深度学习在交通状态预测中的应用实践
现代深度学习框架如TensorFlow、Keras和PyTorch为研究者和开发人员提供了易用的编程接口,它们抽象了复杂的数值计算和底层操作,使得构建和训练神经网络模型变得更加简单。这些框架不仅支持自动微分,还提供了丰富的预定义层、优化器、激活函数等组件,极大地降低了深度学习应用的门槛。TensorFlow是谷歌开源的一个用于数值计算的库,它采用数据流图(Dataflow Graphs)的方式进行

简介:深度学习通过模拟人脑神经网络的方式,使用大量数据训练模型以完成高精度预测任务。本项目实例重点展示了如何应用深度学习技术预测交通状态,通过利用Python库搭建多层神经网络模型,并特别适用于处理时间序列数据的LSTM和GRU架构。开发者收集交通流量数据,进行数据预处理,模型训练,并使用均方误差、平均绝对误差及决定系数等指标进行评估。该实例不仅提供了一个有效的深度学习模型构建和训练过程,而且还包括了模型的部署和实时预测,是深度学习在实际问题解决中的一个典型应用案例。 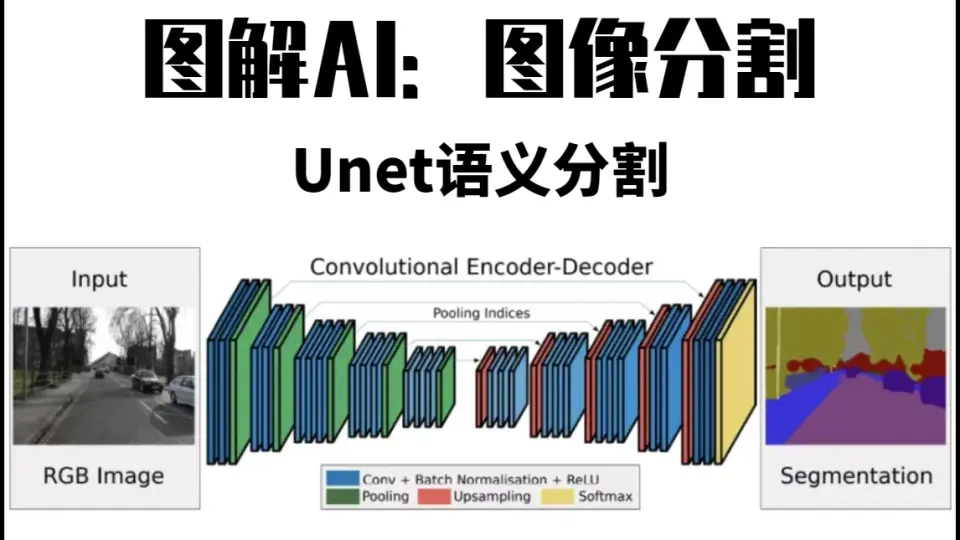
1. 深度学习基础和框架
深度学习作为人工智能领域的一个重要分支,它模仿人脑工作的方式来解决问题,已经广泛应用于图像识别、语音识别、自然语言处理等众多领域。深度学习需要大量的数据和高性能的计算能力。随着硬件的发展和算法的创新,深度学习正逐渐成为推动技术进步的重要力量。
在深度学习领域,众多框架和库的出现使得研究者和工程师能够更加快速和高效地开发复杂模型。本章将介绍深度学习的基础概念、原理以及目前广泛使用的框架,为读者提供一个整体的入门知识体系。
1.1 深度学习的原理
深度学习的基础是神经网络,它是由大量的、相互连接的节点组成,这些节点通常被划分为若干个层次。每个节点都可以看作是一个简单的计算单元,它可以接收输入信号、经过处理后传递到下一个层次。深度学习中的“深度”指的是网络结构中存在多个层次,通过这种方式网络可以学习到数据的层次化特征。
深度神经网络中的每层通常由若干个神经元组成,神经元之间通过权重连接。网络的学习过程就是通过调整这些连接权重来实现的,这一过程是通过反向传播算法配合梯度下降法来完成的。
1.2 深度学习框架介绍
现代深度学习框架如TensorFlow、Keras和PyTorch为研究者和开发人员提供了易用的编程接口,它们抽象了复杂的数值计算和底层操作,使得构建和训练神经网络模型变得更加简单。这些框架不仅支持自动微分,还提供了丰富的预定义层、优化器、激活函数等组件,极大地降低了深度学习应用的门槛。
TensorFlow是谷歌开源的一个用于数值计算的库,它采用数据流图(Dataflow Graphs)的方式进行计算,可以用于构建复杂的神经网络模型。Keras则是一个高层神经网络API,它能够运行在TensorFlow、CNTK或Theano之上,设计的初衷是实现快速的实验。PyTorch则是Facebook推出的一个开源机器学习库,它引入了动态计算图(Dynamic Computational Graphs)的概念,使得模型构建更加灵活。
以上章节内容为本文的开头部分,它为读者提供了一个关于深度学习的宏观认识,并介绍了主要的深度学习框架。后续章节将深入探讨这些框架的具体使用方法和最佳实践。
2. Python深度学习库应用
2.1 TensorFlow的原理与应用
2.1.1 TensorFlow的安装与环境配置
在开始探讨TensorFlow的应用之前,首先需要确保我们的开发环境已经准备就绪。TensorFlow是谷歌开发的一个开源深度学习框架,广泛用于各种机器学习和深度学习项目中。安装TensorFlow前需要确认Python版本,它支持Python 3.5及以上版本。TensorFlow对依赖库有一定的版本要求,通常建议使用虚拟环境来隔离不同项目的依赖,这样可以避免不同项目间的依赖冲突。
使用pip安装TensorFlow非常简单,通过以下命令进行安装:
pip install tensorflow
如果你需要GPU加速版本的TensorFlow,可以使用:
pip install tensorflow-gpu
安装完成后,我们可以通过一个简单的Hello World程序来验证安装是否成功:
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
print(sess.run(hello))
如果顺利输出了”Hello, TensorFlow!”,则说明安装配置成功。
2.1.2 TensorFlow计算图的构建与执行
TensorFlow中的核心概念之一是计算图(computational graph),它是由节点(node)和边(edge)组成的网络。在TensorFlow中,所有的计算都由图表示,而会话(Session)用于计算图的执行。图定义了计算过程,而会话则负责运行这些计算。
构建计算图的步骤如下:
- 定义操作(operation)和张量(tensor),作为计算图的节点。
- 将这些操作和张量通过边连接起来,形成数据流。
- 通过创建会话(Session)来运行计算图。
下面是一个简单的例子,通过计算图完成加法操作:
import tensorflow as tf
# 定义两个常量节点
a = tf.constant(2)
b = tf.constant(3)
# 定义一个加法操作节点
adder_node = tf.add(a, b)
# 创建一个会话来执行图中的计算
with tf.Session() as sess:
# 执行加法操作节点,并获取结果
print(sess.run(adder_node)) # 输出5
在这个例子中,我们首先导入TensorFlow模块,然后定义了两个常量节点 a 和 b ,并创建了一个加法操作节点 adder_node 。通过 with tf.Session() as sess 语句创建了一个会话,并在该会话中运行了 adder_node 计算,最终输出了计算结果5。
在实际应用中,计算图可以非常复杂,包含大量的节点和边,利用TensorFlow的强大功能可以构建和训练复杂的神经网络模型。构建复杂的深度学习模型时,TensorFlow提供了各种高级API,如tf.layers、tf.contrib.layers等,方便用户快速构建模型。
理解并掌握TensorFlow的计算图构建和执行机制是使用TensorFlow进行深度学习项目开发的基础,对于后续构建和优化深度学习模型至关重要。
3. 卷积神经网络(CNN)
3.1 CNN的理论基础
3.1.1 卷积层、池化层的工作原理
卷积神经网络(CNN)是一类深度学习模型,在图像识别和分类任务中表现尤为突出。它在结构上模拟了生物视觉系统的信息处理方式,通过权值共享和局部连接的原理,大大减少了模型的参数数量。其中,卷积层和池化层是构成CNN的核心组件。
卷积层的主要作用是提取图像的特征。该层通过一组卷积核(滤波器)在输入图像上滑动进行卷积操作,提取局部特征。每个卷积核都能响应于输入图像的某种特定模式,例如边缘或角点。卷积操作后通常会伴随激活函数,如ReLU,增加模型的非线性表达能力。
池化层(又称为下采样层)用于降低特征图的空间尺寸,减少计算量,同时保留主要特征。常见的池化操作包括最大池化(取区域内最大值)和平均池化(取区域内平均值)。池化层使得CNN在面对尺寸变化时具有一定的不变性,这对图像识别非常重要。
3.1.2 典型的CNN架构解析
典型的CNN架构一般包括交替的卷积层、池化层和全连接层。让我们详细解析一种经典的CNN架构——LeNet-5。LeNet-5由Yann LeCun等人提出,是早期成功应用于手写数字识别的CNN模型。
LeNet-5网络结构大致分为两部分:特征提取部分和分类部分。特征提取部分由多个卷积层和池化层构成。具体来说,它包含两个卷积层,每个卷积层后面跟着一个池化层。这种结构设计能够有效提取图像的特征,并逐步增加感受野,捕获更丰富的上下文信息。
分类部分则通常由一个或多个全连接层构成,它们将提取到的特征映射到分类标签上。LeNet-5中的全连接层有三个,最后一个全连接层的输出与分类任务的类别数相匹配,通常是10个输出对应10个手写数字。
这种典型的CNN结构具有良好的通用性,在之后的许多网络架构设计中都能够看到它的影子。例如,AlexNet、VGGNet、GoogLeNet等都是在LeNet的基础上加以改进和增强,以适应更复杂的图像识别和分类任务。
3.2 CNN实践技巧
3.2.1 图像分类任务的实现
在实现一个图像分类任务时,使用CNN可以极大地提升模型的准确率。下面,我们将详细探讨如何利用CNN实现图像分类任务。
首先,我们需要准备图像数据集。图像数据集通常被分为训练集和测试集。训练集用于训练模型,测试集用于评估模型性能。图像需要预处理成统一的尺寸,并归一化到[0,1]区间。
接下来是模型的构建。以经典的VGG16模型为例,我们可以通过深度学习框架如Keras,轻松构建一个VGG16网络。VGG16由16层网络组成,其中包括13个卷积层、3个全连接层、以及5个池化层。权重初始化为预训练的权重,这可以加快训练速度,提高模型性能。
模型训练过程中,需要选择合适的损失函数和优化器。在图像分类任务中,通常使用交叉熵损失函数和Adam优化器。在训练过程中,我们还需要关注验证集上的性能,通过准确率、召回率等指标来评估模型的泛化能力。
训练完成后,使用测试集对模型进行最终评估。通过分类指标,如混淆矩阵、精确率、召回率和F1分数,来衡量模型的性能。在某些情况下,我们可能还需要进行模型调优,比如调整超参数、添加数据增强等,以进一步提升模型性能。
3.2.2 特征提取与迁移学习应用
在一些应用场景中,我们可能没有足够的标注数据来从头开始训练一个复杂的CNN模型。这时,迁移学习成为了一种非常有用的技术。
迁移学习是指将一个预训练模型迁移到新的任务上。预训练模型是在大规模数据集(如ImageNet)上训练得到的,它们能够提取通用的特征,因此可以作为其他相关任务的起点。
特征提取是迁移学习的一种应用方式。在这个过程中,我们通常会去掉预训练模型的全连接层,保留卷积层。然后将我们的数据输入到模型中,以提取特征。提取到的特征可以用于训练新的分类器,如支持向量机或简单的全连接神经网络。
另一个重要的迁移学习应用是微调(fine-tuning)。微调是指在特征提取的基础上,进一步调整预训练模型的权重。这通常涉及到冻结部分层的权重,只训练最后一部分层,或者在更小的学习率下训练所有层。通过微调,模型能够更好地适应新任务,提高性能。
迁移学习的关键在于选择与新任务相关的预训练模型。例如,如果新任务是医学图像处理,那么在医学图像上预训练的模型将是更好的选择。
实现迁移学习时,可以使用多种深度学习框架。以Keras为例,首先加载预训练模型,接着根据需要冻结或微调层,最后将预训练模型作为特征提取器或微调模型来训练和评估。
迁移学习不仅能够缩短训练时间,提高新任务上的模型性能,还可以在数据不足的情况下取得与大规模数据集训练相媲美的效果。它是一种非常实用的技术,在工业界和研究界都有广泛的应用。
在处理实际问题时,我们需要综合考虑数据集的大小、质量以及任务的复杂性,来决定是否使用迁移学习,以及如何应用迁移学习。通过合适的迁移学习策略,可以有效提升模型在实际问题中的表现。
4. 循环神经网络(RNN)
4.1 RNN的理论基础
4.1.1 循环层的工作机制
循环神经网络(Recurrent Neural Network, RNN)是一种具有短期记忆能力的深度学习模型,它特别适合处理和预测序列数据中的时间序列数据。RNN的核心思想是利用隐藏状态保存之前的信息,并将这些信息传递到下一步的处理中。
在传统的前馈神经网络中,每一层的神经元只与前一层的神经元相连。而对于RNN,当前时刻的输出不仅依赖于当前输入,还依赖于之前的隐藏状态。这种结构允许RNN在不同的时间点共享参数,从而通过展开成一个链式结构处理序列数据。
在RNN中,一个时间步的隐藏状态是通过当前输入和前一时间步的隐藏状态计算得到的。数学上可以表示为:
[ h_t = f(W_{hh} h_{t-1} + W_{xh} x_t + b) ]
这里,( h_t ) 是当前时间步的隐藏状态,( h_{t-1} ) 是前一时间步的隐藏状态,( x_t ) 是当前时间步的输入,( f ) 是非线性激活函数(如tanh或ReLU),( W_{hh} ) 和 ( W_{xh} ) 是权重矩阵,( b ) 是偏置项。
RNN的这种循环机制使得它能够在处理时间序列数据时考虑之前的信息。然而,随着序列长度的增加,RNN会遇到梯度消失或梯度爆炸的问题,这是由于长期依赖信息在反向传播时难以稳定传递。
4.1.2 RNN的变体:长短时记忆网络(LSTM)与门控循环单元(GRU)
为了解决传统RNN的长期依赖问题,研究者们提出了几种变体,其中最著名的两种是长短时记忆网络(Long Short-Term Memory, LSTM)和门控循环单元(Gated Recurrent Unit, GRU)。
LSTM的设计引入了一个更复杂的结构,包括遗忘门、输入门和输出门,以及一个内部状态(也称为细胞状态)。这种结构能够更加智能地决定哪些信息应该被保留,哪些应该被遗忘。LSTM的数学表达式较为复杂,但它能够通过门控制信息流动,从而解决梯度问题。
GRU则是一种更为简化的版本,它将LSTM的三个门简化为两个,并且不单独维护一个内部状态。GRU将LSTM中的细胞状态和隐藏状态合并,通过两个门(重置门和更新门)来控制信息的流动。
LSTM和GRU都通过门控制机制解决了传统RNN的长期依赖问题,并且在各种序列处理任务中表现得非常出色。相比于LSTM,GRU在参数数量上更少,训练速度更快,但在某些复杂任务上,LSTM可能会有更好的表现。
LSTM和GRU的设计原理及其性能的对比,为处理序列数据提供了不同的解决方案,具体选择哪一种往往取决于具体的应用场景和实验结果。
5. 长短时记忆网络(LSTM)与门控循环单元(GRU)
5.1 LSTM与GRU的内部结构
5.1.1 LSTM与GRU的设计原理
长短时记忆网络(Long Short-Term Memory, LSTM)与门控循环单元(Gated Recurrent Unit, GRU)是两种特别设计的循环神经网络(Recurrent Neural Networks, RNNs)结构,它们能够学习长期依赖信息。与传统RNNs相比,它们解决了传统RNNs在处理长序列数据时存在的梯度消失和梯度爆炸问题。
LSTM通过引入门控机制来控制信息的流动,其核心是三个门(输入门、遗忘门、输出门)和一个内部状态。这些门控制着信息的存储、更新和输出,使得网络能够保留长期依赖关系。
GRU可以看作是LSTM的一种简化版本,它只有两个门(更新门和重置门),合并了LSTM中的输入门和遗忘门,并且不再维持一个单独的内部状态。GRU的结构更简单,参数更少,因此训练起来往往更快,且需要的数据更少。
5.1.2 LSTM与GRU的性能对比
在性能上,LSTM由于其复杂的结构,可以捕捉更为复杂的长期依赖关系,但是这也导致了其在训练上需要更多的计算资源。相对而言,GRU的计算效率更高,但有时候可能无法捕捉到LSTM那样的细粒度的长期依赖关系。
在不同任务中,LSTM和GRU的表现各有千秋,没有绝对的优劣之分。一般而言,对于具有明显长期依赖的序列数据,LSTM可能会表现更好。而当数据的序列性不是特别强,或者对训练速度有特别要求时,GRU可能是更好的选择。
5.2 LSTM与GRU在复杂任务中的应用
5.2.1 语音识别与生成模型
LSTM和GRU在网络架构中扮演关键角色,尤其在序列数据处理领域,例如语音识别和生成模型。它们能处理时间跨度较长的序列数据,提取有用的信息,并生成连贯的语音信号。
在语音识别系统中,LSTM和GRU用于学习音频信号的时间依赖性,使得系统能够将语音信号映射到文本上。这种学习能力让语音识别系统能够在嘈杂的环境中工作,以及处理不同口音和语速的语音。
生成模型如文本到语音(TTS)合成中,通过LSTM或GRU的循环结构,可以生成自然、流畅的语音。序列生成模型需要捕捉到语言的时序性质,确保生成的语音保持语义连贯性。
5.2.2 机器翻译与文本处理
在机器翻译任务中,LSTM和GRU同样表现出色。它们可以分析源语言的语法结构和句子含义,然后生成语法正确、语义连贯的目标语言句子。
LSTM的长距离依赖捕捉能力使其在复杂的句子结构翻译中更为有效,而GRU的快速训练能力使其在需要大量数据和快速迭代的场景下更受欢迎。
文本处理中的自然语言生成、情感分析等任务也大量应用了这两种网络。它们可以有效地处理文本数据,理解上下文关系,并生成高质量的文本内容。
代码示例:LSTM在文本生成中的应用
为了更好地理解LSTM如何应用于文本生成,我们可以通过以下Python代码示例来说明其工作流程。代码中使用了Keras库来构建一个简单的LSTM网络模型。
from keras.models import Sequential
from keras.layers import LSTM, Dense, Activation
from keras.optimizers import RMSprop
# 假设我们已经有了一些预处理好的文本数据和对应的标签
# 输入数据维度: (样本数, 时间步长, 特征数)
data_dim = 1000
timesteps = 10
num_classes = 100
# 构建模型
model = Sequential()
model.add(LSTM(128, input_shape=(timesteps, data_dim)))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
# 模型摘要
model.summary()
# 训练模型...
# model.fit(input_data, labels, ...)
上述代码展示了如何构建一个基本的LSTM模型。每个LSTM层都可以通过遗忘门来抛弃不重要的信息,通过输入门添加新信息,并通过输出门决定输出什么信息。通过适当的训练,该模型能够学习如何根据输入数据生成连贯的文本序列。
表格:LSTM与GRU参数对比
| 参数 | LSTM | GRU |
|---|---|---|
| 输入门 | 有 | 无 |
| 遗忘门 | 有 | 合并为更新门 |
| 输出门 | 有 | 有 |
| 内部状态 | 有独立状态 | 无,状态与隐藏状态合并 |
| 参数数量 | 更多 | 更少 |
| 性能 | 更强,适合复杂任务 | 更高效,适合简单任务 |
表格展示了LSTM和GRU在网络参数和结构上的主要差异。这些差异使得在实际应用中可以根据任务的需求选择合适的模型。
mermaid流程图:LSTM单元结构
graph LR
A[输入] -->|x_t| B[输入门]
A -->|h_{t-1}| C[遗忘门]
A -->|h_{t-1}| D[输出门]
B --> E[更新候选状态]
C --> E
E --> D
D --> F[输出h_t]
在mermaid流程图中,LSTM单元的结构被清晰地展示出来,包括输入门、遗忘门、候选状态更新和输出门。这样的视觉展现有助于我们理解LSTM是如何通过这些门控结构来处理和传递信息的。
6. 时间序列数据处理
6.1 时间序列数据的特点
时间序列数据是按时间顺序排列的一系列数据点,广泛应用于金融、经济、环境科学和工程学等多个领域。处理这类数据通常需要特别考虑其时间依赖性和季节性等特征。
6.1.1 时间序列数据的预处理方法
在深入分析之前,时间序列数据的预处理是关键步骤。这包括数据清洗、缺失值处理、异常值检测与修正,以及数据的归一化或标准化。预处理步骤能显著影响后续分析的准确性和有效性。
数据清洗和缺失值处理
import pandas as pd
from sklearn.impute import SimpleImputer
# 加载数据集
df = pd.read_csv("timeseries_data.csv")
# 查看是否有缺失值
print(df.isnull().sum())
# 使用均值填充缺失值
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
df_filled = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)
以上代码首先检查数据集中是否存在缺失值,然后使用 SimpleImputer 从 sklearn.impute 来填充缺失值。选择均值填充是常见的处理缺失值的方法,但也可以根据情况选择不同的策略。
异常值检测与修正
异常值通常是数据中的离群点,处理它们的方式可以是删除或修正。异常值的检测可以通过统计方法(如Z分数法)或可视化方法(如箱形图)来完成。
import seaborn as sns
import numpy as np
# 使用箱形图可视化异常值
sns.boxplot(x=df['value'])
plt.show()
# 识别并删除异常值
Q1 = df.quantile(0.25)
Q3 = df.quantile(0.75)
IQR = Q3 - Q1
df_filtered = df[~((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).any(axis=1)]
6.1.2 时间序列的平稳性与非平稳性分析
平稳性是非时间序列分析的一个核心概念。一个平稳时间序列的统计特性如均值、方差和自协方差不随时间改变。这与非平稳序列形成对比,后者的统计特性随时间而变化。
平稳性检验
最常用的检验方法是ADF(Augmented Dickey-Fuller)检验。ADF检验用来确定是否存在单位根,也就是用来判断序列是否是平稳的。
from statsmodels.tsa.stattools import adfuller
# ADF检验
result = adfuller(df['value'].dropna())
# 打印ADF检验的结果
print('ADF Statistic: %f' % result[0])
print('p-value: %f' % result[1])
6.2 时间序列预测技术
时间序列预测是根据历史数据预测未来值的艺术。有多种方法可用于时间序列预测,包括传统的统计模型如ARIMA,以及先进的深度学习方法如LSTM。
6.2.1 ARIMA模型与深度学习方法对比
ARIMA模型(自回归积分滑动平均模型)是一种经典的时间序列预测方法,特别适合非季节性或季节性时间序列的预测。然而,对于具有复杂模式和非线性特征的数据集,ARIMA可能不够灵活,而深度学习模型往往能提供更好的预测性能。
ARIMA模型构建
from statsmodels.tsa.arima.model import ARIMA
# ARIMA模型构建
model = ARIMA(df['value'], order=(1, 1, 1))
model_fit = model.fit()
以上代码展示了如何使用 statsmodels 库构建一个ARIMA模型。 order 参数定义了模型的阶数,其中(1, 1, 1)表示模型包含一个自回归项、一个差分阶数和一个移动平均项。
6.2.2 基于LSTM的时间序列预测模型
LSTM是RNN的一个特殊类型,特别适合于处理和预测时间序列数据中的重要事件之间的间隔和延迟。通过构建LSTM模型,可以捕捉时间序列数据中的长期依赖性。
LSTM模型的构建和训练
from keras.models import Sequential
from keras.layers import LSTM, Dense
# 定义LSTM模型
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(n_steps, n_features)))
model.add(LSTM(units=50))
model.add(Dense(1))
# 编译模型
model.compile(optimizer='adam', loss='mse')
# 拟合模型
model.fit(X_train, y_train, epochs=200, verbose=0)
在这个例子中, n_steps 和 n_features 分别代表了输入序列的时间步长和特征数量。LSTM层的 units 参数定义了在每个时间步内传递的特征数量。该模型使用均方误差(mean squared error, MSE)作为损失函数,优化器采用Adam算法进行训练。
通过对比ARIMA模型和LSTM模型,我们可以看到传统统计方法和深度学习方法在处理时间序列数据时的差异性。选择合适的方法需要对具体问题和数据集有深入的了解。下一章节将介绍如何使用这些模型来构建交通状态预测模型。
7. 交通状态预测模型构建
在现代城市中,交通状况的实时预测对于缓解交通拥堵、提高道路使用效率和减少环境污染具有重要意义。构建一个准确的交通状态预测模型不仅能帮助市政规划者更好地理解交通流动,还能为驾驶者提供实时的交通信息。本章节将探讨如何从原始交通数据出发,构建并优化预测模型。
7.1 交通数据的特征与预处理
7.1.1 交通数据集的获取与分析
在开始构建模型之前,首先需要获得可靠且高质量的交通数据集。这些数据通常包括车辆的GPS信息、交通摄像头视频、传感器数据、历史交通流量记录等。数据集的获取可以通过以下途径:
- 公开数据集 :利用来自政府、研究机构或行业合作伙伴公开的交通数据集。
- 商业API :购买商业交通数据服务,例如通过Google Maps API或其他第三方服务获取交通流量数据。
- 自行收集 :如果公开数据无法满足特定需求,可以自行部署传感器或使用车辆内置GPS系统收集数据。
7.1.2 数据清洗与特征工程
数据预处理是模型构建的关键步骤,包括以下部分:
- 数据清洗 :处理缺失值、异常值和重复数据。例如,可以剔除GPS记录中的明显错误或不可能的移动轨迹。
- 特征提取 :从原始数据中提取有助于模型理解的特征。这可能包括时间特征(如一天中的时段、工作日或周末)、空间特征(如路口的位置、路段的长度)以及交通特征(如流量、速度、占有率等)。
- 数据标准化 :将不同尺度和量纲的特征转换到统一的标准上,比如使用Z-score标准化。
- 时间序列分解 :将时间序列数据分解为趋势、季节性和残差等成分,帮助模型捕捉周期性特征。
7.2 模型构建与调优
7.2.1 构建基于CNN的交通流量预测模型
卷积神经网络(CNN)在图像处理领域表现出色,也可以用于从交通图像中提取特征。构建基于CNN的交通流量预测模型,需要以下步骤:
- 数据准备 :将交通摄像头拍摄的视频帧图像输入到CNN模型中。
- 网络设计 :设计一个多层的CNN网络,包括卷积层、激活层(如ReLU)、池化层和全连接层。
- 模型训练 :使用带有标签的交通流量数据训练CNN模型。损失函数通常使用均方误差(MSE),优化算法可以采用Adam或SGD。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# 假设输入的交通图像大小为 (64, 64, 3)
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Flatten(),
Dense(64, activation='relu'),
Dense(1)
])
model.compile(optimizer='adam', loss='mse')
7.2.2 使用LSTM解决交通拥堵预测问题
长短期记忆网络(LSTM)对于处理时间序列数据具有天然的优势。要使用LSTM预测交通拥堵,可以采取以下步骤:
- 时间序列数据准备 :将交通流量数据按照时间序列组织,输入到LSTM模型中。
- 模型构建 :设计一个含有LSTM层的循环神经网络,可以包括多个LSTM层以捕捉更复杂的时序特征。
- 模型调优 :使用历史交通流量数据训练模型,通过调整LSTM的层数、神经元数量和学习率等参数来提高预测准确率。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# 假设输入的时间序列长度为 100,特征数量为 1
model = Sequential([
LSTM(50, return_sequences=True, input_shape=(100, 1)),
LSTM(50),
Dense(1)
])
model.compile(optimizer='adam', loss='mse')
通过对数据的特征提取、预处理以及精心设计的深度学习模型,可以构建出有效的交通状态预测系统。然而,模型的最终性能还需要通过实际数据进行验证和调优。下一章节将讨论如何训练模型以及如何评估模型的有效性。
简介:深度学习通过模拟人脑神经网络的方式,使用大量数据训练模型以完成高精度预测任务。本项目实例重点展示了如何应用深度学习技术预测交通状态,通过利用Python库搭建多层神经网络模型,并特别适用于处理时间序列数据的LSTM和GRU架构。开发者收集交通流量数据,进行数据预处理,模型训练,并使用均方误差、平均绝对误差及决定系数等指标进行评估。该实例不仅提供了一个有效的深度学习模型构建和训练过程,而且还包括了模型的部署和实时预测,是深度学习在实际问题解决中的一个典型应用案例。

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)