深入解析股票行情软件技术要点
股票行情软件是一种金融信息工具,它能够实时收集并显示股票市场的价格动态和相关信息。这些软件不仅帮助投资者掌握市场的最新动态,还能提供历史数据分析,辅助决策过程。它们通常包含了实时报价、历史数据、技术分析工具和新闻资讯等多种功能。

简介:股票行情软件为个人投资者提供实时或历史数据的展示和分析,尽管本文介绍的软件不提供源代码,但文章会讨论此类软件的核心功能与技术。关键功能包括数据获取与处理、高效数据显示、搜索与筛选技术、实时数据更新机制、编程语言与GUI库的使用,以及数据安全和隐私保护。了解这些技术要点有助于理解股票行情软件的设计和开发。 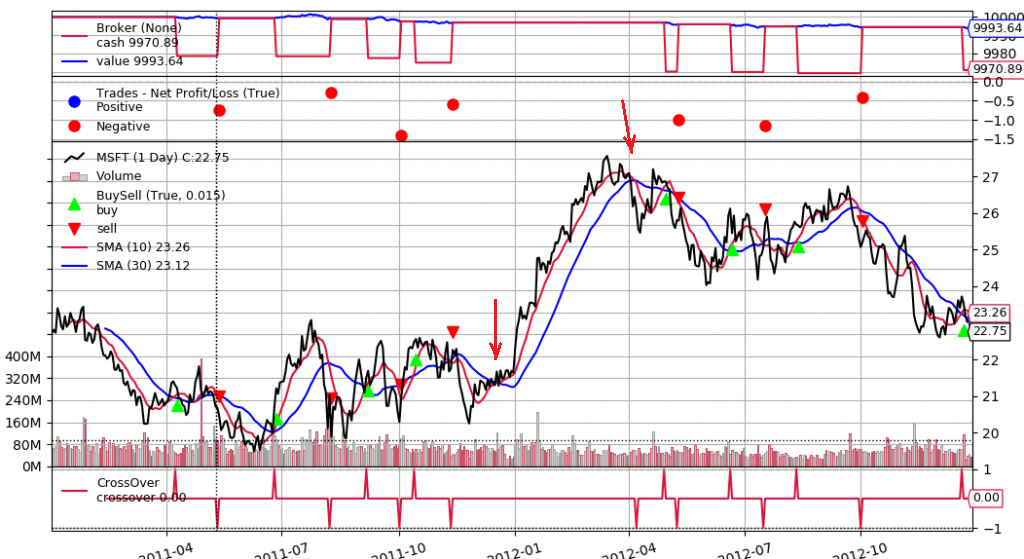
1. 股票行情软件概述
1.1 股票行情软件的定义和作用
股票行情软件是一种金融信息工具,它能够实时收集并显示股票市场的价格动态和相关信息。这些软件不仅帮助投资者掌握市场的最新动态,还能提供历史数据分析,辅助决策过程。它们通常包含了实时报价、历史数据、技术分析工具和新闻资讯等多种功能。
1.2 股票行情软件的主要功能
股票行情软件的主要功能包括:
- 实时数据展示:包括股票价格、交易量、涨跌幅等实时信息。
- 历史数据分析:投资者可以查看股票的历史走势,进行技术分析。
- 技术指标:提供多种技术分析指标,如均线、MACD、RSI等,帮助投资者分析趋势。
- 信息公告:展示上市公司公告、新闻和行业动态。
- 个性化定制:用户可以根据个人需求自定义看盘界面和指标。
1.3 股票行情软件的发展趋势
随着技术的发展,股票行情软件也在不断进步。云技术的普及让数据存储和计算能力不再局限于本地,使得软件的可扩展性和稳定性得到大幅提升。人工智能的应用让预测市场走势和自动化交易成为可能。而随着用户对隐私和安全需求的提升,数据加密和隐私保护措施也日益受到重视。
在下一章中,我们将深入探讨股票行情软件背后的数据获取与处理技术。
2. 数据获取与处理技术
数据是构建股票行情软件的核心,从哪里获取数据、获取何种类型的数据、如何处理和存储这些数据,对于整个系统的性能和用户体验至关重要。本章节将深入探讨数据获取和处理技术,包括数据源的接入与选择、数据处理技术的应用,以及数据格式的转换等关键内容。
2.1 数据源的接入与选择
数据源的接入是构建股票行情软件的首要步骤。根据使用场景和需求,可以选择不同类型的公开API来获取实时或历史数据。这些数据源包括但不限于各大证券交易所的API、金融数据服务商提供的API等。它们通常提供了丰富多样的数据,如股票价格、交易量、公司财务报表、宏观经济数据等。
2.1.1 公开API的数据获取
对于股票行情软件来说,接入可靠且更新速度快的公开API至关重要。例如,可以使用如Yahoo Finance、Alpha Vantage、Google Finance等提供的股票数据API。这些API通常提供RESTful接口或WebSocket接口,允许开发者获取最新股票价格、历史价格数据等。
下面是一个使用Python语言通过requests库接入Yahoo Finance API的示例代码:
import requests
import pandas as pd
def get_stock_data(ticker):
url = f"https://query1.finance.yahoo.com/v8/finance/chart/{ticker}?interval=1d&range=1mo&indicators=close"
response = requests.get(url)
if response.status_code == 200:
data = response.json()
# 进一步解析响应JSON对象,提取并处理股票数据
# ...
return processed_data
else:
return "Error fetching data"
# 使用函数获取特定股票代码的数据
stock_data = get_stock_data('AAPL')
在上述代码中,我们首先定义了一个函数 get_stock_data ,该函数接受一个股票代码(ticker)作为参数,然后构建了Yahoo Finance API的请求URL。通过 requests.get 发起网络请求,并检查响应状态码。如果请求成功,我们将对返回的JSON对象进行解析,并进一步处理数据以满足我们的需求。
2.1.2 数据格式与转换
从API获取的数据通常以JSON、XML或CSV格式返回。在处理这些数据时,需要进行数据格式转换以适应后续处理流程。例如,JSON数据通常需要解析为Python字典,而CSV数据需要转换为pandas DataFrame以便于数据分析和处理。
下面是一个示例,展示如何将JSON格式的股票数据转换为pandas DataFrame:
import pandas as pd
# 假设response_json是从API获取的JSON数据,并已经被正确解析为字典格式
response_json = get_stock_data('AAPL')
# 将JSON格式数据转换为DataFrame
df = pd.json_normalize(response_json['chart']['result'][0]['indicators']['quote'][0])
# 查看DataFrame结构
print(df.head())
在上述代码中, pd.json_normalize 函数用于将嵌套的JSON数据转换为扁平化的pandas DataFrame。之后,通过 head 方法查看DataFrame的前几行数据,以确保数据结构正确且符合预期。
2.2 数据处理技术的应用
数据获取之后,接下来需要进行数据处理,主要包括数据清洗和数据存储两个方面。数据清洗的目的是提高数据质量,确保后续分析和处理的准确性;而数据存储解决方案则是为了安全、高效地保存处理后的数据,为前端展示和用户交互提供支持。
2.2.1 数据清洗的方法与策略
数据清洗是确保数据质量的重要步骤。它包括处理缺失值、异常值、重复数据等。在股票数据中,例如,可以包括去除由于技术故障或人为错误导致的异常价格波动,或者删除历史数据中因退市等原因造成的股票记录等。
下面是一个使用pandas进行数据清洗的示例代码:
import pandas as pd
# 假设df是已经加载的股票数据DataFrame
# 以下操作将以该DataFrame为基础进行数据清洗
# 删除重复数据
df.drop_duplicates(inplace=True)
# 处理缺失值,此处简单地用前后值填充
df.fillna(method='ffill', inplace=True)
# 处理异常值,例如去除价格异常高或异常低的数据点
# 此处使用条件筛选来完成此操作
df = df[(df['Close'] > df['Close'].quantile(0.01)) & (df['Close'] < df['Close'].quantile(0.99))]
# 查看清洗后的数据
print(df.head())
在上述代码中,我们首先使用 drop_duplicates 方法删除重复的股票数据记录。接着,使用 fillna 方法填充缺失值,其中 method='ffill' 表示用前一个非缺失值填充当前的缺失值。最后,我们通过条件筛选删除了价格异常值,这里简单地使用了四分位数的方法来定义正常范围,并移除了该范围之外的数据。
2.2.2 数据存储的解决方案
数据存储解决方案通常涉及选择合适的数据库和设计数据库架构。对于股票行情软件来说,轻量级数据库如SQLite或内存数据库如Redis都是不错的选择,因为它们通常需要处理大量的实时数据并提供快速的查询响应。
下面是一个展示如何使用SQLite存储股票数据的简单示例:
import sqlite3
import pandas as pd
# 假设df是已经清洗好的DataFrame数据
# 连接到SQLite数据库
# 如果数据库不存在,将会自动创建一个数据库文件
conn = sqlite3.connect('stock_data.db')
# 将DataFrame数据导入SQLite数据库中
df.to_sql('stock_data', conn, if_exists='replace', index=False)
# 关闭数据库连接
conn.close()
在上述代码中,我们使用pandas的 to_sql 方法将DataFrame数据直接导入到SQLite数据库中。这里, if_exists='replace' 参数表示如果表已经存在,将会替换掉旧表。 index=False 参数表示在导入数据时不将DataFrame的索引作为数据的一部分导入。
通过上述步骤,股票数据已经被清洗并存储到数据库中,为后续的数据分析和可视化提供了基础。在下一章节中,我们将讨论如何集成和优化轻量级数据库,以及如何实现数据的可视化展示。
3. 轻量级数据库的应用与数据可视化
在IT行业和相关行业,数据处理和展示的重要性不言而喻。特别是在股票行情软件中,轻量级数据库的应用能够带来快速的数据处理和低资源消耗,而数据可视化则能提供直观的图表信息,帮助用户更好地理解市场动态。本章节将深入探讨轻量级数据库SQLite的集成与优化,以及如何实现K线图等复杂数据的可视化。
3.1 轻量级数据库SQLite的集成与优化
3.1.1 数据库架构与设计
SQLite是一个轻量级的数据库,不需要配置一个单独的服务器进程或系统就能运行。这种特性使得SQLite非常适合资源受限的环境,如嵌入式设备或桌面应用程序。在股票行情软件中,集成SQLite可以有效地管理大量股票数据和用户信息。
数据库架构设计是建立高效、可靠数据库系统的关键。考虑到数据的读写频繁度,可以设计一个多层数据模型,包括原始数据层、索引层和缓存层。这样的设计可以保证数据检索的快速响应。
3.1.2 数据库性能优化技巧
尽管SQLite是为嵌入式环境设计的,但其性能在大量数据的场景下可能仍会受限。为确保数据库能够高效运行,需要采取一些优化措施:
-
索引优化:创建索引可以显著提升查询速度,但应避免过度索引以避免降低插入和更新操作的性能。
-
查询优化:编写高效的SQL查询能够减少不必要的数据加载和处理。使用EXPLAIN QUERY PLAN可以了解查询的执行计划,进而优化查询。
-
精简数据模型:尽可能减少数据表的行数和列数,尤其是对于那些经常查询的表。
-
事务管理:合理使用事务能够保证数据的一致性,避免长时间锁表影响性能。
下面是一个示例代码块,演示如何在Python中使用SQLite进行数据插入操作,并附有逻辑分析和参数说明:
import sqlite3
# 连接到SQLite数据库
# 数据库文件是test.db,如果文件不存在,会自动在当前目录创建:
conn = sqlite3.connect('test.db')
cursor = conn.cursor()
# 创建一个表:
cursor.execute('CREATE TABLE stock_data (id INTEGER PRIMARY KEY, symbol TEXT, price REAL, volume INTEGER)')
# 插入数据的函数
def insert_data(symbol, price, volume):
cursor.execute('INSERT INTO stock_data (symbol, price, volume) VALUES (?, ?, ?)', (symbol, price, volume))
# 提交事务:
conn.commit()
# 插入数据示例
insert_data('AAPL', 150.0, 100000)
# 关闭Cursor和Connection:
cursor.close()
conn.close()
在上述代码中,我们首先创建了一个SQLite数据库连接。然后执行了一个SQL语句来创建一个名为 stock_data 的表,其中包含股票代码、价格和成交量等字段。接着定义了一个 insert_data 函数用于向表中插入新的股票数据记录。最后,在插入操作后提交了事务并关闭了cursor和连接。
3.2 K线图数据的可视化实现
3.2.1 图表库的选择与配置
实现股票行情软件中的K线图数据可视化,选择合适的图表库是关键。常用的图表库包括Highcharts、Chart.js、D3.js等。这些库都有各自的特点,例如Highcharts提供了丰富的API和成熟的商业用途解决方案,Chart.js则因其简洁和易用性而受到欢迎。
配置图表库时,通常需要包含JavaScript文件、CSS样式表和一些基本的HTML结构。下面的代码展示了如何在HTML中嵌入Highcharts并进行基础配置:
<!DOCTYPE html>
<html>
<head>
<title>Highcharts Example</title>
<script src="https://code.highcharts.com/highcharts.js"></script>
</head>
<body>
<div id="container" style="width: 100%; height: 400px;"></div>
<script>
Highcharts.chart('container', {
title: {
text: 'AAPL Stock Price'
},
series: [{
name: 'AAPL Stock Price',
data: [[...]] // 这里填充股票价格数据
}]
});
</script>
</body>
</html>
在上述HTML代码中,我们通过 <script> 标签引入了Highcharts的JavaScript文件,然后创建了一个 <div> 元素作为图表容器。接着,通过JavaScript初始化Highcharts实例,并设置图表标题和数据。
3.2.2 交互式K线图的开发
K线图的交互性是提升用户体验的重要方面。一个好的交互式K线图可以让用户通过缩放、拖动、高亮等多种方式来分析股票走势。
开发交互式K线图的一个关键步骤是创建数据结构来表示K线图中的蜡烛图(Candlestick chart)。下面是一个简单的蜡烛图数据结构的示例:
// 示例数据:[时间戳, 开盘价, 最高价, 最低价, 收盘价]
const aaplData = [
[Date.UTC(2023, 1, 1), 150, 155, 148, 154],
[Date.UTC(2023, 1, 2), 154, 159, 153, 157],
// ...
];
在这个结构中,我们使用一个数组来表示每一根蜡烛图的开盘价、收盘价、最高价和最低价。时间戳用于定位K线图中的具体蜡烛图。
然后,可以使用Highcharts的API来创建一个交互式蜡烛图:
// ...(在初始化Highcharts实例时添加)
series: [{
type: 'candlestick',
name: 'AAPL',
data: aaplData,
tooltip: {
valueDecimals: 2
}
}],
// 添加缩放功能
chart: {
zoomType: 'x'
},
// 添加时间轴控制
xAxis: {
type: 'datetime'
}
在这个配置中,我们指定了 series 中的 type 为 candlestick 以显示蜡烛图,并提供了之前创建的蜡烛图数据。我们还设置了 chart.zoomType 为 x ,这允许用户对时间轴进行水平缩放。 xAxis.type 设置为 datetime 确保了X轴是以时间序列显示的。
通过上述步骤,我们可以创建一个功能完善的交互式K线图,为用户提供直观、易操作的股票行情分析工具。
4. 技术指标算法与搜索功能实现
4.1 技术指标的算法应用
技术指标是股票市场分析中不可或缺的一部分,它们基于历史价格数据计算出某些指标值,用于预测市场动向和指导交易决策。在本小节中,我们将重点讲解两种广泛使用的技术指标:移动平均收敛散度(MACD)和相对强弱指数(RSI)。
4.1.1 MACD算法的实现与应用
MACD(Moving Average Convergence Divergence)是通过计算快速和慢速移动平均线之间的差异和其9天指数平滑移动平均来展示趋势的动向和强度。一个典型的MACD系统由两个主要部分组成:MACD线和信号线,以及一个柱状图表示两者之间的差异。
import numpy as np
import pandas as pd
def calculate_macd(prices, short_window=12, long_window=26, signal_window=9):
"""
Calculate the MACD for the given prices using the specified window lengths.
:param prices: A list of closing prices for the stock.
:param short_window: Shorter moving average window.
:param long_window: Longer moving average window.
:param signal_window: Moving average window for the signal line.
:return: Dataframe containing the MACD line, signal line, and histogram values.
"""
exp1 = prices.ewm(span=short_window, adjust=False).mean()
exp2 = prices.ewm(span=long_window, adjust=False).mean()
macd = exp1 - exp2
signal = macd.ewm(span=signal_window, adjust=False).mean()
histogram = macd - signal
return pd.DataFrame({'MACD': macd, 'Signal Line': signal, 'Histogram': histogram})
# Example usage:
# Assuming 'df' is a pandas DataFrame containing closing prices in a column 'Close'
macd_result = calculate_macd(df['Close'])
MACD的算法实现通常遵循以下步骤:
1. 计算短期和长期指数移动平均(EMA)。
2. 从短期EMA中减去长期EMA得到MACD线。
3. 再计算MACD线的9天指数移动平均(信号线)。
4. 柱状图(直方图)是MACD线与信号线的差值。
当MACD线上穿信号线时,常被视为买入信号;反之,MACD线下穿信号线则被视为卖出信号。
4.1.2 RSI指标的计算与分析
RSI(Relative Strength Index)相对强弱指数是一种衡量一定期间内价格涨跌幅度的技术指标,用来评估股票或其他资产的超买或超卖条件。RSI通常在0到100之间波动,通常认为RSI低于30时为超卖,高于70时为超买。
def calculate_rsi(data, period=14):
"""
Calculate the RSI for the given data series with the specified period.
:param data: A list of closing prices for the stock.
:param period: The RSI calculation period.
:return: RSI values as a list.
"""
delta = np.diff(data['Close'])
up, down = delta.copy(), delta.copy()
up[up < 0] = 0
down[down > 0] = 0
# Calculate the exponential averages
roll_up = up.ewm(span=period).mean()
roll_down = down.abs().ewm(span=period).mean()
# Calculate the RSI
RS = roll_up / roll_down
RSI = 100.0 - (100.0 / (1.0 + RS))
return RSI
# Example usage:
# Assuming 'df' is a pandas DataFrame containing closing prices in a column 'Close'
df['RSI'] = calculate_rsi(df)
RSI的计算步骤包括:
1. 计算价格变动,即每日收盘价的差分。
2. 分别计算一定周期内的上涨和下跌的平均值。
3. 利用上涨平均值除以下跌平均值得到RS(相对强度)。
4. 将RS值转换为RSI值,公式为100 - (100 / (1 + RS))。
RSI是分析短期市场动向的理想工具,它可以用来辨识潜在的市场反转或寻找买入和卖出点。
在实际应用中,技术指标需要结合具体的操作策略,并考虑其他市场因素,如交易量、新闻事件等。技术指标通常作为辅助决策工具,而不是唯一的决策依据。
4.2 筛选和搜索算法的实现
股票行情软件中通常会提供股票筛选和搜索功能,方便用户根据特定条件快速找到感兴趣的股票。本小节将对筛选和搜索算法的设计原理及其优化进行探讨。
4.2.1 搜索算法的设计原理
搜索算法通常用于快速定位数据中的特定项或满足特定条件的数据集合。在股票筛选和搜索功能中,搜索算法需要考虑的关键点包括:
- 效率 :确保搜索过程尽可能快速。
- 准确性 :准确地返回符合用户筛选条件的股票。
- 实时性 :在实时更新的数据中快速反映搜索结果。
- 易用性 :提供直观的搜索界面,让用户轻松表达搜索意图。
在设计搜索算法时,可以采用二分搜索、哈希表、索引等技术来提高搜索效率。例如,如果对股票代码进行搜索,可以预先构建一个哈希表来存储股票代码和相关数据的映射关系,从而实现接近O(1)的搜索时间复杂度。
4.2.2 搜索功能的优化与用户体验
优化搜索功能,除了算法层面的改进外,还需从用户体验角度出发,提高搜索功能的友好性和实用性。以下是几点优化搜索功能的建议:
- 模糊搜索 :提供模糊搜索功能,允许用户通过输入不完整的信息来查找股票。
- 自动补全 :在用户输入时,实时提供可能的搜索词或股票代码的自动补全建议。
- 搜索结果排序 :根据相关性或用户偏好对搜索结果进行排序。
- 过滤器和排序选项 :允许用户通过不同的条件过滤和排序搜索结果,例如按涨跌幅、成交量、市值等。
- 历史记录 :保存用户的搜索历史,方便快速重新发起搜索。
// Example of a simple auto-complete functionality in JavaScript
function autocomplete(input, loc) {
var url = 'https://api.example.com/search?q=' + input;
fetch(url)
.then(response => response.json())
.then(data => {
var results = data.results;
// Display the results using your front-end framework or DOM manipulation
});
}
// Call the autocomplete function on user input
autocomplete('AAPL', 'search-input');
在前端实现时,可以使用如React、Vue或Angular等现代前端框架配合异步数据加载,提供流畅的用户体验。通过API接口,后端可以提供实时的搜索建议或自动补全数据。
通过不断优化搜索算法和提升用户体验,股票行情软件能够更好地满足不同用户的需求,从而在竞争激烈的金融市场中脱颖而出。
5. 实时数据更新与网络编程
5.1 实时数据更新API接口的应用
5.1.1 API接口的选择与维护
在实时数据更新中,选择合适的API接口是基础。我们首先要了解市面上提供的数据服务,比如Yahoo Finance、Google Finance或专业的金融数据供应商。通常,这些服务提供从简单的股票价格到复杂的交易和财务报告数据,应根据应用需求进行选择。
维护API接口包括处理API的调用频率限制、数据准确性和完整性以及API的可用性。例如,处理频率限制可以通过引入延迟、缓存数据或升级到付费服务来解决。确保数据的准确性和完整性,则要求我们在获取数据后进行校验和必要的修正。
import requests
from requests.exceptions import HTTPError
def fetch_stock_data(api_url):
try:
response = requests.get(api_url)
response.raise_for_status()
return response.json()
except HTTPError as http_err:
print(f'HTTP error occurred: {http_err}')
except Exception as err:
print(f'An error occurred: {err}')
api_url = 'https://api.yfinance.com/api/v7/quote?symbol=MSFT'
stock_data = fetch_stock_data(api_url)
print(stock_data)
5.1.2 数据实时更新机制的设计
实现数据实时更新通常涉及到定时任务的设置或使用WebSocket等实时数据传输技术。例如,Python的 schedule 库可以用来设置定时任务,而 websockets 库可以用来处理实时数据流。
定时任务示例代码:
import schedule
import time
def job():
print("Updating stock data...")
# 更新数据的代码逻辑
schedule.every(5).minutes.do(job)
while True:
schedule.run_pending()
time.sleep(1)
WebSocket实时数据处理示例:
import asyncio
import websockets
async def subscribe(stock, ws_uri):
uri = f"{ws_uri}?symbol={stock}"
async with websockets.connect(uri) as websocket:
async for message in websocket:
data = json.loads(message)
print(f"Received real-time data update for {stock}: {data}")
# 使用asyncio事件循环启动WebSocket客户端
async def main():
stocks = ["MSFT", "AAPL"]
uri = "wss://streamer.example.com"
tasks = [subscribe(stock, uri) for stock in stocks]
await asyncio.gather(*tasks)
asyncio.run(main())
5.2 网络请求与数据解析技术
5.2.1 异步网络请求的实现
异步编程可以显著提高网络请求的效率,尤其是在需要处理大量并发请求时。Python中的 asyncio 库可以用来编写异步网络请求,而 aiohttp 是一个支持异步请求的HTTP客户端/服务器。
示例代码使用 aiohttp 实现异步网络请求:
import aiohttp
import asyncio
async def fetch_data(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
html = await fetch_data(session, 'https://api.example.com/data')
# 解析html或进行后续处理
asyncio.run(main())
5.2.2 数据解析的方法与实践
获取到的原始数据往往需要进行解析才能使用。常用的解析库包括 BeautifulSoup 用于解析HTML和XML, json 库用于解析JSON数据。
HTML解析示例:
from bs4 import BeautifulSoup
def parse_html(html):
soup = BeautifulSoup(html, 'html.parser')
data = soup.find('div', {'id': 'data'})
return data.get_text()
html_content = "<div id='data'>2023-01-01</div>"
parsed_data = parse_html(html_content)
print(parsed_data)
JSON解析示例:
import json
def parse_json(json_data):
data = json.loads(json_data)
return data['stock']
json_content = '{"stock": "MSFT", "price": 300}'
parsed_data = parse_json(json_content)
print(parsed_data)
5.3 编程语言与GUI库的使用
5.3.1 常见编程语言的优缺点分析
不同的编程语言适合不同类型的项目。例如,Python以其简洁的语法和强大的库支持而著称,适合快速开发和数据分析。C++则提供了更好的性能,适合需要高性能计算的场景。JavaScript则是前端开发的主流语言,配合Node.js也可以用于后端开发。
| 语言 | 优点 | 缺点 |
|---|---|---|
| Python | 易学易用、广泛的库支持 | 性能相对较低 |
| C++ | 高性能、系统级编程 | 语法复杂、开发效率相对低 |
| JavaScript | 前后端通用、异步编程支持 | 不适合复杂算法开发 |
5.3.2 GUI库的选择与界面设计
图形用户界面(GUI)库的选择直接影响到用户体验。常用的GUI库包括Python的 Tkinter 、 PyQt 和 wxPython ,它们各有千秋。
Tkinter:简单易学,适合快速原型开发。PyQt:功能强大,提供丰富的控件和工具,适合复杂应用开发。wxPython:跨平台性能好,界面美观。
GUI界面设计示例:
import tkinter as tk
def update_price():
# 假设有一个函数 fetch_real_time_price() 获取实时股价
price = fetch_real_time_price()
price_label.config(text=f"Current Price: {price}")
# 创建Tkinter窗口
root = tk.Tk()
root.title("Stock Price Tracker")
price_label = tk.Label(root, text="Current Price: ", font=("Helvetica", 16))
price_label.pack()
update_button = tk.Button(root, text="Update Price", command=update_price)
update_button.pack()
root.mainloop()
以上就是实时数据更新与网络编程的关键部分。通过API接口的应用、异步网络请求的实现、编程语言和GUI库的选择与使用,我们可以构建一个功能齐全、用户体验优良的股票行情软件。
简介:股票行情软件为个人投资者提供实时或历史数据的展示和分析,尽管本文介绍的软件不提供源代码,但文章会讨论此类软件的核心功能与技术。关键功能包括数据获取与处理、高效数据显示、搜索与筛选技术、实时数据更新机制、编程语言与GUI库的使用,以及数据安全和隐私保护。了解这些技术要点有助于理解股票行情软件的设计和开发。

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)