hive实战案例讲解
本文主要介绍hive的一个案例实战,以及相关hive语句的书写,案例仅供参考
系列文章目录
hive进阶——在centos7里面配置mysql,将原来hive的客户端扩展
centos集群上安装hive客户端的操作步骤以及hive介绍
文章目录
4.3 统计出视频观看数最高的20 个视频的所属类别以及类别包含Top20 视频的个数
4.5 统计每个类别中的视频热度Top10,以Music 为例
4.7 统计上传视频最多的用户Top10 以及他们上传的视频观看次数在前20 的视频
前言
本文主要介绍hive的一个案例实战,以及相关hive语句的书写,案例仅供参考。
Hive 实战
1、需求描述
统计硅谷影音视频网站的常规指标,各种TopN 指标:
- -- 统计视频观看数Top10
- -- 统计视频类别热度Top10
- -- 统计出视频观看数最高的20 个视频的所属类别以及类别包含Top20 视频的个数
- -- 统计视频观看数Top50 所关联视频的所属类别排序
- -- 统计每个类别中的视频热度Top10,以Music 为例
- -- 统计每个类别视频观看数Top10
- -- 统计上传视频最多的用户Top10 以及他们上传的视频观看次数在前20 的视频
2、数据结构
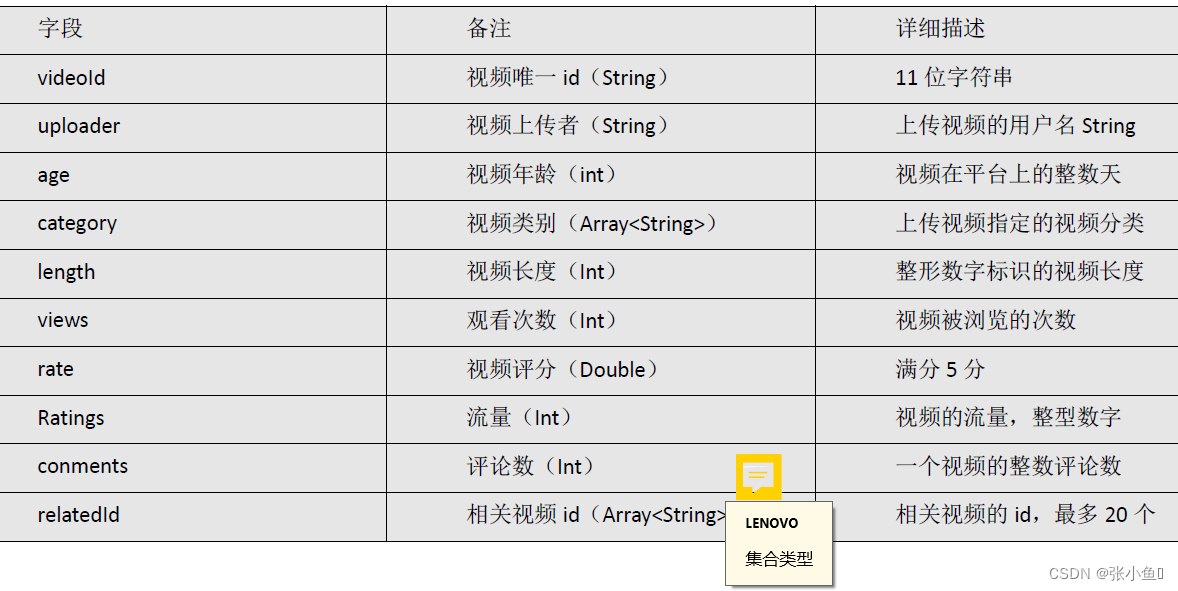
1)视频表
视频表
2)用户表
用户表

3、准备工作
3.1、准备表
1)需要准备的表
创建原始数据表:gulivideo_ori,gulivideo_user_ori,
创建最终表:gulivideo_orc,gulivideo_user_orc
3.2、创建原始数据表
(1)gulivideo_ori
create table gulivideo_ori(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited fields terminated by "\t"
collection items terminated by "&"
stored as textfile;(2)创建原始数据表: gulivideo_user_ori
create table gulivideo_user_ori(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by "\t"
stored as textfile;3.3、 创建orc 存储格式带snappy 压缩的表
(1)gulivideo_orc
create table gulivideo_orc(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
stored as orc
tblproperties("orc.compress"="SNAPPY");(2)gulivideo_user_orc
create table gulivideo_user_orc(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by "\t"
stored as orc
tblproperties("orc.compress"="SNAPPY");(3)向ori 表插入数据
load data local inpath "/opt/module/data/video" into table gulivideo_ori;
load data local inpath "/opt/module/user" into table gulivideo_user_ori;(4)向orc 表插入数据
insert into table gulivideo_orc select * from gulivideo_ori;
insert into table gulivideo_user_orc select * from gulivideo_user_ori;补充:创建 orc 存储 格式 带 snappy 压缩 的 表
在Hive中,可以使用以下语句创建一个存储格式为ORC,并且采用Snappy压缩的表:
CREATE TABLE table_name(
column1 data_type,
column2 data_type,
...
)
STORED AS ORC
TBLPROPERTIES("orc.compress"="SNAPPY");其中,table_name表示表名,column1、column2等表示表中的列名和对应的数据类型。STORED AS ORC表示存储格式为ORC,TBLPROPERTIES("orc.compress"="SNAPPY")表示采用Snappy压缩。
需要注意的是,创建ORC表时,如果需要使用Snappy压缩,需要先确保Hive的配置文件中开启了Snappy压缩,可以在hive-site.xml文件中添加如下配置信息:
<property>
<name>hive.exec.compress.output</name>
<value>true</value>
</property>
<property>
<name>hive.exec.compress.intermediate</name>
<value>true</value>
</property>
<property>
<name>hive.exec.compress.result</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>这样,在创建ORC表时,就可以使用Snappy压缩了。
4、业务统计
4.1、统计视频观看数Top10
思路:使用order by 按照views 字段做一个全局排序即可,同时我们设置只显示前10
条。
最终代码:
SELECT videoId,views
FROM gulivideo_orc
ORDER BY views DESC
LIMIT 10;4.2、统计视频类别热度Top10
思路:
(1)即统计每个类别有多少个视频,显示出包含视频最多的前10 个类别。
(2)我们需要按照类别group by 聚合,然后count 组内的videoId 个数即可。
(3)因为当前表结构为:一个视频对应一个或多个类别。所以如果要group by 类别,
需要先将类别进行列转行(展开),然后再进行count 即可。
(4)最后按照热度排序,显示前10 条。
最终代码:
SELECT t1.category_name ,COUNT(t1.videoId) hot
FROM (SELECT videoId,category_name
FROM gulivideo_orc
lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
) t1
GROUP BY t1.category_name
ORDER BY hot DESC
LIMIT 10;4.3 统计出视频观看数最高的20 个视频的所属类别以及类别包含Top20 视频的个数
思路:
(1)先找到观看数最高的20 个视频所属条目的所有信息,降序排列
(2)把这20 条信息中的category 分裂出来(列转行)
(3)最后查询视频分类名称和该分类下有多少个Top20 的视频
最终代码:
SELECTt2.category_name,COUNT(t2.videoId) video_sum
FROM (SELECT t1.videoId,category_name
FROM (SELECT videoId,views ,category
FROM gulivideo_orc
ORDER BY views DESC
LIMIT 20) t1
lateral VIEW explode(t1.category) t1_tmp AS category_name) t2
GROUP BY t2.category_name4.4 统计视频观看数Top50 所关联视频的所属类别排序
代码:
SELECT t6.category_name,t6.video_sum,
rank() over(ORDER BY t6.video_sum DESC ) rk
FROM (
SELECT t5.category_name,
COUNT(t5.relatedid_id) video_sum
FROM (
SELECT t4.relatedid_id,category_name
FROM (
SELECT t2.relatedid_id ,
t3.category
FROM (
SELECT
relatedid_id
FROM (
SELECT videoId,views,relatedid
FROM gulivideo_orc
ORDER BY views DESC
LIMIT 50
)t1
lateral VIEW explode(t1.relatedid) t1_tmp AS relatedid_id
)t2
JOIN gulivideo_orc t3 ON t2.relatedid_id = t3.videoId
) t4
lateral VIEW explode(t4.category) t4_tmp AS category_name
) t5
GROUP BY t5.category_name
ORDER BY video_sum DESC
) t64.5 统计每个类别中的视频热度Top10,以Music 为例
思路:
(1)要想统计Music 类别中的视频热度Top10,需要先找到Music 类别,那么就需要将
category 展开,所以可以创建一张表用于存放categoryId 展开的数据。
(2)向category 展开的表中插入数据。
(3)统计对应类别(Music)中的视频热度。
统计Music 类别的Top10(也可以统计其他)
SELECT t1.videoId,t1.views,t1.category_name
FROM (
SELECT videoId,views,category_name
FROM gulivideo_orc
lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
)t1
WHERE t1.category_name = "Music"
ORDER BY t1.views DESC
LIMIT 104.6 统计每个类别视频观看数Top10
最终代码:
SELECT t2.videoId,t2.views,t2.category_name,t2.rk
FROM (
SELECT t1.videoId,t1.views,t1.category_name,
rank() over(PARTITION BY t1.category_name ORDER BY t1.views DESC ) rk
FROM (
SELECT videoId,views,category_name
FROM gulivideo_orc
lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
)t1
)t2
WHERE t2.rk <=104.7 统计上传视频最多的用户Top10 以及他们上传的视频观看次数在前20 的视频
思路:
(1)求出上传视频最多的10 个用户
(2)关联gulivideo_orc 表,求出这10 个用户上传的所有的视频,按照观看数取前20
最终代码:
SELECT t2.videoId,t2.views,t2.uploader
FROM (
SELECT uploader,videos
FROM gulivideo_user_orc
ORDER BY videos DESC
LIMIT 10
) t1
JOIN gulivideo_orc t2 ON t1.uploader = t2.uploader
ORDER BY t2.views DESCLIMIT 20总结
以上就是今天的内容~
最后欢迎大家点赞👍,收藏⭐,转发🚀,
如有问题、建议,请您在评论区留言💬哦。

大数据从业者之家,一起探索大数据的无限可能!
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)