生产环境中的 Python ML - 第 1 部分:FastAPI + Celery 与 Docker
动机
有没有发现自己围绕全新的 ML 模型构建 API,浏览以前的项目以查找配置文件、Dockerfile、docker-compose.yaml 等?您刚刚构建的基于微服务的新应用程序是否与您过去构建的其他应用程序具有相同的产品结构和技术?
将您的唯一产品代码视为接受输入 X 并返回输出 F(X)u003dY 的黑盒 F。虽然 X、F 和 Y 可能因项目而异,但围绕 F 并移动 X 和 Y 的所有事物通常具有相似的结构,如果不相同的话。
出于这个原因,我相信以同样的方式样板扩展可以防止 web 开发人员一遍又一遍地重写相同的 HTML 标签,让他们专注于页面内容,可以有一种方法来防止软件工程师像你我一样一遍又一遍地重写相同的 Dockerfiles、docker-compose.yaml、配置,让我们只专注于我们全新的产品。
目标
正如标题所示,最终目标是构建一个可移植的、通用的、可用于生产的 Python API 项目框架,该框架包含使用可用的最佳实践打包和配置的所有微服务,允许开发人员和研究人员只关注他们的业务逻辑产品。
骨架旨在自动化以下流程:
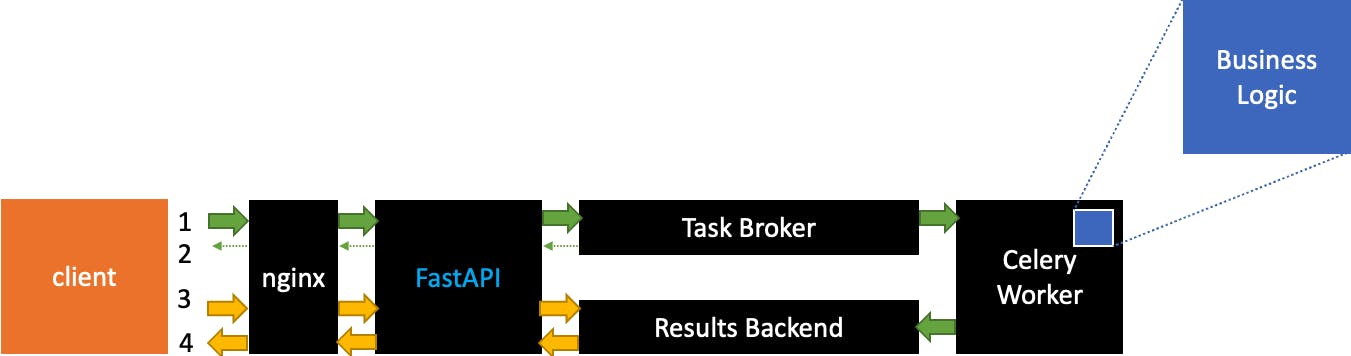
1.客户端向API发送一个包含X的请求
- API 以 Process ID 回复客户端。到那时,API 已经向 Task Broker 队列添加了一个新作业,该任务将由第一个可用的 celery worker 异步执行,结果将与 Process ID 一起保存在 Results Backend 中。客户端没有等待任务执行。
3.客户端可以询问关联任务的当前状态
- 状态与结果一起返回(如果可用)
请注意,业务逻辑和 FastAPI 是蓝色的,因为它们应该是唯一会随着项目而变化的部分,就像 HTML 样板中的 body 标记的内容一样,而所有其余的黑色组件都不应该改变。
概述
您可以在这个存储库中找到整个项目。项目的这个特定状态有一个标签,因此如果将来 repo 发生更改或增长,您将拥有当时或正在编写的版本的 pin。
对于 celery 和 FastAPI 配置,我必须感谢Jonathan Readshaw 撰写的这篇精彩的帖子,因为你会看到它给了我很多启发和帮助。
对于这个元项目,我选择了以下技术:
-
FastAPI用于 API 实现
-
Celery用于异步排队和执行作业
-
RabbitMQ作为 Celery Queue 或 Task Broker
-
Redis作为 Celery 结果后端
-
Nginx作为 web-server/reverse-proxy (本文不包括,将作为未来开发的一部分)
主要结构如下,它遵循前面的块模式:
.
├── .env
├── docker-compose.yaml
├── fast-api-celery
│ ├── Dockerfile.base
│ ├── Dockerfile.custom
│ ├── api
│ ├── logic
│ ├── starter.sh
│ └── worker
├── nginx
│ └── Dockerfile
├── rabbit-mq
│ └── Dockerfile
└── redis
└── Dockerfile
Fast-api-celery 包含三个子文件夹,将在整篇文章中讨论:logic 包含自定义业务逻辑,api 包含API 实现,其中详细信息如路由和模型随逻辑一起变化,并且 worker 包含 Celery Worker 实现。这三个块都运行在同一个 Docker 映像上。
Docker-compose
.
├── .env
├── docker-compose.yaml
在这里,我们定义了所有微服务、它们的名称、它们的启动方式和顺序。
version: "3"
services:
_python_image_build:
build:
context: ./fast-api-celery
dockerfile: Dockerfile.base
image: fast-api-celery-base
command: ["echo", "build completed"] # any linux command which directly terminates.
# RESULTS BACKEND
redis:
build: ./redis
container_name: redis-backend
networks:
- production-boilerplate
ports:
- "6379:6379"
# BROKER
rabbitmq:
build: ./rabbit-mq
container_name: rabbitmq-broker
networks:
- production-boilerplate
ports:
- "5672:5672"
- "15672:15672"
# WORKER
celery:
build:
context: ./fast-api-celery
dockerfile: Dockerfile.custom
image: fast-api-celery-custom
container_name: celery-worker
networks:
- production-boilerplate
environment:
- CELERY_BROKER_URL=${CELERY_BROKER_URL}
- CELERY_BACKEND_URL=${CELERY_BACKEND_URL}
- CELERY_QUEUE=${CELERY_QUEUE}
command: ./starter.sh --target worker
depends_on:
- redis
- rabbitmq
# MONITOR
flower:
image: fast-api-celery-custom
container_name: celery-flower
networks:
- production-boilerplate
environment:
- CELERY_BROKER_URL=${CELERY_BROKER_URL}
- CELERY_BACKEND_URL=${CELERY_BACKEND_URL}
command: ./starter.sh --target flower
ports:
- "5555:5555"
depends_on:
- redis
- rabbitmq
- celery
# API
fastapi:
image: fast-api-celery-custom
container_name: fastapi
networks:
- production-boilerplate
environment:
- CELERY_BROKER_URL=${CELERY_BROKER_URL}
- CELERY_BACKEND_URL=${CELERY_BACKEND_URL}
command: ./starter.sh --target fastapi
ports:
- "8000:80"
depends_on:
- redis
- rabbitmq
- celery
networks:
production-boilerplate:
driver: bridge
-
_ python\image_build 是一个假服务,我用来构建 fast-api-celery-base 映像,然后 FastAPI 和 Celery 将使用该映像
-
redis、rabbitmq 是 Celery 将依赖的服务进行任务排队和结果存储,它们不需要特殊配置
-
celery 利用_python_image_build 服务构建的_fast-api-celery-base_ 镜像。它需要知道代理和后端服务在哪里,它从启动 celery 服务开始
-
flower 实际上是一个'bonus'服务,之前没有提到。就像 celery,但它不会启动 celery 服务,而是启动花服务,该服务监控 celery 工人和任务状态
-
fastapi 和 celery 和 Flower 一样,但在启动时被告知要启动 API 服务
由于我们定义了一个包含所有微服务的 docker 网络,我们可以将 redis 和 rabbitmq 与它们在 docker-compose 中定义的名称链接起来。这是 .env 文件:
CELERY_BROKER_URL=amqp://guest@rabbitmq//
CELERY_BACKEND_URL=redis://redis:6379/0
我们的黑匣子 F
.
├── fast-api-celery
│ ├── logic
│ │ ├── __init__.py
│ │ └── model.py
fast-api-celery/logic 应该是我们放置应用程序业务逻辑的唯一位置。这篇文章的重点不是我们要服务的模型,model.py(我们的F)对于这个例子如下所示:
class FakeModel:
def __init__(self):
self.m = 7.0
self.q = 0.5
def predict(self, x: float) -> float:
y = self.m * x + self.q
return y
我们唯一关心的是它在初始化时会加载一些“权重”,并且它公开了一个 predict 方法,该方法接受输入 X 并返回输出 Y,就像任何 ML 模型无论其任务如何都会做的那样。
现在让我们看看如何为模型服务!
Celery Broker 和后端
.
├── rabbit-mq
│ └── Dockerfile
└── redis
└── Dockerfile
RabbitMQ 和 Redis 只需要启动并运行,目前我们不需要特殊配置。然后我们将告诉 Celery 将这两个容器分别作为 Broker 和 Backend 使用。
RabbitMQ 的 Dockerfile:
FROM rabbitmq:3.10-management
CMD ["rabbitmq-server"]
Redis 的 Dockerfile:
FROM redis
CMD ["redis-server"]
API 和 Worker
API 必须能够从工作程序导入依赖项,例如其任务和用于检索作业结果的 AsynchResult 方法。同时,worker 必须能够从我们自定义的逻辑包中导入依赖,这样所有的 worker 线程都能够执行它的代码。出于这个原因,我构建了一个包含 API、Celery 和模型的所有依赖项的环境的单个映像。
Dockerfiles
.
├── fast-api-celery
│ ├── Dockerfile.base
│ ├── Dockerfile.custom
我最近写了另一篇博文如果使用 Python 和 Poetry 作为包管理器,如何构建优化的 docker 镜像。从那篇文章中,我编写了以下 Dockerfile。
底座
Dockerfile.base
#
# Build image
#
FROM python:3.9-slim-bullseye AS builder
WORKDIR /app
COPY . .
RUN apt update -y && apt upgrade -y && apt install curl -y
RUN curl -sSL https://raw.githubusercontent.com/python-poetry/poetry/master/get-poetry.py | python -
RUN $HOME/.poetry/bin/poetry config virtualenvs.create false
RUN $HOME/.poetry/bin/poetry install --no-dev
RUN $HOME/.poetry/bin/poetry export -f requirements.txt >> requirements.txt
#
# Prod image
#
FROM python:3.9-slim-bullseye AS runtime
WORKDIR /app
COPY --from=builder /app/requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
使用这个 Dockerfile,我们创建了一个名为 fast-api-celery-base 的新基础镜像,它将用作上述所有三个服务的起点。
定制
#
# Customizations
#
FROM fast-api-celery-base
WORKDIR /app
RUN mkdir api worker logic
COPY api ./api
COPY worker ./worker
COPY logic ./logic
COPY starter.sh .
RUN chmod +x starter.sh
ENTRYPOINT ["/bin/bash"]
在这个 Dockerfile.custom 中,我只复制了三个文件夹 api、worker 和 logic。请注意,上面的两个 dockerfile 被拆分以加快开发速度:构建基础环境需要几分钟,并且只有在依赖关系发生变化时才应该完成,而创建最终图像(代码更改)只需要几秒钟。
芹菜
.
├── fast-api-celery
│ └── worker
│ ├── __init__.py
│ ├── celery.py
│ └── tasks.py
如上所述,这部分的灵感来自 Jonathan Readshaw 的这篇文章](https://towardsdatascience.com/deploying-ml-models-in-production-with-fastapi-and-celery-7063e539a5db)的[。我只需要在 include 参数列表中添加“逻辑”字符串,以便每个工作人员在运行时都有其可用的逻辑包。
工人 -celery.py
from celery import Celery
import os
worker = Celery(
"proj",
backend=os.getenv("CELERY_BACKEND_URL"),
broker=os.getenv("CELERY_BROKER_URL"),
include=["worker.tasks", "logic"],
)
# Optional configuration, see the application user guide.
worker.conf.update(
result_expires=3600,
)
if __name__ == "__main__":
worker.start()
任务 -task.py
import importlib
import sys
import logging
from celery import Task
from .celery import worker
class PredictTask(Task):
"""
Abstraction of Celery's Task class to support loading ML model.
"""
abstract = True
def __init__(self):
super().__init__()
self.model = None
def __call__(self, *args, **kwargs):
"""
Load model on first call (i.e. first task processed)
Avoids the need to load model on each task request
"""
if not self.model:
logging.info("Loading Model...")
sys.path.append("..")
module_import = importlib.import_module(self.path[0])
model_obj = getattr(module_import, self.path[1])
self.model = model_obj()
logging.info("Model loaded")
return self.run(*args, **kwargs)
@worker.task(
ignore_result=False,
bind=True,
base=PredictTask,
path=("logic.model", "FakeModel"),
name="{}.{}".format(__name__, "Fake"),
)
def predict(self, x):
return self.model.predict(x)
快速API
.
├── api
│ ├── __init__.py
│ ├── main.py
│ └── models.py
模型 -models.py
这里我们定义了 X 和 Y 的形式。FastAPI 将使用它们来验证用户的输入
from pydantic import BaseModel
class TaskTicket(BaseModel):
"""ID and status for the async tasks"""
task_id: str
status: str
# X
class ModelInput(BaseModel):
"""Model features as input for prediction"""
x: float
# Y
class ModelPrediction(BaseModel):
"""Final result"""
task_id: str
status: str
result: float
端点 -main.py
这里我们定义了两个端点:
-
[POST] /fakemodel/predict 创建新任务并获取任务ID
-
[GET] /fakemodel/result/{task_id} 获取其当前状态
from fastapi import FastAPI
from fastapi.responses import JSONResponse
from celery.result import AsyncResult
from worker.tasks import predict
from .models import ModelInput, TaskTicket, ModelPrediction
app = FastAPI()
@app.post("/fakemodel/predict", response_model=TaskTicket, status_code=202)
async def schedule_prediction(model_input: ModelInput):
"""Create celery prediction task. Return task_id to client in order to retrieve result"""
task_id = predict.delay(dict(model_input).get("x"))
return {"task_id": str(task_id), "status": "Processing"}
@app.get(
"/fakemodel/result/{task_id}",
response_model=ModelPrediction,
status_code=200,
responses={202: {"model": TaskTicket, "description": "Accepted: Not Ready"}},
)
async def get_prediction_result(task_id):
"""Fetch result for given task_id"""
task = AsyncResult(task_id)
if not task.ready():
print(app.url_path_for("schedule_prediction"))
return JSONResponse(
status_code=202, content={"task_id": str(task_id), "status": "Processing"}
)
result = task.get()
return {"task_id": task_id, "status": "Success", "result": str(result)}
启动
由于 Celery、Flower 和 FastAPI 都有相同的图像和相同的文件,我们需要区分它们的启动命令。使用此实用程序脚本,我们使用 --target 参数来控制来自 docker-compose 文件的命令。
#!/bin/bash
while [ $# -gt 0 ] ; do
case $1 in
-t | --target) W="$2" ;;
esac
shift
done
case $W in
worker) celery --broker ${CELERY_BROKER_URL} --result-backend ${CELERY_BACKEND_URL} -A worker.celery worker --loglevel=INFO;;
flower) celery --broker ${CELERY_BROKER_URL} --result-backend ${CELERY_BACKEND_URL} -A worker.celery flower;;
fastapi) uvicorn api.main:app --host 0.0.0.0 --port 80;;
esac
测试应用
首先从基本文件夹构建所有内容:
docker-compose build
然后运行应用程序!
docker-compose up
我真正喜欢 FastAPI 的地方在于它带有 Swagger,开发人员不需要任何配置或操作。前往 localhost:8000/docs
首先“试用” POST 端点:
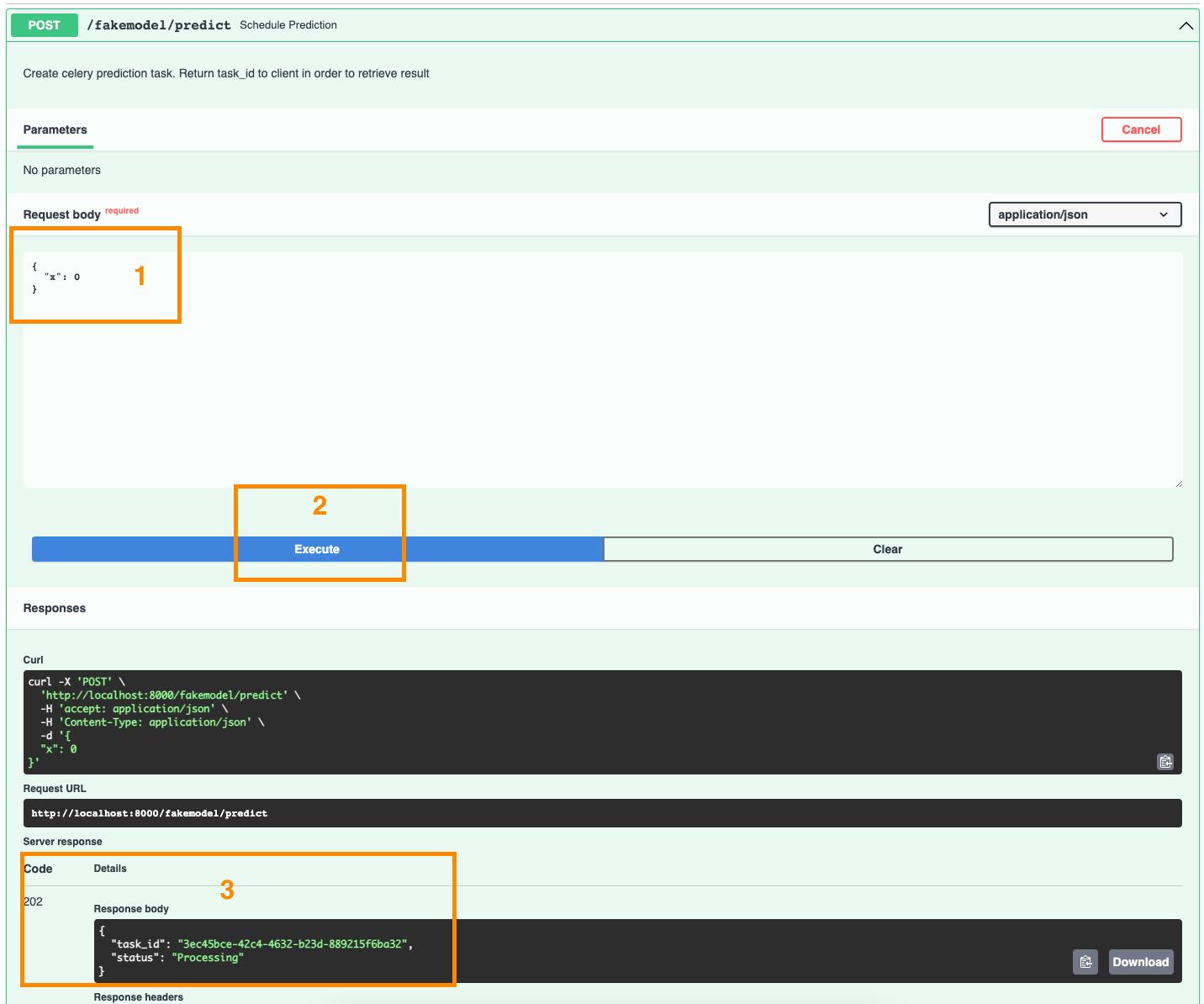
API回复我们,我们要求的预测现在正在处理中,它的ID是_3ec45bce-42c4-4632-b23d-889215f6ba32_
现在我们可以向另一个端点询问 3ec45bce-42c4-4632-b23d-889215f6ba32 的状态:
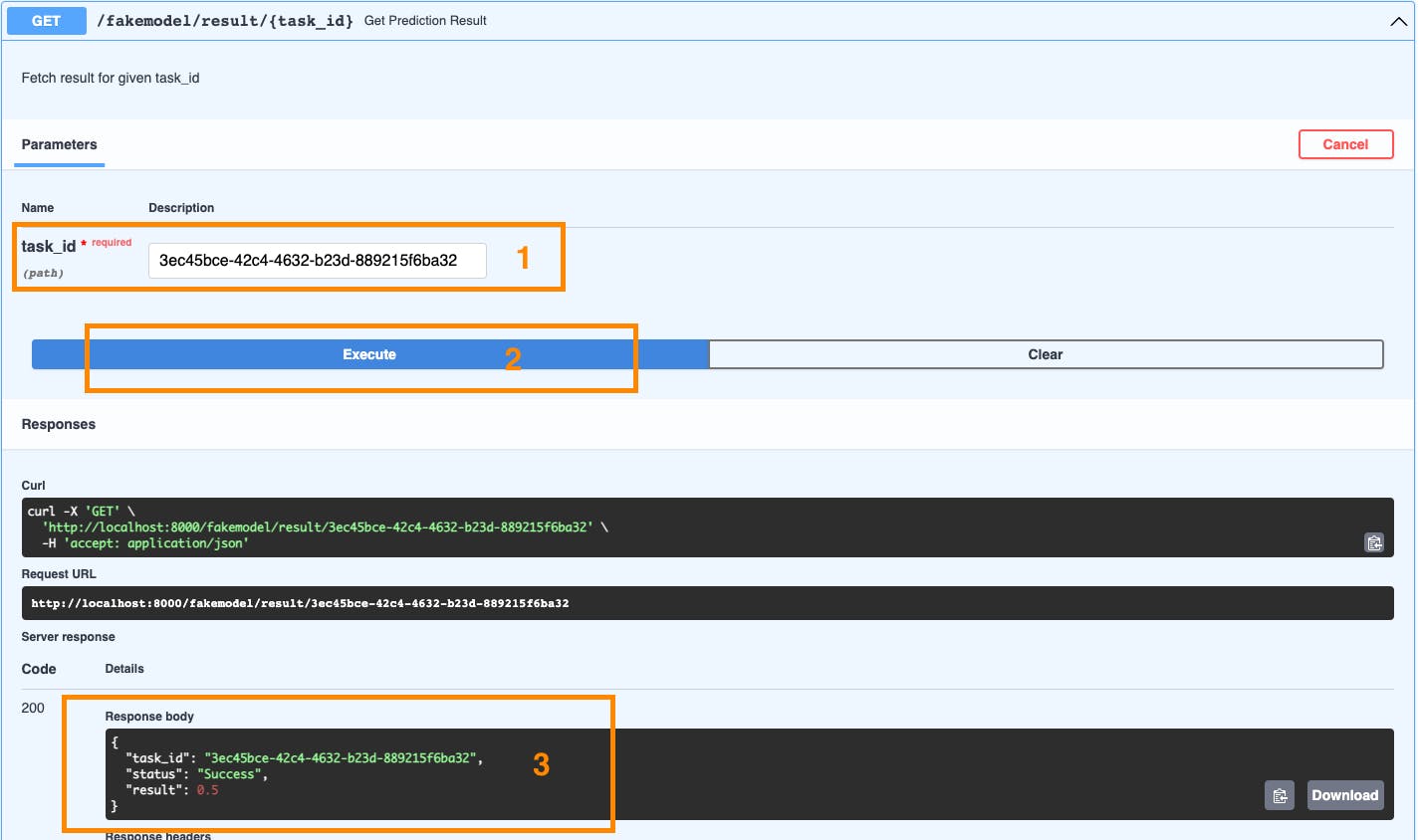
响应包含我们请求的任务 ID、状态(成功)和模型预测的最终结果。
下一步
在接下来的几周里,我将探索最佳实践,以优化和安全地使用
-
Nginx
-
自动化单元和集成测试
-
骨架的应用与真实世界的例子(一个实际的ML模型)
然后要关闭 DevOps 圈,进一步的步骤可能还包括:
-
CI/CD 流水线
-
云集成
-
Kubernetes
总结
这是构成项目框架第一版的元素的“快速”概述,该框架提供了一个工作异步微服务结构,允许使用它的开发人员通过仅修改来服务任何 Python 逻辑:
-
逻辑文件夹(我们的黑盒F)
-
FastAPI 端点和模型(我们的 X 和 Y)
谢谢你读到这里!我很想在下面的评论部分听到你的想法、建议和问题。
干杯
丹尼斯

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 1
1 0
0- 0



 已为社区贡献35528条内容
已为社区贡献35528条内容

所有评论(0)