揭秘 AWS Lambda 并发以及 Lambda 在高流量下的实际扩展能力?
简介
围绕 AWS lambda 构建的无服务器应用程序为组织减少了很多担忧。他们不必担心基础设施的管理或维护。 AWS 负责处理它,包括容量预置、自动扩展、监控和日志记录。但这还不是全部,如果您不清楚 lambda 如何扩展以及 AWS 中的并发性如何工作,就会有一些“问题”。在本文中,让我们尝试了解并发在 Lambda 中是如何工作的,以及如何避免由于并发原因导致的 Lambda Throttling。
Lambda 并发
简单来说,并发可以定义为在给定时间为请求提供服务的实例数量。
调用函数时,会创建一个执行环境(即实例)来处理请求。请求完成后,实例会保持温暖一段时间。如果发出另一个请求,则现有实例为该请求提供服务。但是,如果第一个请求没有完成并且发出了第二个请求,则创建另一个 lambda 实例,使并发为两个,依此类推。
Lambda 根据需求预置和取消预置实例的能力称为 Auto Scaling。当流量减少时,额外的实例会停止,因此在成本方面具有巨大优势,因为您只需为实例服务请求的时间付费。
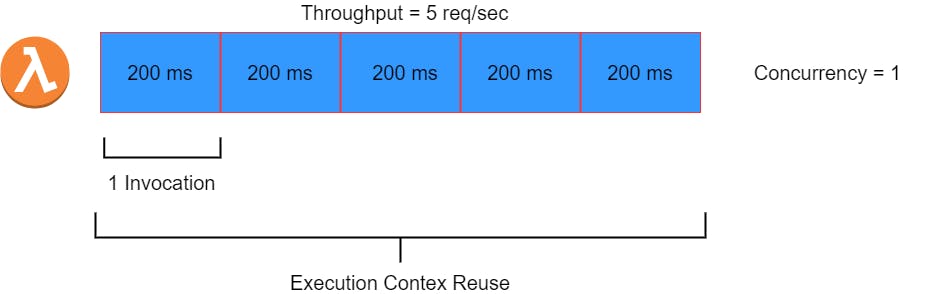
考虑上面的例子,lambda 需要 200 毫秒来处理一个请求。如果 lambda 每秒(1000 毫秒)接收 5 个请求,那么同一个实例可以处理它。所以 lambda 函数的并发性是 1。但是如果在那一秒内再发出一个请求,则会创建另一个实例,从而将并发性增加到 2。
并发可以使用以下公式计算 -
平均函数执行时间(秒)* avg req/sec u003d 并发估计
.2 秒 * 5 请求/秒 u003d 1
在函数处理程序之外定义的任何配置都可以跨调用重用,如上图中的执行上下文重用所示。随着执行时间的增加,函数的并发性也会增加。因此,如果同一个函数需要 1 秒来处理一个请求并且它接收到 5 个请求/秒,那么该函数的并发将变为 5。
管理 Lambda 并发
当我们考虑无服务器时,总是假设 lambda 可以扩展以每秒处理数千个请求。确实如此,但您账户中某个区域内的所有 lambda 函数都有区域并发限制。
区域并发限制设置为 1000,也称为未预留并发。一个账户中一个区域内的所有函数共享这个配额。如果并发超过 1000,所有功能将被限制,请求将无法处理。
这是一个软限制,您可以请求 AWS Support 通过创建配额增加请求来增加此限制。
有两种类型的并发 -
- 预留并发
如果你想将一部分非预留并发分配给一个函数,你可以使用预留并发来设置它。没有其他函数可以使用这种并发性。您最多可以为您账户中的任何功能预留总未预留并发减去 100。因此,如果 Unreserved Concurrency 为 1000,您可以将 900 个保留并发分配给您想要的函数,将 100 个保留给所有剩余的函数。
有时您不希望某个特定函数使用过多的并发,因此您使用保留并发来限制其使用量,使其不受区域中可用的总并发的影响。如果函数需要超出其保留并发的并发,它会自动限制。
如果要限制函数,可以将保留并发设置为零。这会阻止所有请求失败,直到您取消限制。
- 预配置并发
在了解预置并发之前,让我们先了解一下 Lambda 中的冷启动 -
当函数没有为任何请求提供服务时,实例将终止并且函数进入空闲状态。下次调用该函数时,需要一些时间来设置和供应实例。在函数执行时间中引入的这种延迟称为冷启动。
在某些情况下,您无法承受这样的延误。为了克服这个问题,我们可能需要让函数的执行环境始终保持正常运行。 AWS 提出了预置并发的概念,我们在其中指定我们希望有多少实例始终保持温暖并准备好为请求提供服务。
预置并发可以分配到函数的预留并发或区域配额限制。因此,您不能分配比函数的保留并发更多的预置并发。
需要注意的一件重要事情是,预置并发除了正常的 lambda 定价之外还具有成本影响。您为预置的并发量和配置的时间段付费。为了降低预置并发的成本,您可以使用自动缩放来为预测性工作负载分配预置并发。
Lambda 缩放
到目前为止,我们知道有一个默认的未保留并发设置为 1000。这意味着超过 1000 个并发执行的所有请求都会受到限制。这是一个软限制,因此我们可以根据您的应用程序服务的流量将其增加到数十万。
即使您将区域配额增加到 1000 以上,还有一个硬性限制可能会限制您的功能。这个限制被称为Burst Limit,它在不同的区域变化在500到3000之间。在初始突发之后,您的函数可以每分钟添加500个实例,直到达到预留并发或区域配额。在此时间范围内的其他请求将受到限制。我们将举例说明 Burst Limit 的工作原理。
示例场景
假设您有一个简单的无服务器应用程序,其中 API 网关、一个 Lambda 和 DynamoDB 部署在 us-east-1 区域。它的区域配额为 1000,Burst Limit 为 3000,您尚未增加区域配额。
基线定义应用程序始终可以服务 1000 个并发执行。
现在应用程序开始每秒接收恒定的 4000 个请求,每个 lambda 需要一秒钟才能完成。这意味着应用程序期望运行 4000 个函数实例,即并发性为 4000。
使用默认无保留并发
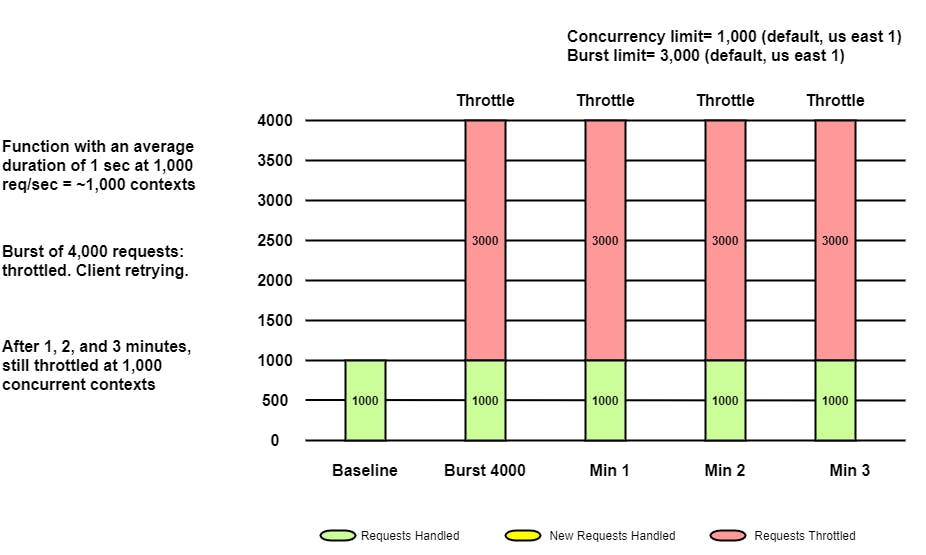 如果应用程序每秒持续接收 4000 个请求,则每秒只会处理 1000 个请求,因为它已经达到了区域配额。在这种情况下,只能配置 1000 个实例,因为所有可能需要额外实例的请求都将受到限制。
如果应用程序每秒持续接收 4000 个请求,则每秒只会处理 1000 个请求,因为它已经达到了区域配额。在这种情况下,只能配置 1000 个实例,因为所有可能需要额外实例的请求都将受到限制。
只要相同的请求到来,只有 1000 个会被提供,3000 个会被限制。
增加区域配额
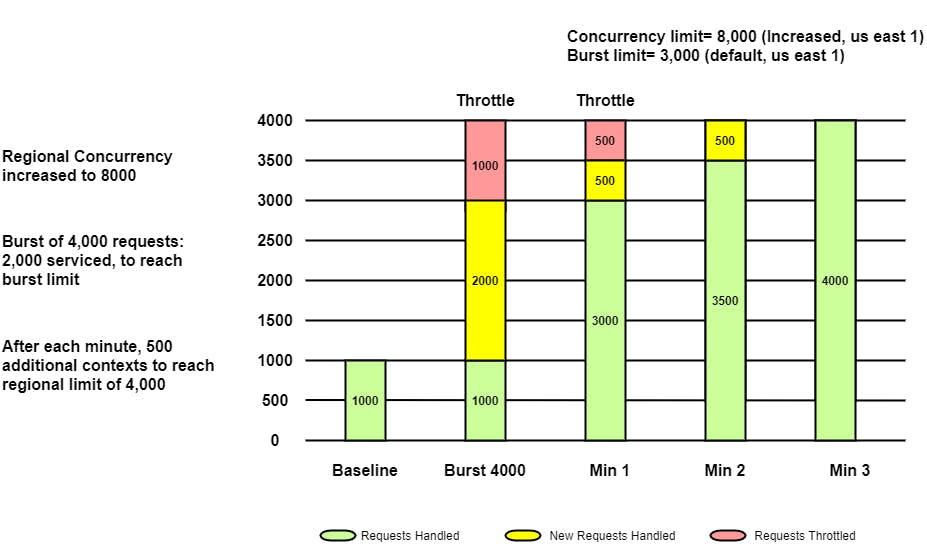
现在您知道您的应用程序需要 4000 次并发执行,您请求 AWS 将配额增加到 8000(任何超过 4000 的)。请记住,Burst 限制是一个硬限制,因此即使您增加了区域配额,也不能保证应用程序的无限制行为。
早些时候,该应用程序使用 1000 个实例,现在随着区域限制的增加,该功能突然爆发以供应额外的实例,最高达到 Burst Limit,即在 us-east-1 的情况下为 3000。因此额外供应了 2000 个实例。
对于 4000 个请求的初始突发,仅提供 3000 个(突发限制)请求。此时将限制 1000 个请求。一分钟后,额外配置了 500 个实例,从而为 3500 个请求提供服务并限制 500 个请求。在第 2 分钟,又提供了 500 个实例,并为所有 4000 个请求提供服务。
这就是 Burst Limit 每分钟添加 500 个实例来服务流量的方式。但很明显,lambda 仍在限制某些请求长达一分钟。
使用预置并发
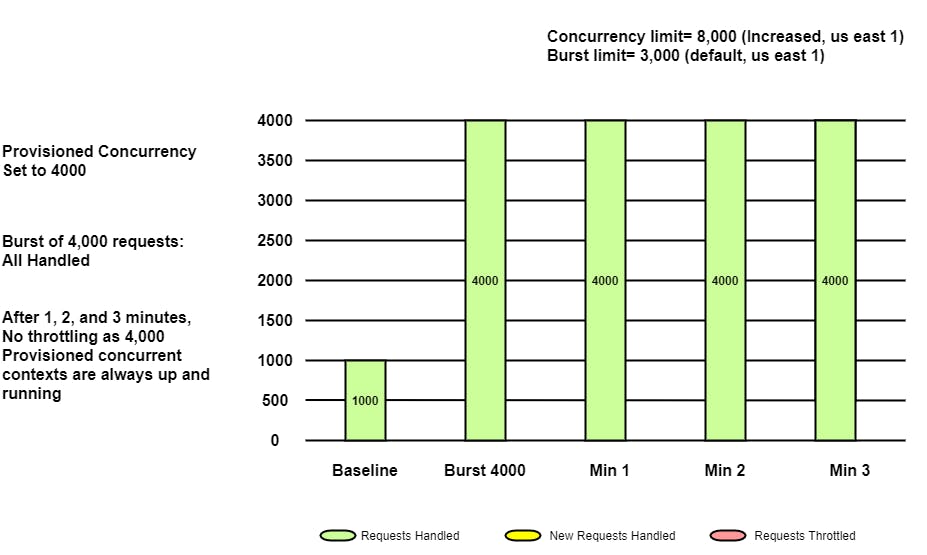
即使在增加区域配额后,我们也意识到 Burst 限制导致功能节流。为了克服这个问题,可以使用预置并发。因此,如果我们将预置并发分配给 4000,则任何时候都有 4000 个 lambda 实例始终启动并运行。
在这种情况下,如果应用程序每秒接收 4000 个请求,则所有请求都将在没有限制的情况下得到处理。由于它已经超过了 Burst Limit,即使请求数量增加,这些请求也会被提供到增加的区域限制,这里是 8000。
结论
通过了解并发在 Lambda 中的工作原理、什么是硬限制和软限制、如何增加这些限制以及如何使用预置并发,我们学到了一种更好的方法来构建高可用性无服务器应用程序,而不会因为 Lambda 并发而受到限制。
参考文献
docs.aws.amazon.com/lambda/latest/dg/config..docs.aws.amazon.com/lambda/latest/dg/invoca..aws.amazon.com/blogs/aws /new-provisioned-co..

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献35526条内容
已为社区贡献35526条内容

所有评论(0)