类浏览器,或离线的LATEX、RTF参考手册。
文档的重要性对于程序员来说是不言而喻的,一个好的文档可以让你的软件更容易让人理解和使用。但是编写文档从来都是一件麻烦的事情。Doxygen作为一款优秀的文档自动生成工具,可以将程序中的特定批注转换成说明文件,并且可以自动生成相关的类图等,但是需要程序员在程序的注释中多下点功夫。
而通过将文档自动生成放入到我们的自动构建系统中即可以轻松的实现定时或者触发性的文档自动生成和发布。
再使用Jenkins的HTML Publisher plugin可以轻松的把生成的文档显示在项目中。
(2)Gerrit Trigger、Git plugin、Git Client plugin
为了使Jenkins能够获取代码审核工具Gerrit的变更信息,需要安装Gerrit Trigger plugin,安装后通过简要配置连接的用户信息就能够实时的获取Gerrit中的代码情况,并能监视变动进而触发相应的自动构建事件,最终将构建结果反馈给Gerrit,并设置review和verify的值。
由于我们使用的版本控制工具为Git,为此我们需要使用相应的Git插件来添加相应的Git代码库操作功能。
(3)SSH Slave plugin和Credentials plugin
有时候我们有许多项目同时需要进行持续集成的时候,我们就必须考虑引入额外的子机来分担持续集成主服务器的工作压力。这时候需要用到Jenkins的Master/Slave的服务器架构。Master和Slave机器之间的连接方式有许多种:SSH、Java web start、WMI+DCOM、自己的连接脚本。这里偏向于使用SSH的连接方式,较为方便。但是当对连接后需要做点额外的环境配置等工作的时候,就需要编写自己的连接脚本了。再使用Jenkins的SSH Slave plugin就能添加通过SSH连接的子机节点了。
(4)FindBugs plugin和 Jenkins Emma plugin
使用FindBugs和Emma分别实现对Java代码的静态检测盒单元测试的代码覆盖率统计,再通过对应插件将两者产生的结果通过图形化的方式直观的发布在持续集成系统中,方便开发人员的查看。
(5)Jenkins TextFinder plugin
有时候我们需要通过自动构建产生的构建信息或者指定文件的内容来决定本次构建是否成功,这时候就需要用到该插件。所要查找的字符串通过正则表达式来定义。还能指定需要查找的文件或者Jenkins控制台输出内容。
(6)Jenkins Mailer plugin
该插件实现构建结果的通知功能。当构建结果不稳定或者失败的时候,可以给指定的接收人邮箱发送邮件。接收人的邮箱地址支持变量输入,比如$GERRIT_CHANGE_OWNER_EMAIL,可以实现对向Gerrit提交代码修改的人发送邮件。
(7)ThinBackup 和 Backup plugin
备份是维护一个系统非常重要的一环,Jenkins拥有强大的备份插件,可以实现定时定量的内容备份。这里有两种插件可供使用:第一种为ThinBackup,该插件能将Jenkins中的任务配置文件进行高效的备份,并支持定时备份;第二种为Backup plugin,该插件直接将Jenkins的整个workspace文件夹进行拷贝,因此需要的时间也比较长,但是信息完整。一般情况使用第一种进行短周期的备份即可(支持自动清理过旧的备份),在项目稳定后再使用第二种进行完整的备份。
(8)Role-based Authorization Strategy
该插件提供了一种基于角色的安全认证系统。管理员可以通过该插件来创建对Jenkins拥有不同权限的角色,并对Jenkins用户进行角色分配。从而提高Jenkins的安全性,防止外来人员恶意修改系统。
(9)Android Emulator plugin
该插件极大便利了Android项目的开发,它支持自动启动Android Emulator从而实现对Android项目的仿真测试。通过插件参数配置可以实现自定义的Emulator,通过创建multi-configuration project还能实现对不同参数Emulator的仿真测试对比。
(10)Dashboard View 和Extra Columns plugin
当处于持续集成下的项目多了之后就需要对Jenkins的Web显示界面进行管理,将项目按照一定的规则进行组的划分并归到相应的视图下,方便查看,使用Dashboard View即可完成此功能。若需要在每个项目栏上添加快捷的按钮,如最近的构建信息等,使用Extra Columns plugin可以实现自定义的添加修改。
Jenkins的插件十分丰富,如何有效的使用这些插件来进一步简化持续集成工作是非常重要而有意义的,要认识到有时候发现或者设计一个便利的插件可能会大大提高集成的效率和质量。
4 基于Jenkins的软件自动构建系统方案的实践
4.1 项目介绍
Elastos操作系统是目前科泰公司正在开发的系统,本设计的自动构建系统将着力于为Elastos系统的研发提供便利的持续集成功能:包括自动编译、自动测试、文档自动生成、开发人员代码贡献统计等。
4.2 实践环境的搭建
4.2.1 操作系统基本环境搭建
(1)JDK 6
到Oracle官网下载相应版本的JDK 6。我将下载文件解压到/usr/jdk6,执行以下命令:
编辑.bashrc文件:
sudo vim ~/.bashrc
在.bashrc中加入以下内容:
export JAVA_HOME=/usr/jdk6
export JRE_HOME=/usr/jdk6/jre
export CLASSPATH=/usr/jdk6/lib
export PATH=$PATH:$JAVA_HOME/bin
这样JDK就算安装成功了。这时候需要手动执行以下.bashrc脚本:
source ~/.bashrc
(2)Tomcat
运行Jenkins可以使用其自带的容器来启动,也可以部署到Tomcat下启动。个人推荐后者。下面简要描述一下Tomcat的安装。
首先到Apache Tomcat官网下载对应版本的安装包,我这里选择Core分类下的tar.gz包,将压缩包解压并重命名为tomcat放到~目录下,即/home/kurenai/tomcat 。
通过/home/kurenai/tomcat/bin/startup.sh就能开启tomcat服务。相应的shutdown.sh可关闭tomcat服务。
为了管理,我们还需要添加tomcat管理用户:
vim /home/kurenai/tomcat/conf/tomcat-users.xml
添加内容:
<user username=”your-username” password=”your-password” roles=”admin-gui,manager-gui”/>
这样就可以通过localhost:8080来访问tomcat的管理界面了。
(3)Elastos的编译环境配置
为了在Ubuntu 64位系统中可以编译Elastos、Android2.3.5以及它的kernel2.6.29,需要安装:
sudo apt-get install git-core gnupg flex bison gperf build-essential \
zip curl zlib1g-dev libc6-dev lib32ncurses5-dev ia32-libs \
x11proto-core-dev libx11-dev lib32readline5-dev lib32z-dev \
libgl1-mesa-dev g++-multilib mingw32 tofrodos python-markdown \
libxml2-utils xsltproc
(4)php5和mysql
php5和mysql的安装可以使用apt-get安装,也可通过官网下载手动安装。
sudo apt-get install php5
sudo apt-get install mysql-client mysql-server
sudo apt-get install php5-mysql
(5)Doxygen文档自动生成工具的配置使用
首先到Doxygen官网http://www.doxygen.nl 下载安装包。先安装Doxygen所需要的组件和库。使用命令:
sudo apt-get install graphviz perl bison flex qt4-dev-tools
安装完毕后就能进行Doxygen的安装:
tar –zxvf doxygen-…src.tar
./configure –prefix /path/to/doxygen –with-doxywizard
make && make install
若没有使用prefix指定安装路径,则系统默认会把doxygen和doxywizard放在/usr/local/bin下,则无需添加环境变量,因为本路径已经在path下了。doxywizard 是一个用来生成配置的图形界面工具,与windows下的doxywizard类似。
安装完毕后使用命令doxywizard便可通过图形化的配置界面来生成Doxygen的doxyfile。
4.2.2 版本控制管理工具的配置
我们选用的版本控制工具为Git,在Ubuntu下可以很轻松的安装和使用它:
sudo apt-get install git git-core
等待安装完毕就可以了。唯一需要进行的配置是git使用时候的用户名和邮箱,这是很重要的,涉及到后面代码审核Gerrit的使用。
使用以下命令来配置Git:
git config –global user.name “your username”
git config –global user.email “your e-mail”
4.2.3 代码审核工具的配置
从Gerrit官网下载Gerrit安装包,为war格式。使用以下指令初始化Gerrit:
java -jar gerrit.war -init -d /home/kurenai/gerrit_site
后面路径为安装路径。
然后会进入交互式的配置环节,大部分的配置可以保留默认值,需要更改的配置下面进行说明:
Git代码库位置,要指向正确的Git库位置,默认为安装目录下的git,也可以指定其他目录。Gerrit在启动的时候通过扫描这个目录来添加项目。
数据库,选用mysql,数据库的用户名和密码要设置正确否则会连接不上。
Gerrit的认证方式有OPENID,HTTP,LDAP等。
若是仅为测试而已可以使用development_become_any_account模式,该模式下第一个用户为超级用户。
为了使Gerrit能够发送邮件通知,需要配置邮件服务器。在[sendemail]选项下设置enable=true,smtpServer、smtpUser以及smtpPass就能使用邮件功能。
为了使用Gerrit需要建立对应的Gerrit账号和SSH密钥对(注意这里账号的名称和邮件名要和Git中的设置一样)。通过Ubuntu的SSH工具即可。具体就不赘述了。
以上只是简要介绍了Gerrit的架设,具体情况请参考相关文档。由于本设计中的Elastos项目存储在Elastos.org网站上的Gerrit服务器,因此我们直接选用公司的Gerrit服务器作为代码仓库,省去自己架设的步骤而且也更稳定。以下是代码审核服务器Gerrit的界面
 图4. 1基于代码审核服务器Gerrit的代码仓库
图4. 1基于代码审核服务器Gerrit的代码仓库
4.2.4 持续集成服务器的配置
Jenkins作为一款轻量级的持续集成服务器,其部署也相当简单。到Jenkins官网下载对应的war包,放置到tomcat安装目录的webapps目录下,然后重启tomcat即可完成Jenkins的部署。可以通过http://localhost/jenkins来访问。
由于Jenkins的默认根文件路径是安装用户home下的.jenkins目录,因为是隐藏文件不方便我们查看。可以通过以下方法修改默认路径:
进入tomcat下的conf目录,创建一个jenkins.xml文件,将如下几行加入,
1 | <Context docBase="path/to/tomcat/webapps/jenkins.war"> |
2 | <Environment name="JENKINS_HOME" type="java.lang.String" value="/new/path/to/jenkins" override="true"/> |
3 | <Context> |
其中jenkins.war文件就是我们放到webapps目录下的jenkins文件,要给出这个文件存放的绝对路径,value后面就是变更后jenkins的根目录的位置。
反复启动tomcat后,修改tomcat/Webapps/jenkins/WEB-INF/web.xml
1 | <env-entry> |
2 | <env-entry-name>JENKINS_HOME</env-entry-name> |
3 | <env-entry-type>java.lang.String</env-entry-type> |
4 | <env-entry-value>/new/path/to/jenkins</env-entry-value> |
5 | </env-entry> |
重启tomcat,打开jenkins,jenkins根目录修改完毕。
在部署完Jenkins后,我们还需要对其进行一定的系统配置:
(1)进入Jenkins系统管理的系统设置部分:
需要对Git,Ant,E-mail,JDK进行设置。
Git 设置中的用户名和邮箱与Git config中的设置一致;
Ant,JDK均可以使用自动在线安装,方便slave机器的启用。
E-mail设置较为简单就不赘述。
(2)Jenkins安全配置
点选“启用安全”启动Jenkins安全设置。这里使用Jenkins专有用户数据库,授权策略使用Role-Based Strategy,这里需要先安装插件Role-based Authorization Strategy。
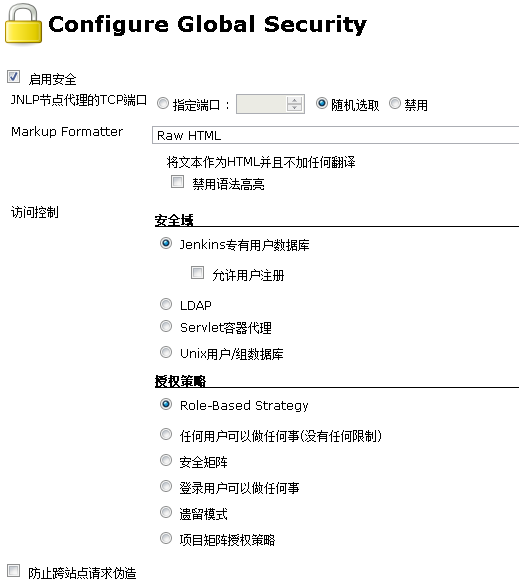
图4. 6启用安全
设定使用Role-Based Strategy后需要设置相应的Role来进行分配。这里我们设置一个拥有一切权利的管理员角色admin和只具有查看权限的readonly角色。admin角色勾选所有权限,readonly只勾选”read”选项。
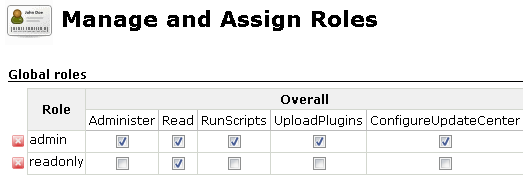
图4. 7角色设置(选项太多,这里只列出部分)
然后进行角色分配:

图4. 8分配角色
elautobuilder用户为管理员用户(用户注册通过管理用户来注册),其他匿名用户为只读权限。
(3)Jenkins与Gerrit的连接配置
先安装Gerrit trigger plugin。进行相应配置:
见: Jenkins学习笔记(五)之Gerrit trigger plugin
4.2.5 自动构建工具
在引入自动化构建之前,开发人员需要每天自行下载最新代码,进行编译、测试、部署等重复的任务,不仅繁琐而且容易出错,因为人毕竟不是机器。因此要实现持续集成的重点是实现自动化,包括自动检测源代码库、自动化编译、自动化测试、自动化部署。而要实现自动化,对于JAVA项目来说,ANT可以说是现在的标准工具。它的默认配置文件时build.xml。
使用apt-get安装ant,安装方法:
sudo apt-get ant
使用的时候只需要将ant对应的build.xml构建脚本放在所要构建的项目根目录下,通过执行指令:ant [target name] 即可,例如:ant clean debug ,将运行clean,debug目标。
4.2.6 实现Jenkins的master/slave架构
Jenkins通过插件SSH Slave plugin和Credentials plugin可以实现master/slave架构的集成服务机群。
见:Jenkins学习笔记(四) master/slave的初步认识
4.3 基于Jenkins的软件自动构建系统方案的实践过程
4.3.1 Android项目的自动构建
见:Jenkins学习笔记(十一)如何构建和测试Android app
4.3.2 Elastos项目自动编译
(1)创建任务
Elastos项目的自动编译除了需要Elastos源代码外还需要ElastosRDKforUbuntu源代码,并需要将Elastos项目放置在ElastosRDKforUbuntu的Sources目录下。可以在Jenkins项目配置中使用自定义工作空间来实现。
这里还需要设置Gerrit trigger,用来监视Gerrit的源码仓库变化。在项目配置的构建触发器中选中Gerrit trigger,并添加对Elastos项目和ElastosRDKforUbuntu项目的监视。
(2)构建脚本
编译Elastos项目的脚本使用main.sh,详见附录。
(3)构建结果判定
Jenkins无法通过main.sh的编译结果来判定编译是否正确,这里我们需要自行使用Text Finder来查找编译过程输出中是否有”make: ***”字样来判定编译正确与否。若出现该字样,则将该构建定为失败构建。反之为成功构建。
 由于与Gerrit进行了连接,当构建成功或者失败后都能讲其构建状态反馈到Gerrit中。
由于与Gerrit进行了连接,当构建成功或者失败后都能讲其构建状态反馈到Gerrit中。
4.3.3 Doxygen自动文档生成
见:jenkins 学习笔记(二)之自动文档生成Doxygen
附录另有用来实现Doxygen filter功能的filter程序。实现以下功能:
1)module { } 转化成 module com.elastos {}
2)interface Name; 转化成 Name interface;
3)在所有’}’后面添加’,即 ‘}’转换成’};’
5 结论
本文从传统的软件集成方式的发展出发,深入研究了在软件高速开发的现代软件开发环境下的持续集成技术理论。并在该理论基础上设计一套基于Jenkins的持续集成系统,并应用于Elastos项目的自动文档生成和自动编译工作。目标是提高软件开发效率和质量。而在实践中,可以发现,引入持续集成技术后,对项目的开发起到了一定的帮助。
由于本人对于持续集成理论的接触时间较短,很多地方的理解不是很透彻。因此设计的系系也存在很多问题。下面是个人对该系统以后完善的一点建议:
在项目的开发中,可以使用Redmine实现Web化的项目管理,其中包括了项目Bug的跟踪,新闻、wiki等。而如何将Jenkins与Redmine相结合,实现持续集成中Bug的持续跟踪将会相当有意义。
持续集成中的自动测试往往是最费时间的,但是持续集成追求的是快速的集成构建,为了满足这一点,可以把构建分阶段:第一阶段是编译和一些核心的无需进行数据库交互的测试;第二阶段是需要和数据库进行交互的大量单元测试。若阶段一构建成功则能视为成功构建,然后再进行阶段二测试,此时项目开发也能同时进行。提高集成效率。
当项目较多较大的时候,就有必要设置一个持续集成机器群来进行高效的持续集成。而普通的master/slave架构无法将项目构建过程拆分,从而并发执行。有必要研究如何实现将项目构建中能够并发执行的部分分发给多台子机进行并发构建,从而降低构建时间。
参考文献
[1] Steve McConnell.Daily build and Smoke Test[J].IEEE Software, 1996, 13(4):144-143
[2] LIU Qiao-Ling,FAN Bing-Bing,HUANG Xing-Ping.Research and Application of Continuous Integration Based on Hudson[J].Computer Systems& Applications,2010,19(12):151-154
[3] 刘华婷.基于Jenkins 快速搭建持续集成环境[DB/OL].(2011-11-24).
http://www.ibm.com/developerworks/cn/java/j-lo-jenkins/index.html
[4] 肖永锋.基于J2EE的持续集成研究与应用[D].中山大学,2005
[5] Winston Royce. Managing the development of large software system[C].Proceedings,IEEE WESCON.1970
[6] 金敏,周翔编著.高级软件开发过程—Rational统一过程、敏捷过程与微软过程. 北京:清华大学出版社,2005
[7] 麦中凡,陶伟.微软软件开发解决方案框架 MSF.北京航空航天大学出版社,2003
[8] Continuous Integration[DB/OL].(2006-5-1)
http://www.martinfowler.com/articles/continuousIntegration.html
[9] 持续集成理论和实践的新进展[DB/OL].(2011-7-25)
http://www.infoq.com/cn/articles/ci-theory-practice
[10] 徐仕成.持续集成在现代软件开发中的应用与研究[D]. 中南大学,2007
[11] Alex Blewitt.GitGerrit and Jenkins/Hudson CI server[DB/OL].(2011-9-6).
http://www.infoq.com/cn/articles/Gerrit-jenkins-hudson
附录
(1)main.sh 源代码:
01 | #!/bin/bash |
02 |
03 | if [ -z $1 ];then |
04 | echo "Usage: main.sh [ option: checkout | update ]" |
05 | echo "Option :" |
06 | echo "checkout fetch new codes and make it" |
07 | echo "update update a existent codes and make it" |
08 | exit |
09 | else |
10 | export OPTION=$1 |
11 | fi |
12 | cd "$(dirname "$0")" |
13 | export ELASTOS_DIR=$HOME/ElastosRDKforUbuntu |
14 | export SCRIPT_DIR=$(pwd) |
15 | rm -f /tmp/dbg_compile_finish.txt |
16 | XDK_VERSION = dbg |
17 | $SCRIPT_DIR/compile.sh $XDK_VERSION $OPTION |
(2)compile.sh 源代码:
01 | #!/bin/bash |
02 |
03 | [[ -z $1 ]] && echo "*ERROR* Please set Argument 1 [ dbg | rls ] !" && exit |
04 | [[ -z $2 ]] && echo "*ERROR* Please set Argument 2 [ checkout | update | build ]" && exit |
05 |
06 | export ELASTOS_DIR=$HOME/ElastosRDKforUbuntu |
07 |
08 | chmod a+x $ELASTOS_DIR/Setup/ -R |
09 | echo "Start to Compile Elastos".$1" ..." |
10 | source $ELASTOS_DIR/Setup/SetEnv.sh arm_android && source chv.sh $1 |
11 |
12 | if [ $2 == "update" ];then |
13 | echo "clobber..." |
14 | emake.sh clobber |
15 | fi |
16 |
17 | cd Elastos && emake.sh |
18 |
19 | if [ $XDK_VERSION == "dbg" ]; then |
20 | echo "dbg_compile_finish" > /tmp/dbg_compile_finish.txt |
21 | fi |
(3)car_filter.py 源代码:
01 | #!/usr/bin/python |
02 | import getopt # get command-line options |
03 | import os.path # getting extension from file |
04 | import string # string manipulation |
05 | import sys # output and stuff |
06 | import re # for regular expressions |
07 |
08 | #stream to write output to |
09 | #outfile用来存储处理完成后的输出,供doxygen使用 |
10 | outfile = sys.stdout |
11 |
12 | #regular expression |
13 | #需要识别的正则表达式,分别对应上面所说的三种转化对象 |
14 | re_interface = re.compile(r"(\s*)(interface)([^;]*)(?=;)") |
15 | re_module = re.compile(r"(\s*)(module)(\s*)((?={)|(?=\s*$))") |
16 | re_semicolon = re.compile(r"(.*)(})(.*)") |
17 | #filters .car-files |
18 |
19 | #在'}'后面添加';'的函数 |
20 | def semicolonAdd(s): |
21 | global re_semicolon |
22 | match_semicolon = re_semicolon.match(s) |
23 | if match_semicolon is not None: |
24 | #found '}' |
25 | return re_semicolon.sub(r"\1\2;\3",s) |
26 | else: return s |
27 | #对CAR文件进行处理的函数 |
28 | def filterCAR(filename): |
29 | global outfile |
30 | global re_interface |
31 | global re_module |
32 | f = open(filename) |
33 | r = f.readlines() |
34 | f.close() |
35 | #outfile.write("\n//processed by filterCAR \n") |
36 | for s in r: |
37 | #outfile.write(s+"\n") |
38 | s = semicolonAdd(s) |
39 | match_intface = re_interface.match(s) |
40 | match_module = re_module.match(s) |
41 | if match_intface is not None: |
42 | #found interface |
43 | outfile.write(re_interface.sub(r"\1\3 \2",s)) |
44 | elif match_module is not None: |
45 | #found module |
46 | #outfile.write(match_module.group(0)+" com.elastos {\n") |
47 | outfile.write(re_module.sub(r"\1\2 com.elastos",s)) |
48 | else: |
49 | #if it's no match just output |
50 | outfile.write(s) |
51 | # dumps the given file |
52 | # 不做处理直接输出 |
53 | def dump(filename): |
54 | f = open(filename) |
55 | r = f.readlines() |
56 | f.close() |
57 | for s in r: |
58 | sys.stdout.write(s) |
59 |
60 | ## main filter-function ## |
61 | ## |
62 | ## this function decides whether the file is |
63 | ## (*) car file |
64 | ## |
65 | ## and calls the appropriate function |
66 | #主要filter函数,判定是否为.car文件,并调用适当函数进行相应处理 |
67 | def filter(filename, out=sys.stdout): |
68 | global outfile |
69 | outfile = out |
70 | try: |
71 | root, ext = os.path.splitext(filename) |
72 | if (ext.lower() ==".car"): |
73 | ## if it is a module call filterCAR |
74 | filterCAR(filename) |
75 | else: |
76 | ## if it is an unknown extension, just dump it |
77 | dump(filename) |
78 | sys.stderr.write("OK\n") |
79 | except IOError,e: |
80 | sys.stderr.write(e[1]+"\n") |
81 | ## main-entry ## |
82 | ################ |
83 |
84 | if len(sys.argv) != 2: |
85 | print "usage: ", sys.argv[0], " filename" |
86 | sys.exit(1) |
87 |
88 | # Filter the specified file and print the result to stdout |
89 | # doxygen会执行命令 <filter> <filter-file>,这里使用sys.argv[1]取出<filter-file>的值并调用filter函数处理 |
90 | filename = sys.argv[1] |
91 | filter(filename) |
92 | sys.exit(0) |
整个程序并不难理解,关键点是三个正则表达式的使用,并把修改后的字符串写到标准输出流中,Doxygen会自动从中读取,并进行文档生成。

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)