Java 中的 Kafka 生产者和消费者:初学者指南
简介
本教程介绍了 Apache Kafka、Kafka Producer 和 Kafka Consumer,按照本文的思路,我们将构建两个简单的应用程序;一个作为生产者,在 Kafka 主题上生成消息,另一个作为消费者,使用来自同一主题的消息。
首先,让我们定义一些关键术语。
什么是阿帕奇卡夫卡?
Kafka 是一个分布式事件流平台,可跨多个渠道(移动、Web、IoT 设备等)提供对数据的高可用性和低端到端延迟访问。 Kafka 使用发布者-订阅者模式,其中消息的发送者,通常称为生产者,向主题发送消息,所有订阅者立即收到消息。在 Kafka 中,我们可以有多个生产者生产消息和多个消费者消费消息。
在当今世界,数百万台设备进行实时通信。例如,在物联网世界中,信号在不同设备之间实时发送。 Kafka 提供了一个平台,可以将信号以消息的形式从一个设备(生产者)发送到另一个设备(消费者)在其中消费消息的主题,这会以非常低的延迟发生。 Kafka有几种实现,下面列出了一些 -
-
实时处理支付和金融交易,例如在证券交易所、银行和保险中。
-
实时跟踪和监控汽车、卡车、车队和货运,例如物流和汽车行业。
-
持续捕获和分析来自物联网设备或其他设备的传感器数据,例如工厂和风电场。
-
收集并立即响应客户交互和订单,例如零售、酒店和旅游行业以及移动应用程序。
-
对住院病人进行监护,预测病情变化,确保在紧急情况下及时救治。
-
连接、存储和提供公司不同部门产生的数据。作为数据平台、事件驱动架构和微服务的基础。
资料来源:Apache Kafka 文档。
术语
-
Producer 是能够产生消息的任何设备或客户端应用程序 - 将其视为发射器;它也可能是物联网设备。
-
Consumer 是消费消息的设备或客户端应用程序。
-
Kafka中的一条消息叫做Record,记录是不可变的——记录一旦创建或推送就不能改变。
-
生产者产生的消息存储在一个Topic中。主题类似于数据库中的表。
-
主题被分区和复制跨代理,即消息存储在不同代理的多个位置。
-
分区中的每条消息都会获得一个名为 Offset 的增量 id。
-
每条消息都有一个跨分区的唯一标识符,即一条消息可以通过分区 ID 和偏移量 id 来标识,例如partition-0, offset-1 表示分区号为 0 且偏移量为 1 的消息。
-
消息在每个分区中按照偏移的顺序读取,即消费者A按照偏移id的自然顺序从partition-0读取。值得注意的是,消息是由消费者并行读取的。
-
每个消费者都属于一个特定的消费者组,并且只从分区中读取消息。
-
Broker 类似于包含多个主题的服务器。每个代理都用一个 id 标识。
-
zookeeper 编排和管理 Kafka 集群中的不同代理。
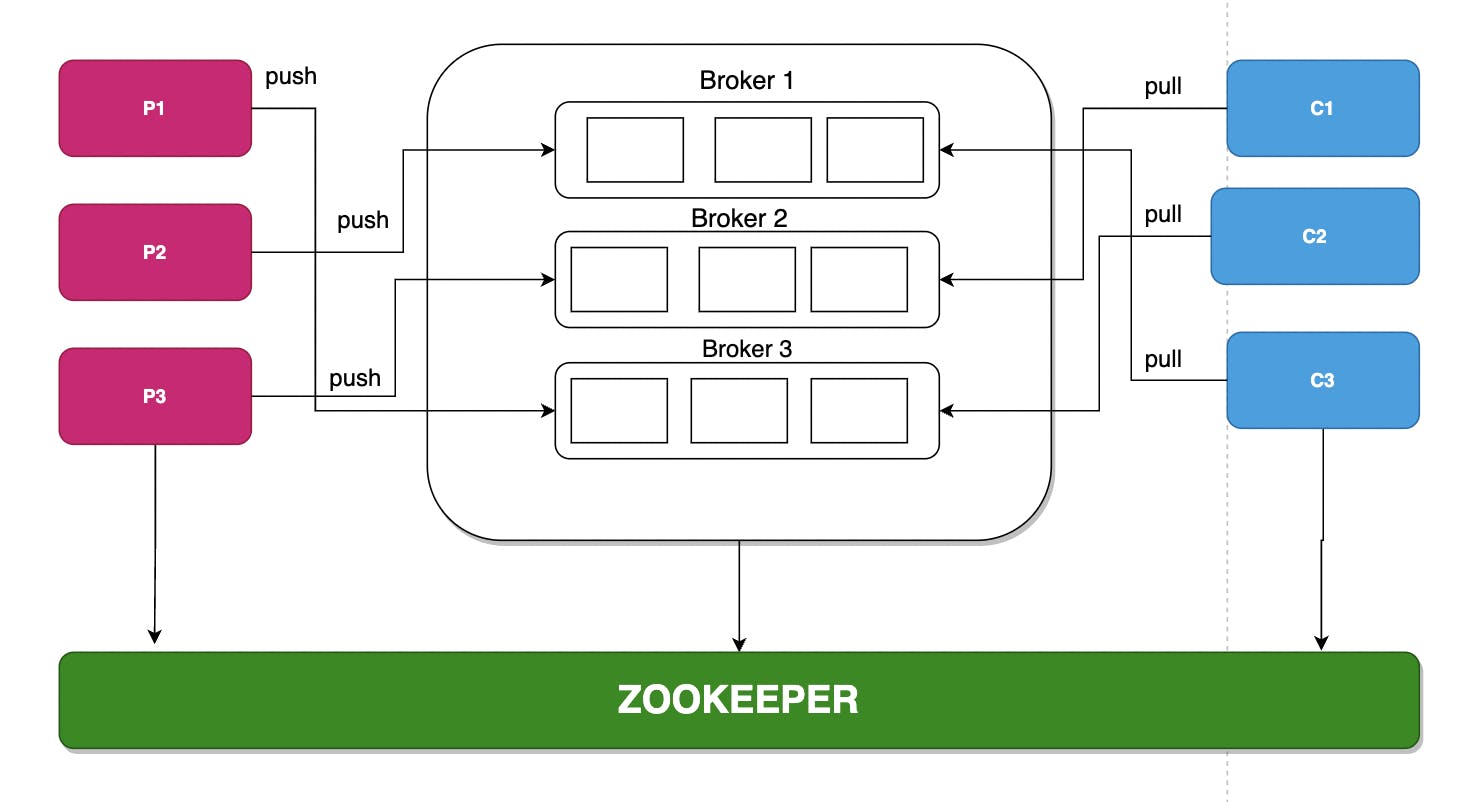 kafka 集群架构
kafka 集群架构
先决条件
在本教程中,您需要对以下内容有一个大致的了解
-
弹簧靴
-
码头工人
搭建Kafka环境
我们将使用 Docker 和 docker-compose 来设置我们的 Kafka 环境并构建应用程序。您可以按照官方文档了解如何在此处安装 docker并在此处查看 docker-compose。您还可以在此处克隆本教程中使用的 docker-compose 文件。克隆 repo 后,让我们看看 docker-compose .yaml 文件里面有什么。
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:6.2.1
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-server:6.2.1
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "9092:9092"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker:29092
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
该文件使用一些默认配置为 zookeeper 和代理服务器定义图像。我不会深入探讨 docker,只提及文件的一些关键组件。
zookeeper:
image: confluentinc/cp-zookeeper:6.2.1
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
-
image:这定义了 docker 要拉取的图像。
-
container_name:定义容器的名称。
-
ports:这定义了容器端口和主机端口。容器端口是容器运行的端口,而主机端口是主机上要绑定的端口。
broker:
image: confluentinc/cp-server:6.2.1
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "9092:9092"
- "9101:9101"
-
image:这定义了 docker 要拉取的镜像。
-
container_name:定义容器的名称。
-
ports:这定义了容器端口和主机端口。容器端口是容器运行的端口,而主机端口是主机上要绑定的端口。
-
depends_on:这告诉 docker broker 依赖于 zookeeper,即 zookeeper 必须在 broker 之前运行。
创建生产者项目
接下来,我们将创建一个简单的生产者项目。让我们继续使用弹簧初始化程序来创建我们的项目。
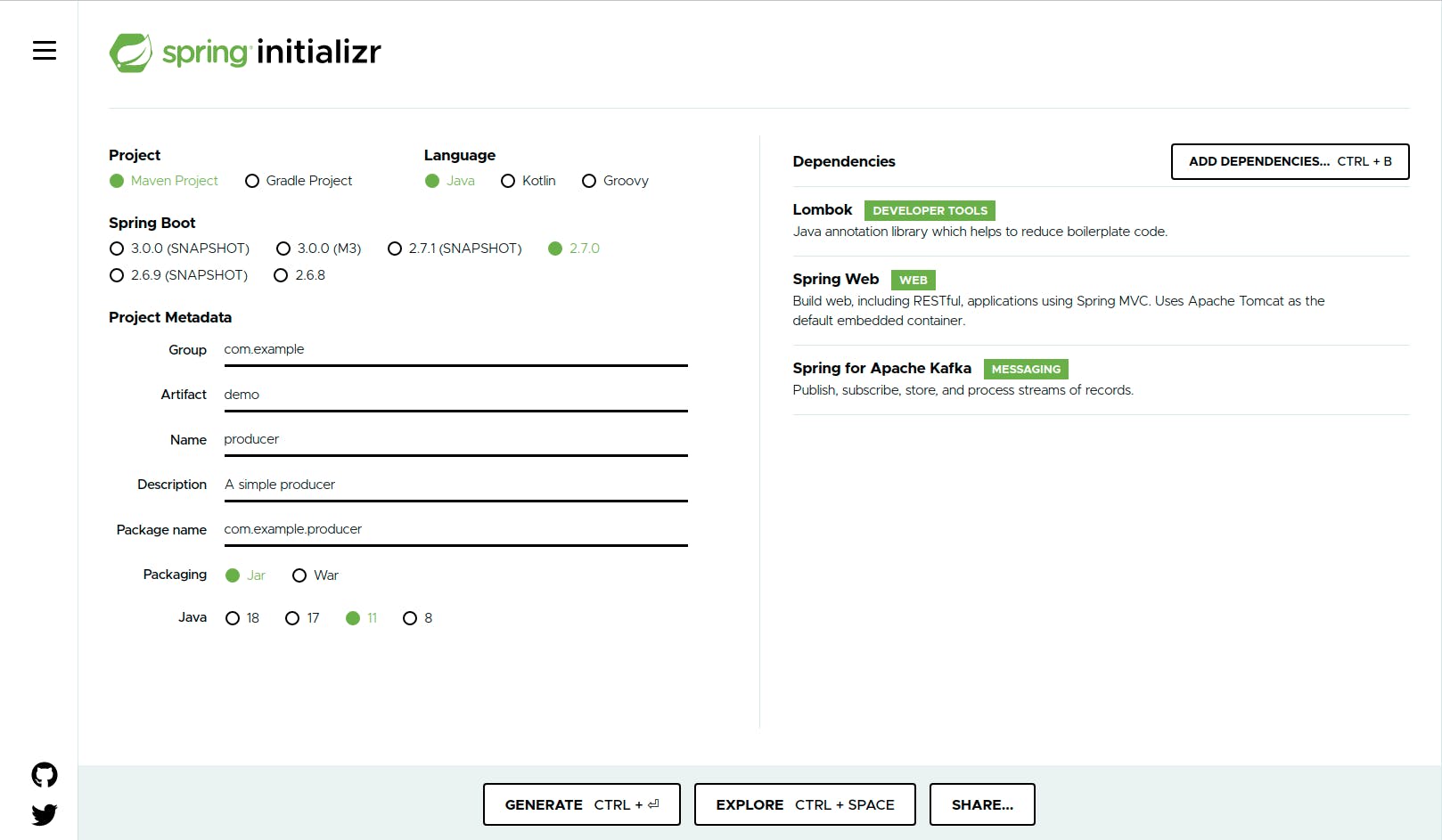
从元数据部分。设置以下内容;
-
Group:出于本教程的目的,将其保留为默认的“com.example”。
-
Artifact:demo 名称:producer,这应该是项目名称,但对于教程,我们将其保留为 producer。
-
包名:将为我们自动生成。包装:将其保留为 Jar
-
Java:选择 11,注意:你应该在你的机器上安装了这个。
在右侧窗格中添加 Lombok、Spring web 和 Spring for Apache Kafka。之后,单击生成您的项目,解压缩并在您喜欢的 IDE 上打开。如果你打开 pom.xml 文件,你应该有以下依赖。一个
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
创建消息对象
现在,让我们创建我们将推送到该主题的模型。我们将创建一个 java 类来表示我们的消息,这将在传输时转换为 JSON。我们将使用 Lombok 来减少我们课程中的样板代码。
src/main/java/com/example/producer/model/Message.java
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Message {
private String user;
private String msg;
}
Kafka生产者配置
接下来,我们创建配置文件来定义 Kafka 生产者的配置。
src/main/java/com/example/producer/config/KafkaConfig.java
@Configuration
public class KafkaConfig {
@Value("${kafka.broker}")
private String brokerServer;
// create a topic called chat
@Bean
public NewTopic chatTopic(){
return TopicBuilder.name("chat")
.build();
}
@Bean
public ProducerFactory<String, Message> chatProducerFactory() {
Map<String, Object> configs = new HashMap<>();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG , brokerServer);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return new DefaultKafkaProducerFactory<>(configs);
}
@Bean
public KafkaTemplate<String, Message> chatKafkaTemplate(){
return new KafkaTemplate<>(chatProducerFactory());
}
}
让我们看看 Kafkaconfig.java 中有什么。
我们使用@Configuration注释该类以在 spring 中创建一个构造型配置。
@Bean
public NewTopic chatTopic(){
return TopicBuilder.name("chat")
.build();
}
我们使用 TopicBuilder 构建器类命名和创建我们的主题。
@Bean
public ProducerFactory<String, Message> chatProducerFactory() {
Map<String, Object> configs = new HashMap<>();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG , brokerServer);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return new DefaultKafkaProducerFactory<>(configs);
}
这里需要注意的最重要的配置是代理服务器,它将在我们的 application.yaml 文件中定义为kafka.broker: localhost:9092。这指定了我们要连接的代理服务器。接下来,我们指定KEY_SERIALIZER_CLASS_CONFIG,它定义了密钥的序列化程序。我们使用 StringSerializer.class 因为我们的键是一个字符串。根据用例,您可以指定一些其他类,例如整数键的 IntegerSerializer 和VALUE_SERIALIZER_CLASS_CONFIG定义值的序列化程序,我们使用 JsonSerializer.class 因为我们将传递 JSON 作为我们的值,其他类型也可能基于用例,例如用于字符串值的 StringSerializer。然后我们使用配置来构造 DefaultKafkaProducerFactory。
src/main/java/com/example/producer/api/ChatController.java
@RestController
@RequestMapping("/api/v1/chats")
public class ChatController {
@Autowired
private KafkaTemplate<String, Message> kafkaTemplate;
@PostMapping("send")
public ResponseEntity<String> sendMessage(@RequestBody Message message){
kafkaTemplate.send("chat", UUID.randomUUID().toString(), message);
return ResponseEntity.ok("Message sent");
}
}
演示:推送消息到我们的主题
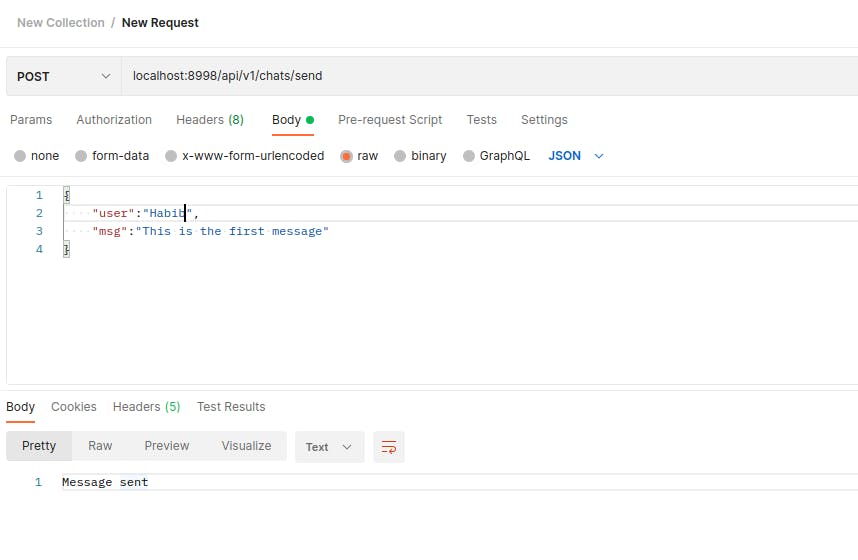
接下来,我们创建我们的控制器。在这里,我们将 KafkaTemplate 自动装配到类中。KafkaTemplate<String, Message>转换为KafkaTemplate <Key, Value>,Key 表示您在序列化程序中定义的类,Value 表示您打算转换为 JSON 的类。我们将从 kafkaTemplate 调用 send() 方法来发送消息。send()方法有不同的实现。kafkaTemplate.send("chat", UUID.randomUUID().toString(), message);这里,第一个参数是topicName,后跟一个key(唯一标识消息),然后是我们发送的消息对象。KafkaTemplate
我们将运行应用程序并将 URL 粘贴到邮递员上,如下面的屏幕截图所示。
设置消费者
现在,我们完成了我们的制作人。让我们开始创建我们的消费者,就像我们为生产者所做的那样。我们回到spring initializer,我们只需将项目名称更改为 consumer 并选择以前的配置。
创建消费者 JSON 对象
在其他消费来自主题的消息时,我们将创建在生产者服务中创建的相同消息类。
src/main/java/com/example/consumer/model/Message.java
@AllArgsConstructor
@NoArgsConstructor
public class Message {
private String user;
private String msg;
}
Kafka Consumer的配置
接下来,我们转到消费者配置
src/main/java/com/example/consumer/config/KafkaConfig.java
@Configuration
public class KafkaConfig {
@Value("${kafka.broker}")
private String brokerServer;
@Bean
public Map<String, Object> chatProducerFactory() {
Map<String, Object> configs = new HashMap<>();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerServer);
configs.put( ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
return configs;
}
@Bean
public ConsumerFactory<String, Message> chatKafkaTemplate(){
JsonDeserializer<Message> deserializer = new JsonDeserializer<>(Message.class);
deserializer.setRemoveTypeHeaders(false);
deserializer.addTrustedPackages("*");
deserializer.setUseTypeMapperForKey(true);
return new DefaultKafkaConsumerFactory<>(chatProducerFactory(), new StringDeserializer(), deserializer);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, Message> chatFactory() {
ConcurrentKafkaListenerContainerFactory<String, Message> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(chatKafkaTemplate());
return factory;
}
}
正如我们在生产者的配置中看到的,我们需要指定要连接的代理服务器。需要注意的是 JsonDeserializer。
JsonDeserializer<Message> deserializer = new JsonDeserializer<>(Message.class);
deserializer.setRemoveTypeHeaders(false);
deserializer.addTrustedPackages("*");
deserializer.setUseTypeMapperForKey(true);
与我们在生产者中声明为简单的 JsonSerializer 不同,我们将声明一个 Deserializer 和一些其他配置,我现在将解释这些配置。由于生产者和消费者在将 JSON 对象反序列化为 java 对象时存在于不同的应用程序中,因此 Kafka 会抛出错误“ErrorHandlingDeserializer”,这是因为反序列化器类不信任消费者中的 java 对象。另外,为了解决这个问题,我们告诉序列化程序信任所有的包(“*”),如果我们想指定一个特定的包或对象,我们只需指定包名,如下所示:
deserializer.addTrustedPackages("com.example.consumer.model.Message");
创建消费者服务
然后,我们为类创建服务以使用消息。
src/main/java/com/example/consumer/service/ConsumerService.java
@Service
public class ConsumerService {
private final Logger logger = LoggerFactory.getLogger(getClass());
private final List<Message> messages = new ArrayList<>();
@KafkaListener(topics = "chat", groupId = "chat-consumer", containerFactory = "chatFactory")
private void chatConsumer(Message message){
messages.add(message);
logger.info("Received : {}", messages);
}
}
现在,我们可以再次访问我们的生产者端点,以查看消费者从主题中获取消息。
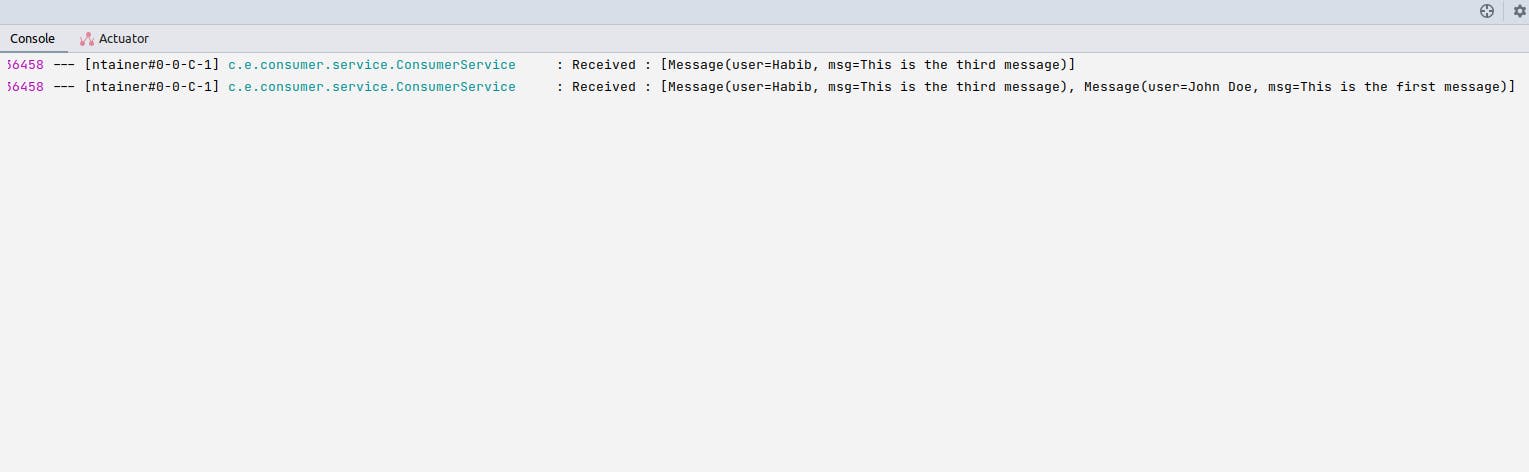
消费者如何知道已读的消息?
如前所述,消费者组中的每个消费者都只从分区中读取;每条消息都由偏移 id 标识。每当来自消费者组的消费者开始消费来自特定主题的消息时,偏移量 id 都会由 Kafka 在内部提交给另一个主题**__consumer_offsets**,以记录消费者正在从哪里读取。在失败的情况下,消费者可以从中断的地方继续消费消息。
结论
在本教程中,我们了解了 Kafka、一些术语及其用途。我们还创建了一个生产者,对其进行配置,并向一个主题发送消息,并创建一个消费者,对其进行配置,并实时接收/消费从生产者推送到主题的消息。稍后,我们讨论了消费者在从失败中恢复时如何记住它停止的地方。
您可以在此存储库中找到本教程中使用的代码以进行后续操作。

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 0
0 0
0- 0



 已为社区贡献35528条内容
已为社区贡献35528条内容

所有评论(0)