
在 Python 中使用神经网络检测语音中的情绪
在数据科学训练营期间,我构建了一个机器学习模型,可以从语音(预先录制的文件和现场录制的声音)中检测情绪。该代码可在我的 GitHub上找到。 这是我从事过的最具挑战性的项目之一,但也是最令人兴奋的。在这篇文章中,我将引导您完成我的项目:从规划和选择数据集到构建机器学习模型并评估它们的性能。 项目规划 首先,我在简要查看数据集后设计了一个项目计划。从我的工作经验和过去三个月完成的任务中,我了解到这一
在数据科学训练营期间,我构建了一个机器学习模型,可以从语音(预先录制的文件和现场录制的声音)中检测情绪。该代码可在我的 GitHub上找到。
这是我从事过的最具挑战性的项目之一,但也是最令人兴奋的。在这篇文章中,我将引导您完成我的项目:从规划和选择数据集到构建机器学习模型并评估它们的性能。
项目规划
首先,我在简要查看数据集后设计了一个项目计划。从我的工作经验和过去三个月完成的任务中,我了解到这一步对于编码项目的成功至关重要。计划帮助我(和团队)组织我的想法,将大项目分解为更小的任务,识别问题并跟踪进度——而不是对短时间内完成的工作量感到绝望。
为此,我直接在我项目的 GitHub 存储库中创建了一个简单的看板,这样我就可以将代码和任务放在一个地方。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--AJhfz2q4--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://lorenaciutacu. files.wordpress.com/2021/01/screenshot_2020-12-11-lorenanda-speech-emotion-recognition.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--AJhfz2q4--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://lorenaciutacu. files.wordpress.com/2021/01/screenshot_2020-12-11-lorenanda-speech-emotion-recognition.png)
GitHub 中的项目板
要创建链接到 GitHub 中的存储库的项目板:
-
在您想要的存储库中,单击选项卡
Projects,然后单击Create project。 -
输入
Project board name。
3.(可选)输入项目的Description,选择Project template。
- 点击
Create project。
数据集
我使用了 RAVDESS 数据集,其中包含 1440 个音频文件。这些是 24 名演员(12 名男性,12 名女性)的录音,他们以两种不同的强度(正常和强烈)用 8 种语调说出两个句子,表达不同的情绪:平静、快乐、悲伤、愤怒、恐惧、惊讶、厌恶和中性的。每种情绪都有 192 条录音,除了中性,没有强烈强度的录音。
综上所述,原始的RAVDESS数据集包括:
-
1440 条记录
-
24 个扬声器
-
12男12女
-
2 句
-
2 个强度
-
8 语调/情绪
-
192 条记录 7 种情绪
-
96 条记录对应 1 种情绪
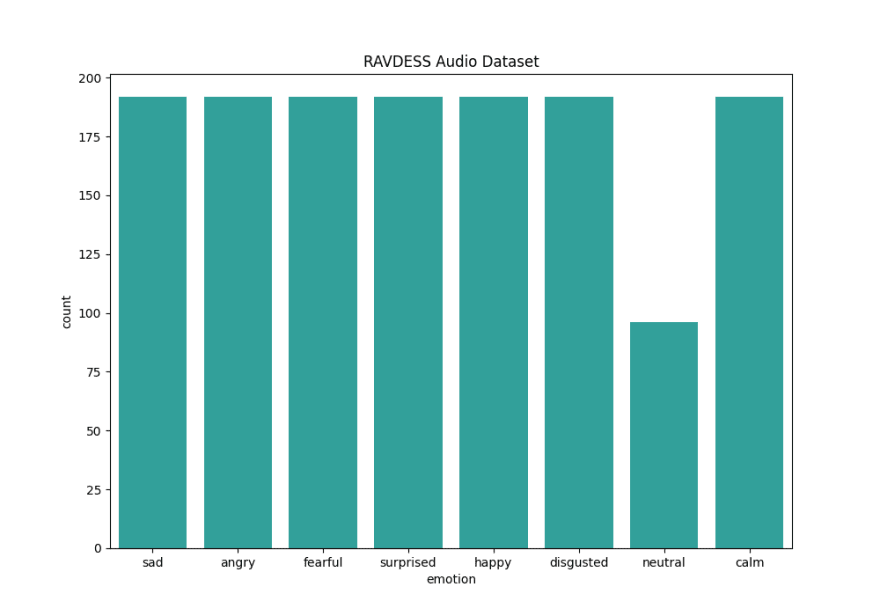
_ RAVDESS 数据集分布 _
过采样
数据集不平衡,所以我使用RandomOversample方法为中性类创建新特征。
def oversample(X, y):
X = joblib.load("speech_emotion_recognition/features/X.joblib")
y = joblib.load("speech_emotion_recognition/features/y.joblib")
print(Counter(y))
oversample = RandomOverSampler(sampling_strategy="minority")
X_over, y_over = oversample.fit_resample(X, y)
X_over_save, y_over_save = "X_over.joblib", "y_over.joblib"
joblib.dump(X_over, os.path.join("speech_emotion_recognition/features/", X_over_save))
joblib.dump(y_over, os.path.join("speech_emotion_recognition/features/", y_over_save))
进入全屏模式 退出全屏模式
过采样添加了 96 个新数据点,所以最后我有 1536 个音频文件 可以使用。
另一个不平衡与性别有关:男性的录音略多,强度正常。我没有处理这种不平衡,因为它对我的项目并不重要,因为我只想预测情绪。但是,将来探索会很有趣。
特征提取
可以从音频文件中提取许多特征,但我决定使用 Mel 频率倒谱系数 (MFCC)。
梅尔频率倒谱 (MFC) 是声音的短期功率谱的表示,它基于非线性梅尔频率标度上的对数功率谱的线性余弦变换。梅尔频率倒谱系数 (MFCC) 是共同构成 MFC 的系数。
倒谱和梅尔频率倒谱的区别在于,在 MFC 中,频带在 mel 标度上等距分布,这比正常频谱中使用的线性间隔频带更接近人类听觉系统的响应.这种频率扭曲可以更好地表示声音,例如在音频压缩中。
来源
为了从音频文件中提取 MFCC,我使用了 Python 库librosa:
def extract_features(path, save_dir):
feature_list = []
start_time = time.time()
for dir, _, files in os.walk(path):
for file in files:
y_lib, sample_rate = librosa.load(
os.path.join(dir, file), res_type="kaiser_fast"
)
mfccs = np.mean(
librosa.feature.mfcc(y=y_lib, sr=sample_rate, n_mfcc=40).T, axis=0
)
file = int(file[7:8]) - 1
arr = mfccs, file
feature_list.append(arr)
print("Data loaded in %s seconds." % (time.time() - start_time))
X, y = zip(*feature_list)
X, y = np.asarray(X), np.asarray(y)
print(X.shape, y.shape)
X_save, y_save = "X.joblib", "y.joblib"
joblib.dump(X, os.path.join(save_dir, X_save))
joblib.dump(y, os.path.join(save_dir, y_save))
return "Preprocessing completed."
进入全屏模式 退出全屏模式
MFCC 的视觉表示如下所示:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--BYQYdV0q--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://lorenaciutacu.files。 html).wordpress.com/2020/12/mfcc1.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--BYQYdV0q--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://lorenaciutacu.files。 html).wordpress.com/2020/12/mfcc1.png)
MFCC情节
机器学习模型
我在 MFCC 和情感标签上训练了三种不同的神经网络模型:
- 多层感知器 (MLP)
def mlp_classifier(X, y):
X_train, X_test, y_train, y_test u003d train_test_split(
X, y, test_sizeu003d0.2, random_stateu003d42
)
mlp_model u003d MLPClassifier(
hidden_layer_sizesu003d(100,),
求解器u003d“亚当”,
阿尔法u003d0.001,
洗牌u003d真,
详细u003d真,
动量u003d0.8,
)
- 卷积神经网络 (CNN)
def cnn_model(X, y):
X_train, X_test, y_train, y_test u003d train_test_split(
X, y, test_sizeu003d0.2, random_stateu003d42
)
x_traincnn u003d np.expand_dims(X_train, axisu003d2)
x_testcnn u003d np.expand_dims(X_test, axisu003d2)
模型u003d顺序()
model.add(Conv1D(16, 5, paddingu003d"same", input_shapeu003d(40, 1)))
model.add(激活(“relu”))
model.add(Conv1D(8, 5, paddingu003d"same"))
model.add(激活(“relu”))
模型.add(
转换1D(
8、
5、
填充u003d“相同”,
)
)
model.add(激活(“relu”))
model.add(BatchNormalization())
model.add(激活(“relu”))
model.add(展平())
模型.add(密集(8))
model.add(激活(“softmax”))
模型.编译(
lossu003d"categorical_crossentropy",
优化器u003d"亚当",
指标u003d [“准确性”],
)
cnn_history u003d model.fit(
x_traincnn,
y_train,
批量大小u003d50,
时期u003d100,
验证数据u003d(x_testcnn,y_test),
)
- 长短期记忆 (LSTM)
def lstm_model(X, y):
X_train, X_test, y_train, y_test u003d train_test_split(
X, y, test_sizeu003d0.2, random_stateu003d42
)
X_train_lstm u003d np.expand_dims(X_train, axisu003d2)
X_test_lstm u003d np.expand_dims(X_test, axisu003d2)
lstm_model u003d 顺序()
lstm_model.add(LSTM(64, input_shapeu003d(40, 1), return_sequencesu003dTrue))
lstm_model.add(LSTM(32))
lstm_model.add(密集(32,激活u003d“relu”))
lstm_model.add(丢弃(0.1))
lstm_model.add(密集(8,激活u003d“softmax”))
lstm_model.compile(
optimizeru003d"adam", lossu003d"categorical_crossentropy", metricsu003d["accuracy"]
)
lstm model.summary()
lstm_history u003d lstm_model.fit(X_train_lstm, y_train, batch_sizeu003d32, epochsu003d100)
经过多次调整超参数的迭代后,我发现通常模型在低学习率 (0.001)、adam优化器和更少层数的情况下表现更好。所有模型都过拟合(它们无法对看不见的数据进行泛化),但这似乎是神经网络和音频数据中的常见问题。
正如预期的那样,MLP 的准确率最低,因为它是一个非常基本的模型(一个简单的前馈人工神经网络)。 CNN 和 LSTM 具有相似的训练准确率 (80%),但 CNN 在测试数据上的表现 (60%) 优于 LSTM (51%)。为您提供一些背景信息,用于语音分类的最先进模型的准确度为 70-80%,因此我对我的 CNN 模型准确度非常满意。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--iiFP-kvl--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// /lorenaciutacu.files.wordpress.com/2020/12/models_accuracy.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--iiFP-kvl--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// /lorenaciutacu.files.wordpress.com/2020/12/models_accuracy.png)
不同机器学习模型的准确性
查看实际情绪与预测情绪特别有趣,看看哪些情绪被错误分类。从 CNN 和 LSTM 的相关矩阵中,我注意到这两个模型都错误地分类了听起来相似或模棱两可的情绪(即使对人类来说也是如此),比如悲伤-平静或愤怒-快乐。
 的混淆矩阵
的混淆矩阵
LSTM的混淆矩阵_
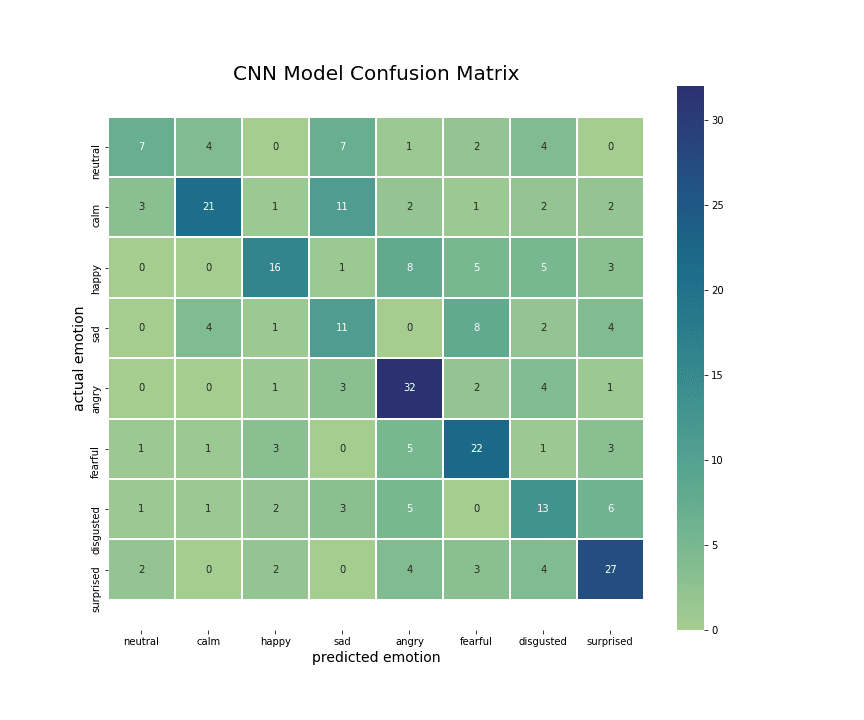 的混淆矩阵
的混淆矩阵
CNN的混淆矩阵
预测
令人兴奋的部分是对新数据进行预测,更具体地说是对电影声音片段和我自己的声音进行实时预测。为了录制我的声音,我使用了 Python 库sounddevice:
import soundfile as sf
import sounddevice as sd
from scipy.io.wavfile import write
def record_voice():
fs = 44100 # Sample rate
seconds = 3 # Duration of recording
# sd.default.device = "Built-in Audio" # Speakers full name here
print("Say something:")
myrecording = sd.rec(int(seconds * fs), samplerate=fs, channels=2)
sd.wait() # Wait until recording is finished
write("speech_emotion_recognition/recordings/myvoice.wav", fs, myrecording)
print("Voice recording saved.")
进入全屏模式 退出全屏模式
然后,我在预录和现场录制的音频文件上测试了 CNN 和 LSTM 模型:
def make_predictions(file):
cnn_model = keras.models.load_model(
"speech_emotion_recognition/models/cnn_model.h5"
)
lstm_model = keras.models.load_model(
"speech_emotion_recognition/models/lstm_model.h5"
)
prediction_data, prediction_sr = librosa.load(
file,
res_type="kaiser_fast",
duration=3,
sr=22050,
offset=0.5,
)
mfccs = np.mean(
librosa.feature.mfcc(y=prediction_data, sr=prediction_sr, n_mfcc=40).T, axis=0
)
x = np.expand_dims(mfccs, axis=1)
x = np.expand_dims(x, axis=0)
predictions = lstm_model.predict_classes(x)
emotions_dict = {
"0": "neutral",
"1": "calm",
"2": "happy",
"3": "sad",
"4": "angry",
"5": "fearful",
"6": "disgusted",
"7": "surprised",
}
for key, value in emotions_dict.items():
if int(key) == predictions:
label = value
print("This voice sounds", predictions, label)
进入全屏模式 退出全屏模式
两种模型都从录制的语音中识别出正确或似是而非的情绪!
后续步骤
从事这个项目非常令人兴奋,我已经在考虑以某些方式改进和扩展它:
-
尝试其他模型(不一定是神经网络)。
-
提取其他音频特征,看看它们是否是比 MFCC 更好的预测器。
-
在更大的数据集上进行训练,因为 1500 个文件和每种情绪只有 200 个样本是不够的。
-
对自然数据进行训练,即对人们在未上演的情况下讲话的录音进行训练,以使情绪化的讲话听起来更真实。
-
训练更多样化的数据,即不同文化和语言的人的录音。这很重要,因为情绪的表达因文化而异,并且也受个人经历的影响。
-
将语音与面部表情和文本(语音到文本)相结合,进行多模态情感分析。

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 2
2 0
0- 0



 已为社区贡献20434条内容
已为社区贡献20434条内容

所有评论(0)