
Docker
Docker在线演示地址:http://www.docker.com/tryit/Docker文档官网:https://docs.docker.com/engine/understanding-docker/目录1.docker概述。2.安装3.基本命令4.使用实例1.docker概述Docker Overview 一种容器式的虚拟化技术,让你可以中容器中开发、测试,并通过容器的
Docker在线演示地址:http://www.docker.com/tryit/
Docker文档官网:https://docs.docker.com/engine/understanding-docker/
目录
1.docker概述。
2.安装
3.基本命令
4.使用实例
1.docker概述
Docker Overview
一种容器式的虚拟化技术,让你可以中容器中开发、测试,并通过容器的方式交互,提高生产上线的周期。
Docker does this by combining kernel containerization features with workflows and tooling that help you manage and deploy your applications.
优点:相比与虚拟化来说,省去了HyperVisor层,部署更加快,且让你可以部署更多的容器。
Docker Engine
Docker引擎是C/S模式的,包括:
服务器:长时间运行的程序,也叫Daemon进程。用来创建和管理Docker对象,包括镜像,容器,网络,数据卷等等。
Rest API:使得(容器中运行的)程序可以和Daemon进程通信交互,并指导容器程序运行。
client:A command line interface (CLI) client。The CLI makes use of the Docker REST API to control or interact with the Docker daemon through scripting or direct CLI commands. Many other Docker applications make use of the underlying API and CLI.
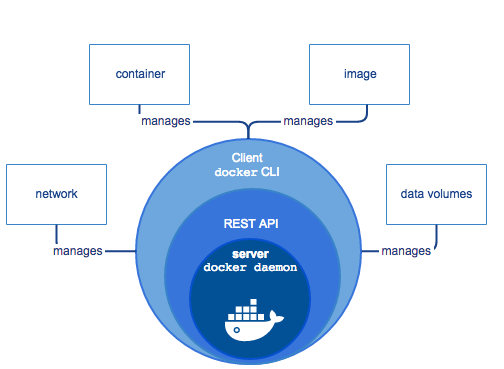
Docker 运行环境
Docker能够运行在开发人员本机机上、物理机上,虚拟机上或是数据中心,或是云上。让应用部署、扩展更加简单。
Docker 架构
The Docker client and daemon communicate via sockets or through a RESTful API.
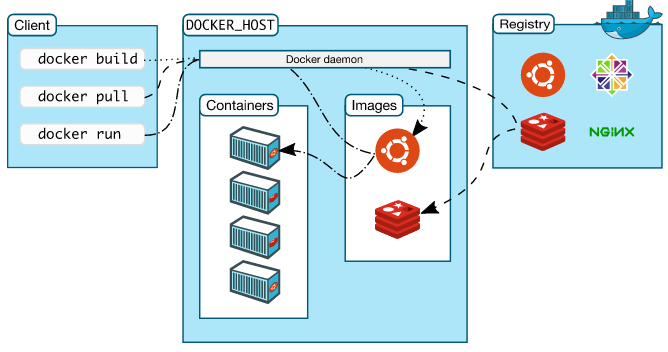
Docker内部基本元素
Docker images
(分层的,在做了修改时,只是更新某层镜像)
One of the reasons Docker is so lightweight is because of these layers. When you change a Docker image—for example, update an application to a new version— a new layer gets built. Thus, rather than replacing the whole image or entirely rebuilding, as you may do with a virtual machine, only that layer is added or updated. Now you don’t need to distribute a whole new image, just the update, making distributing Docker images faster and simpler.
Docker registries:
Docker containers:
Docker容器的运行
实例1:$ docker run -i -t ubuntu /bin/bash
运行时,传入的参数至少包含:
1.容器从那个镜像中创建,如ubuntu
2.在容器中运行的命令,如/bin/bash
运行上述命令后,Docker引擎的处理流程
1.拉去unbuntu镜像。首先检测是否存在镜像,如果本地不存在,则回去Docker公共库中获取。
2.创建一个新的容器。
3.分配文件系统,加载只读层。The container is created in the file system and a read-write layer is added to the image
4.分配网络接口,使得运行容器可以和本地机通信
5.分配IP地址: Finds and attaches an available IP address from a pool.
6.执行命令: Runs your application, and;
7.捕获运行结果,并输出: Connects and logs standard input, outputs and errors for you to see how your application is running.
Docker底层用到的技术
Namespaces:
Docker takes advantage of a technology called namespaces to provide the isolated workspace we call the container. When you run a container, Docker creates a set of namespaces for that container.
This provides a layer of isolation: each aspect of a container runs in its own namespace and does not have access outside of it.
Some of the namespaces that Docker Engine uses on Linux are:
The pid namespace: Process isolation (PID: Process ID).
The net namespace: Managing network interfaces (NET: Networking).
The ipc namespace: Managing access to IPC resources (IPC: InterProcess Communication).
The mnt namespace: Managing mount-points (MNT: Mount).
The uts namespace: Isolating kernel and version identifiers. (UTS: Unix Timesharing System),如主机名等.
Control Groups:管理隔离的资源,如pid,网络等。
主要功能:资源限制,优先级设定,资源计量,资源控制
Docker Engine on Linux also makes use of another technology called cgroups or control groups. A key to running applications in isolation is to have them only use the resources you want. This ensures containers are good multi-tenant citizens on a host. Control groups allow Docker Engine to share available hardware resources to containers and, if required, set up limits and constraints. For example, limiting the memory available to a specific container.
结合control group和namespace,Docker具有如下能力:

区分:namespace,cgroup:
有了namespace,使得不同的进程,容器对资源有不同的可见性,如进程1创建的文件对进程2是不可见的,进程1对系统所做的修改,如改了主机名,对进程2是不可间的。
有了cgroup,可以对不同的namespace进行跟细致的管理,如进程1能用多少CPU资源,能用多少内存等
Union file systems:
Union file systems, or UnionFS, are file systems that operate by creating layers, making them very lightweight and fast. Docker Engine uses union file systems to provide the building blocks for containers. Docker Engine can make use of several union file system variants including: AUFS, btrfs, vfs, and DeviceMapper.
(关于DeviceMapper,见下面)
Container format:
Docker Engine combines these components into a wrapper we call a container format. The default container format is called libcontainer. In the future, Docker may support other container formats, for example, by integrating with BSD Jails or Solaris Zones.
Device Mapper
http://www.ibm.com/developerworks/cn/linux/l-devmapper/
Device mapper 是 Linux 2.6 内核中提供的一种从逻辑设备到物理设备的映射框架机制,在该机制下,用户可以很方便的根据自己的需要制定实现存储资源的管理策略,当前比较流行的 Linux 下的逻辑卷管理器如 LVM2(Linux Volume Manager 2 version)、EVMS(Enterprise Volume Management System)、dmraid(Device Mapper Raid Tool)等都是基于该机制实现的。理解该机制是进一步分析、理解这些卷管理器的实现及设计的基础。通过本文也可以进一步理解 Linux 系统块一级 IO的设计和实现。
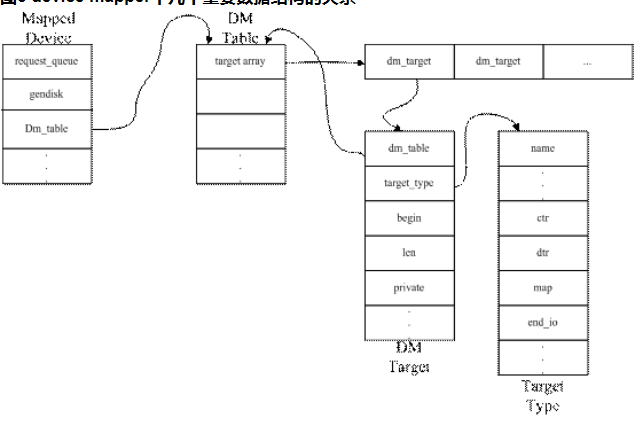
Device Mapper 是 Linux2.6 内核中支持逻辑卷管理的通用设备映射机制,它为实现用于存储资源管理的块设备驱动提供了一个高度模块化的内核架构,如图 1。
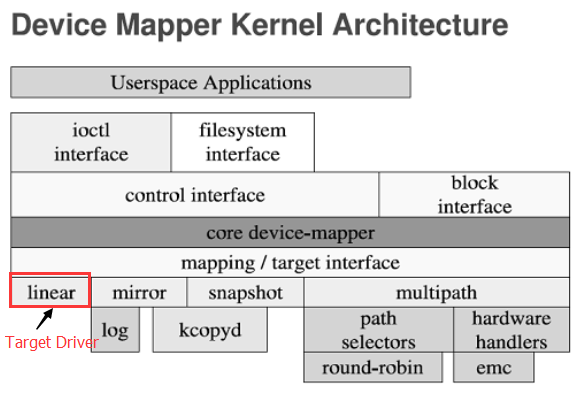
在内核中它通过一个一个模块化的 target driver 插件实现对 IO 请求的过滤或者重新定向等工作,当前已经实现的 target driver 插件包括软 raid、软加密、逻辑卷条带、多路径、镜像、快照等,图中 linear、mirror、snapshot、multipath 表示的就是这些 target driver。Device mapper 进一步体现了在 Linux 内核设计中策略和机制分离的原则,将所有与策略相关的工作放到用户空间完成,内核中主要提供完成这些策略所需要的机制。Device mapper 用户空间相关部分主要负责配置具体的策略和控制逻辑,比如逻辑设备和哪些物理设备建立映射,怎么建立这些映射关系等等,而具体过滤和重定向 IO 请求的工作由内核中相关代码完成。因此整个 device mapper 机制由两部分组成–内核空间的 device mapper 驱动、用户空间的device mapper 库以及它提供的 dmsetup 工具。在下文中,我们分内核和用户空间两部分进行介绍。
内核部分
(1)重要概念
Device mapper 在内核中作为一个块设备驱动被注册的,它包含三个重要的对象概念,mapped device、映射表、target device。Mapped device 是一个逻辑抽象,可以理解成为内核向外提供的逻辑设备,它通过映射表描述的映射关系和 target device 建立映射。
从 Mapped device 到一个 target device 的映射表由一个多元组表示,该多元组由表示 mapped device 逻辑的起始地址、范围、和表示在 target device 所在物理设备的地址偏移量以及target 类型等变量组成(这些地址和偏移量都是以磁盘的扇区为单位的,即 512 个字节大小)。
Target device 表示的是 mapped device 所映射的物理空间段,对 mapped device 所表示的逻辑设备来说,就是该逻辑设备映射到的一个物理设备。
Device mapper 中这三个对象和 target driver 插件一起构成了一个可迭代的设备树。在该树型结构中的顶层根节点是最终作为逻辑设备向外提供的 mapped device,叶子节点是 target device 所表示的底层物理设备。最小的设备树由单个 mapped device 和 target device 组成。每个 target device 都是被mapped device 独占的,只能被一个 mapped device 使用。一个 mapped device 可以映射到一个或者多个 target device 上,而一个 mapped device 又可以作为它上层 mapped device的 target device 被使用,该层次在理论上可以在 device mapper 架构下无限迭代下去。
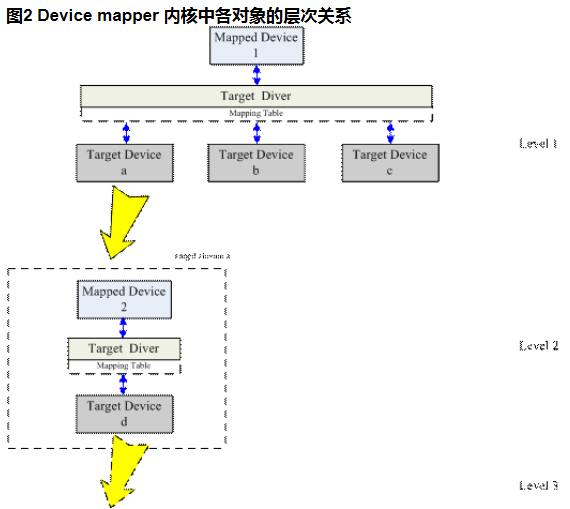
Device mapper 的内核相关代码已经作为 Linux 2.6 内核发布版的一部分集成到内核源码中了,相关代码在内核源码的 driver/md/ 目录中,其代码文件可以划分为实现 device mapper 内核中基本架构的文件和实现具体映射工作的 target driver 插件文件两部分。文章下面的分析结果主要是基于上述源码文件得到的。
在图2 中我们可以看到 mapped device1 通过映射表和 a、b、c 三个 target device 建立了映射关系,而 target device a 又是通过 mapped device 2 演化过来,mapped device 2 通过映射表和 target device d 建立映射关系。
我们进一步看一下上述三个对象在代码中的具体实现,dm.c 文件定义的 mapped_device 结构用于表示 mapped device,它主要包括该 mapped device 相关的锁,注册的请求队列和一些内存池以及指向它所对应映射表的指针等域。
Mapped device 对应的映射表是由 dm_table.c 文件中定义的 dm_table 结构表示的,该结构中包含一个 dm_target结构数组,dm_target 结构具体描述了 mapped_device 到它某个 target device 的映射关系。而在 dm_table 结构中将这些 dm_target 按照 B 树的方式组织起来方便 IO 请求映射时的查找操作。Dm_target 结构具体记录该结构对应 target device 所映射的 mapped device 逻辑区域的开始地址和范围,同时还包含指向具体 target device 相关操作的 target_type 结构的指针。Target_type 结构主要包含了 target device 对应的 target driver 插件的名字、定义的构建和删除该类型target device的方法、该类target device对应的IO请求重映射和结束IO的方法等。而表示具体的target device的域是dm_target中的private域,该指针指向mapped device所映射的具体target device对应的结构。表示target device的具体结构由于不同的target 类型而不同,比如最简单的线性映射target类型对应target device的结构是dm-linear.c文件中定义的linear_c结构。其定义如下:
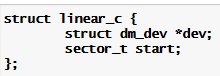
该target device的定义相当简单,就只包括了表示对应物理设备的dm_dev结构指针和在该物理设备中以扇区为单位的偏移地址start。上述几个数据结构关系如图3所示:
(2)内核中建立过程
在下面我们结合具体的代码简要介绍下在内核中创建一个mapped device的过程:
1、 根据内核向用户空间提供的ioctl 接口传来的参数,用dm-ioctl.c文件中的dev_create函数创建相应的mapped device结构。这个过程很简单,主要是向内核申请必要的内存资源,包括mapped device和为进行IO操作预申请的内存池,通过内核提供的blk_queue_make_request函数注册该mapped device对应的请求队列dm_request。并将该mapped device作为磁盘块设备注册到内核中。
2、 调用dm_hash_insert将创建好的mapped device插入到device mapper中的一个全局hash表中,该表中保存了内核中当前创建的所有mapped device。
3、 用户空间命令通过ioctl调用table_load函数,该函数根据用户空间传来的参数构建指定mapped device的映射表和所映射的target device。该函数先构建相应的dm_table、dm_target结构,再调用dm-table.c中的dm_table_add_target函数根据用户传入的参数初始化这些结构,并且根据参数所指定的target类型,调用相应的target类型的构建函数ctr在内存中构建target device对应的结构,然后再根据所建立的dm_target结构更新dm_table中维护的B树。上述过程完毕后,再将建立好的dm_table添加到mapped device的全局hash表对应的hash_cell结构中。
4、 最后通过ioctl调用do_resume函数建立mapped device和映射表之间的绑定关系,事实上该过程就是通过dm_swap_table函数将当前dm_table结构指针值赋予mapped_device相应的map域中,然后再修改mapped_device表示当前状态的域。
通过上述的4个主要步骤,device mapper在内核中就建立一个可以提供给用户使用的mapped device逻辑块设备。
(3)IO流
Device mapper本质功能就是根据映射关系和target driver描述的IO处理规则,将IO请求从逻辑设备mapped device转发相应的target device上。Device mapper处理所有从内核中块一级IO子系统的generic_make_request和submit_bio接口中定向到mapped device的所有块读写IO请求。IO请求在device mapper的设备树中通过请求转发从上到下地进行处理。当一个bio请求在设备树中的mapped deivce向下层转发时,一个或者多个bio的克隆被创建并发送给下层target device。然后相同的过程在设备树的每一个层次上重复,只要设备树足够大理论上这种转发过程可以无限进行下去。在设备树上某个层次中,target driver结束某个bio请求后,将表示结束该bio请求的事件上报给它上层的mapped device,该过程在各个层次上进行直到该事件最终上传到根mapped device的为止,然后device mapper结束根mapped device上原始bio请求,结束整个IO请求过程。
Bio在device mapper的设备树进行逐层的转发时,最终转发到一个或多个叶子target节点终止。因为一个bio请求不可以跨多个target device(亦即物理空间段), 因此在每一个层次上,device mapper根据用户预先告知的mapped device 的target映射信息克隆一个或者多个bio,将bio进行拆分后转发到对应的target device上。这些克隆的bio先交给mapped device上对应的target driver上进行处理,根据target driver中定义的IO处理规则进行IO请求的过滤等处理,然后再提交给target device完成。上述过程在dm.c文件中的dm_request函数中完成。Target driver可以对这些bio做如下处理:
1、 将这些bio在本驱动内部排队等待以后进行处理;
2、 将bio重新定向到一个或多个target device上或者每个target device上的不同扇区;
3、 向device mapper返回error 状态。
IO请求就按照上文中描述的过程在图2中所示的设备树中逐层进行处理,直到IO请求结束。
(4)小结
Device mapper在内核中向外提供了一个从逻辑设备到物理设备的映射架构,只要用户在用户空间制定好映射策略,按照自己的需要编写处理具体IO请求的target driver插件,就可以很方便的实现一个类似LVM的逻辑卷管理器。Device mapper以ioctl的方式向外提供接口,用户通过用户空间的device mapper库,向device mapper的字符设备发送ioctl命令,完成向内的通信。它还通过ioctl提供向往的事件通知机制,允许target driver将IO相关的某些事件传送到用户空间。
用户空间部分
Device mapper在用户空间相对简单,主要包括device mapper库和dmsetup工具。Device mapper库就是对ioctl、用户空间创建删除device mapper逻辑设备所需必要操作的封装,dmsetup是一个提供给用户直接可用的创建删除device mapper设备的命令行工具。因为它们的功能和流程相对简单,在本文中对它们的细节就不介绍了,用户空间主要负责如下工作:
1、 发现每个mapped device相关的target device;
2、 根据配置信息创建映射表;
3、 将用户空间构建好的映射表传入内核,让内核构建该mapped device对应的dm_table结构;
4、 保存当前的映射信息,以便未来重新构建。
以下我们主要通过实例来说明dmsetup的使用,同时进一步说明device mapper这种映射机制。用户空间中最主要的工作就是构建并保存映射表,下面给出一些映射表的例子:
格式:起始扇区号 扇区树 映射方式 物理空间(target device) 物理空间的起始位置
1)例1
0 1024 linear /dev/sda 204
1024 512 linear /dev/sdb 766
1536 128 linear /dev/sdc 0
将逻辑设备0~1023扇区、1024~1535扇区以及1536~1663三个地址范围分别以线形映射的方式映射到/dev/sda设备第204号扇区、/dev/sdb设备第766号扇区和/dev/sdc设备的第0号扇区开始的区域。
2) 例2
0 2048 striped 2 64 /dev/sda 1024 /dev/sdb 0
将逻辑设备从0号扇区开始的,长度为2048个扇区的段以条带的方式映射的到/dev/sda设备的第1024号扇区以及/dev/sdb设备的第0号扇区开始的区域。同时告诉内核这个条带类型的target driver存在2个条带设备与逻辑设备做映射,并且条带的大小是64个扇区,使得驱动可以该值来拆分跨设备的IO请求。
3) 例3
0 4711 mirror core 2 64 nosync 2 /dev/sda 2048 /dev/sdb 1024
将逻辑设备从0号扇区开始的,长度为4711个扇区的段以镜像的方式映射到/dev/sda设备的第2048个扇区以及/dev/sdb设备的第1024号扇区开始的区域。
映射表确定后,创建、删除逻辑设备的操作就相对简单,通过dmsetup如下命令就可以完成相应的操作。
dmsetup create 设备名 映射表文件 /* 根据指定的映射表创建一个逻辑设备 */
dmsetup reload 设备名 映射表文件 /* 为指定设备从磁盘中读取映射文件,重新构建映射关系 */
dmsetup remove 设备名 /* 删除指定的逻辑设备 */
图4 根据例子1中映射表在内核中建立的逻辑设备
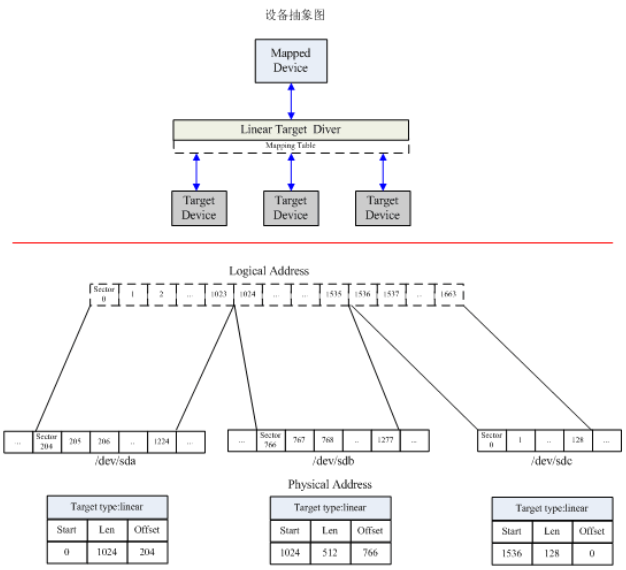
当用户空间根据映射表下达创建逻辑设备命令后,device mapper在内核中就根据传入的参数和映射关系建立逻辑地址到物理地址的映射关系。根据映射表例子1中的映射关系建立的设备如图4所示,图中的下半部分就抽象地描绘出了按照该映射表在内核中建立的逻辑地址到物理地址的映射关系。
Device mapper的用户空间部分对开发者要实现自己的存储管理工具来说是可选的,事实上,很多我们常见的逻辑卷管理器,比如LVM2、dmraid等工具都利用device mapper的提供的device mapper用户空间库,根据自己的管理需求建立独立的一套管理工具,而并没有使用它提供的dmsetup工具,甚至IBM的开源项目企业级的逻辑卷管理系统-EVMS,在实现中都没有采用device mapper的用户空间库,完全根据内核中的ioctl定义实现了一套自己的函数库。
(1)Target Driver
Device mapper提供了一个统一的架构,通过target driver 插件的方式允许用户根据实际的需要指定自己的IO处理规则,因此target driver充分体现了device mapper的灵活性。在上文中我们已经不止一次的提到过target driver,也描述过target driver的功能,在这里我们结合最简单的linear target driver具体介绍target driver的实现。
Target driver主要定义对IO请求的处理规则,在device mapper中对target driver的操作已定义好了统一的接口,在实现中该接口由我们上文提到的target_type结构中定义,它定义了以下target driver的方法:
1、 构建target device 的方法;
2、 删除target device 的方法;
3、 Target的映射IO请求的方法;
4、 Target结束IO请求的方法;
5、 暂停target device读写的方法;
6、 恢复target device读写的访问;
7、 获取当前target device状态的访问;
8、 Target 处理用户消息的方法;
用户可以根据具体需求选择性地实现上述方法,但一般最少要实现前3种方法,否则在device mapper下不能够正常的工作。linear target driver就只实现了前3种方法和方法7,它完成逻辑地址空间到物理地址空间的线性映射,可以将多个物理设备以线性连接的方式组成一个逻辑设备,就如图4中描述的那样,通过linear target driver将/dev/sda、/dev/sdb、/dev/sdc的三段连续空间组成了一个大的逻辑块设备。Linear target的实现很简单,它的创建和删除方法主要完成申请和释放描述linear target device所用结构的内存资源;IO映射处理方法的实现更是简单,如下代码所示:
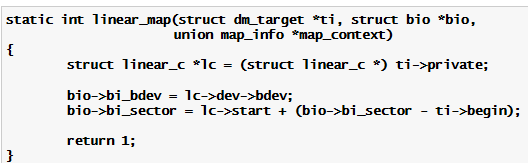
该映射方法就是将发送给逻辑设备mapped device的bio请求,根据映射关系以线性的方式重新定向到linear target device所表示物理设备的相应位置,如代码所示具体实现方法就是修改bio的bi_bdev设备指针为target device对应的设备指针,并根据target device的起始地址和该bio请求在mapped device设备上的偏移值改变IO请求开始的扇区号bi_sector,从而完成IO请求的重定向。
其他target driver的实现也都大同小异,按照device mapper所定义的接口规范,结合自己需要的功能进行实现即可,这里就不一一介绍了,有兴趣的读者可以看内核中具体的target driver代码。
Docker中的网络架构
Docker中的网络架构:
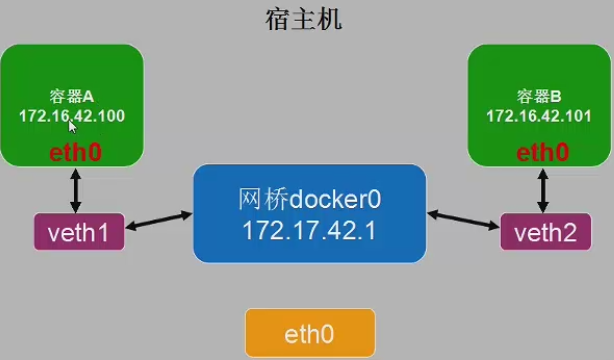
容器中的网络设备:eth0
宿主机中的设备veth1,veth2,每台容器中的网络设备eth0都会和宿主机中的一个网络设备veth相对应。任何发送到eth0中的数据,都会转发到相连的veth设备中,反之亦然,发送到veth1中的数据都会自动发送到对应的容器中的网络设备中。
容器间的相关访问、容器宿主机间的访问:
通过网桥技术,实现容器和宿主机的相互网络通信
让容器访问外部世界:
容器的网络,实际上隐藏在宿主机网络后面的。

2.安装
Ubuntu系统下的安装
注意:Docker currently only supports 64bit platforms.
安装条件:
1.64位系统,通过 uname -a命令检测
2.device-mapper驱动,通过查看 ls -l /sys/class/misc/device-mapper下的文件:存在映射文件,则是可以的
root@luodan-VM:/home/luodan/Docker# ls -l /sys/class/misc/device-mapper
lrwxrwxrwx 1 root root 0 7月 30 21:07 /sys/class/misc/device-mapper -> ../../devices/virtual/misc/device-mapper

安装过程:
1.sudo apt-get install -y curl
sudo curl -sSL https://get.docker.com -o docker_download_script.sh
sudo sh docker_download_script.sh
4.执行3之后Docker就安装完毕,通过 docker version来检查安装的版本
5.当前用户添加执行Docker操作的权限(就不用每次都用sudo了)
sudo gropadd docker //创建Docker用户组
sudo gpasswd -a username(你想添加的用户名) docker //将当前用户添加用户组
sudo docker restart
(需要重新登录)
3.基本命令
镜像相关
镜像处理
docker images [optionss] [repository]
-a,--all=false
-f ,--filter=[]
--no-trunc=false(是否输出镜像id时,做截断处理)
--q,--quiet=false(只显示镜像id)例子:docker images //显示本地镜像列表
(显示的镜像id进行了截断输出)

可以用 repository:tag辨识一个镜像,对应唯一一个镜像ID,如果没有使用tag,则是表示标签为latest的镜像。
出现的没有repository,tag的镜像表示的是中间层镜像
可以为一个镜像创建多个标签,相当于为镜像id取了多个别名。
docker inspect [optionss] [repository]
远程查找对象:
1.直接从docker hub网络上查找
2.通过docker命令
docker search [optionss] term
--automated=false :只会显示自动化创建的
--no-trunc=fasle :don't trunc
-s,--stars=0 :只显示至少有x星级的镜像例子:docker images centos //显示centos仓库中的镜像
远程获取镜像
docker pull [optionss] Name[:tag]
-a,-all-tags=false:
–registry-mirror:使用其他镜像下载网址
使用该选项,需要:
在Docker配置文件/etc/default/docker文件中添加Docker镜像下载网址
通过添加一行:DOCKER_OPTS=”–registry-mirror=http://….”
远程推送镜像
docker push [optionss] Name[:tag]
推送时,需要登录推送地的帐号(并不会将所有的东西推送上去,只是将修改了的部分推送上去)
构建Docker镜像
构建Docker镜像,保存对容器的修改和重复使用(可以将软件的形式打包并分发服务)
两种方式:
docker commit :通过容器构建
docker build :通过Dockerfile文件构建
方式一: docker commit [options] container_name [repositroy[:tag] ]
-a,--author="":
-m,--message="":构建
-p
该种方式就是你对某一个基础容器做一些操作后,保存操作,保存容器成一个新的容器,这个新的容器保存了你之前所做的修改。
方式二:通过Dockerfile文件构建
步骤1:创建dockerfile
步骤2:运行docker build命令
该种方式就是通过一个dockerfile,指定在基础容器中所要进行的命令,在执行docker build命令执行时,一步步的执行docker file中的命令,完成新的容器的创建。
Dockerfile的执行过程:
1.通过基础镜像创建一个基本容器
2.执行一条Dockerfile中的一条指令
3.执行docker comit命令,提交指令,创建一个新的镜像
4.根据新的镜像,创建一个新的容器,执行一条新的指令,重复上述过程。
可通过docker histry命令查看镜像的构建过程
补充一下Docker file的相关知识
Dockerfile指令
包涵两种模式:
1.注释,通过#标识
2.指令,以大小的指令开始
指令类型有:
FROM指令:镜像来源
MAINTAINER指令:镜像维护者信息
RUN指令:包涵两种模式:shell模式,exec模式。构建容器的指令。
EXPOSE指令:指定运行镜像的端口号(实际在运行Docker容器时,还需要指定,这里指定只是告诉Docker应用可能会使用这些端口后)
CMD指令:容器运行时默认指令。如果你通过docker run指定了运行的命令,则这些指令不会执行。
ENTRYPOINT指令:类似于CMD指令,但是不会被docker run指定的命令覆盖,如果要覆盖,则需要通过在run命令中加上–entry参数来覆盖
ADD指令和COPY指令:将文件拷贝到Dockerfile构建的容器镜像中(也可以是远程文件,但是不推荐使用,在网络文件传输时,推荐get等网络命令)。
格式:
ADD src des
copy src des
区别:
ADD:包涵解压缩等功能,如果只是简单的拷贝,推荐使用copy指令
VOLUME指令:为创建的容器镜像中添加卷
WORKDIR 指令:
ENV 指令:
USER 指令:指定运行的Docker容器时,以什么身份运行登录容器
ONBUILD 指令:触发器
Docker容器相关的命令
关于守护式容器,特点:
1.能够长期运行
2.没有交互式回话
3.适合运行应用程序和服务
1.普通方式启动容器
Docker run
2.以交互式方式启动容器
Docker run -i -t image /bin/bash
3.以守护模式运行启动容器
两种方式:
一种方式:首先以交互式方式启动容器Docker run -i -t image /bin/bash,然后不以exit命令退出容器,而是以Ctr+p,Ctr+q命令退出,则该容器以守护模式运行。之后要连接到该容器,可通过attach命令连接上去
方式二:在启动容器时,加上-d参数,如docker run -d
4.查看容器日志:
docker logs [-f] [-t] [–tail]
5.查看容器内进程:
docker ps
6.查看容器内运行的进程情况:
docker top
7.在运行中的容器中启动新的进程:
docker exe
8.停止运行中的容器:
docker stop 容器名:给运行中的容器发送停止信息,然后等待容器停止
dockr kill 容器名:直接停止容器
扩展命令
以后补充,图片太麻烦了
4.使用实例
以后补充,图片太麻烦了

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 32
32 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)