Flink 滚动窗口、滑动窗口详解
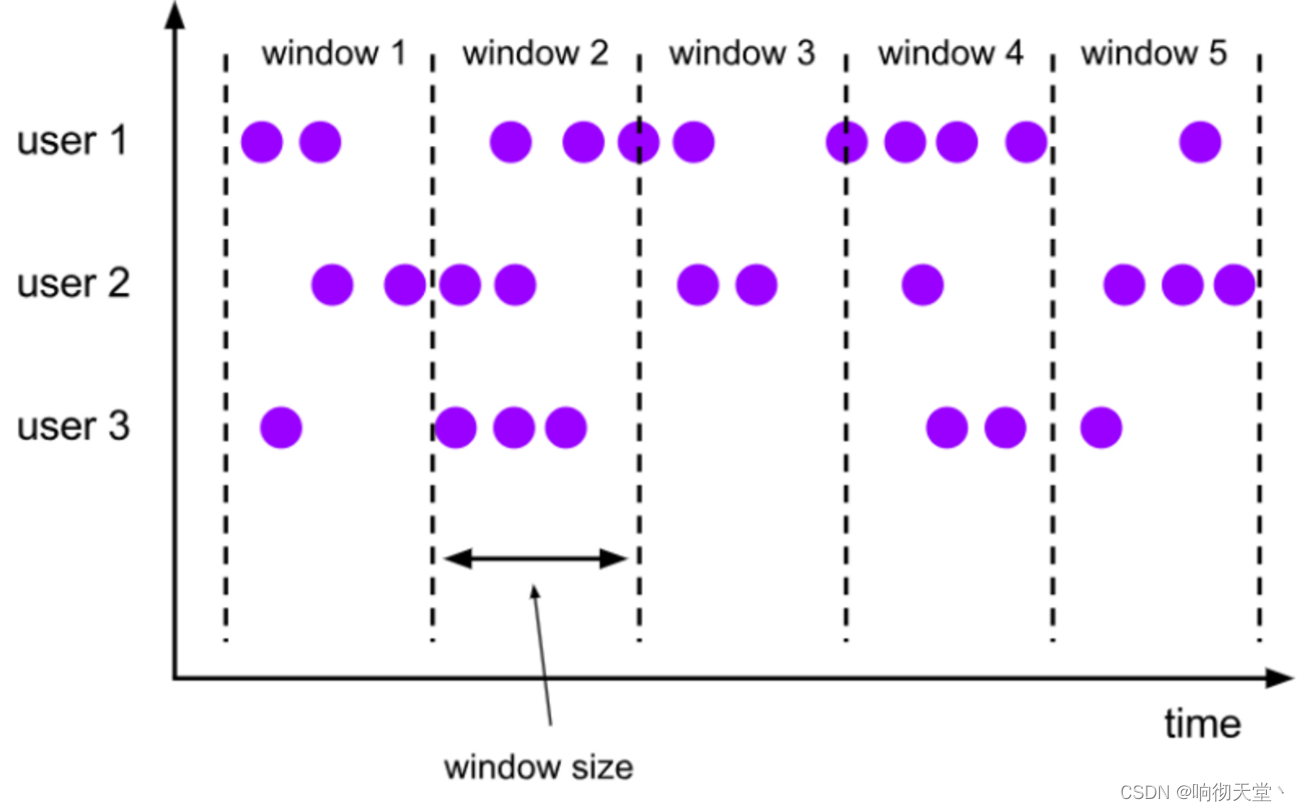
滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。如果我们把多个窗口的创建,看作一个窗口的运动,那就好像它在不停地向前“翻滚”一样。这是最简单的窗口形式,我们之前所举的例子都是滚动窗口。也正是因为滚动窗口是“无缝衔接”,所以每个数据都会被分配到一个窗口,而且只会属于一个窗口。滚动窗口可以基于时间定义,也可以基于数据个数定义;需要的参
1 滚动窗口(Tumbling Windows)
滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。如果我们把多个窗口的创建,看作一个窗口的运动,那就好像它在不停地向前“翻滚”一样。这是最简单的窗口形式,我们之前所举的例子都是滚动窗口。也正是因为滚动窗口是“无缝衔接”,所以每个数据都会被分配到一个窗口,而且只会属于一个窗口。
滚动窗口可以基于时间定义,也可以基于数据个数定义;需要的参数只有一个,就是窗口的大小(window size)。比如我们可以定义一个长度为 1 小时的滚动时间窗口,那么每个小时就会进行一次统计;或者定义一个长度为 10 的滚动计数窗口,就会每 10 个数进行一次统计。
2 滑动窗口(Sliding Windows)
与滚动窗口类似,滑动窗口的大小也是固定的。区别在于,窗口之间并不是首尾相接的,而是可以“错开”一定的位置。如果看作一个窗口的运动,那么就像是向前小步“滑动”一样。
既然是向前滑动,那么每一步滑多远,就也是可以控制的。所以定义滑动窗口的参数有两个:除去窗口大小(window size)之外,还有一个“滑动步长”(window slide),它其实就代
表了窗口计算的频率。滑动的距离代表了下个窗口开始的时间间隔,而窗口大小是固定的,所以也就是两个窗口结束时间的间隔;窗口在结束时间触发计算输出结果,那么滑动步长就代表
了计算频率。例如,我们定义一个长度为 1 小时、滑动步长为 5 分钟的滑动窗口,那么就会统计 1 小时内的数据,每 5 分钟统计一次。同样,滑动窗口可以基于时间定义,也可以基于数据
个数定义。
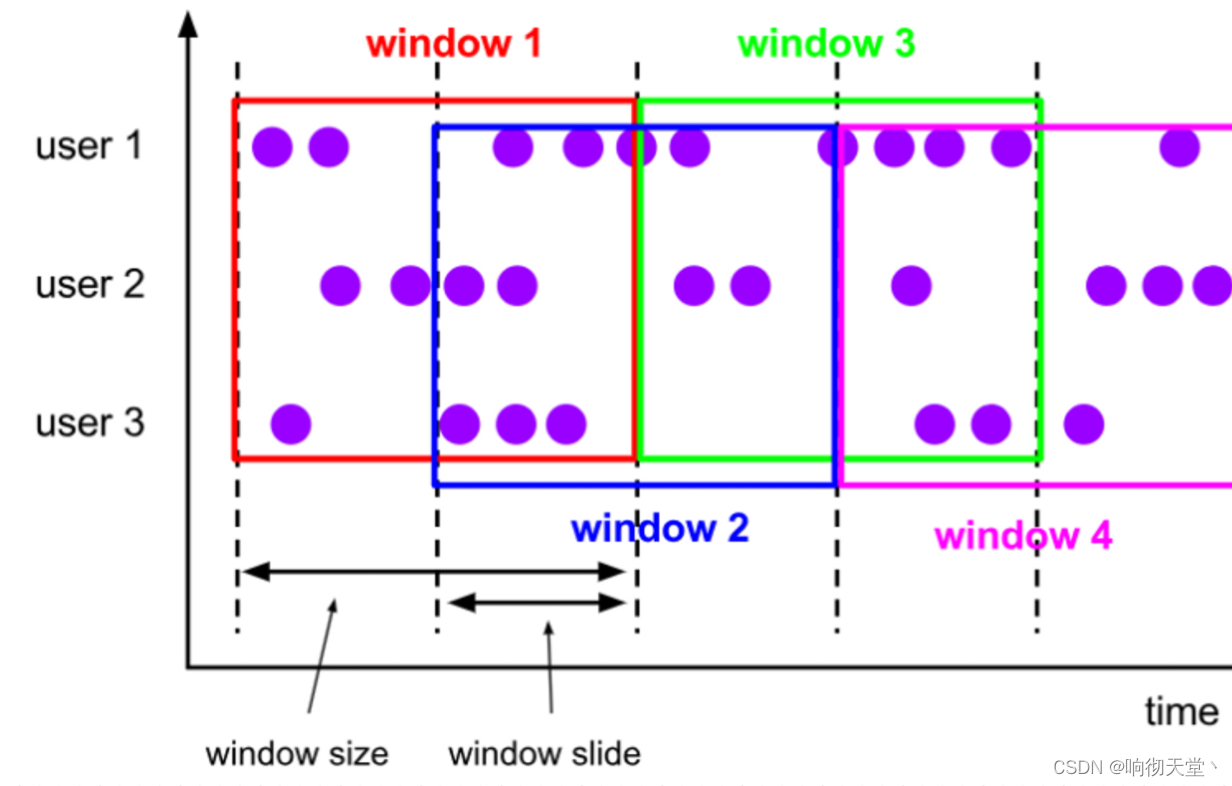
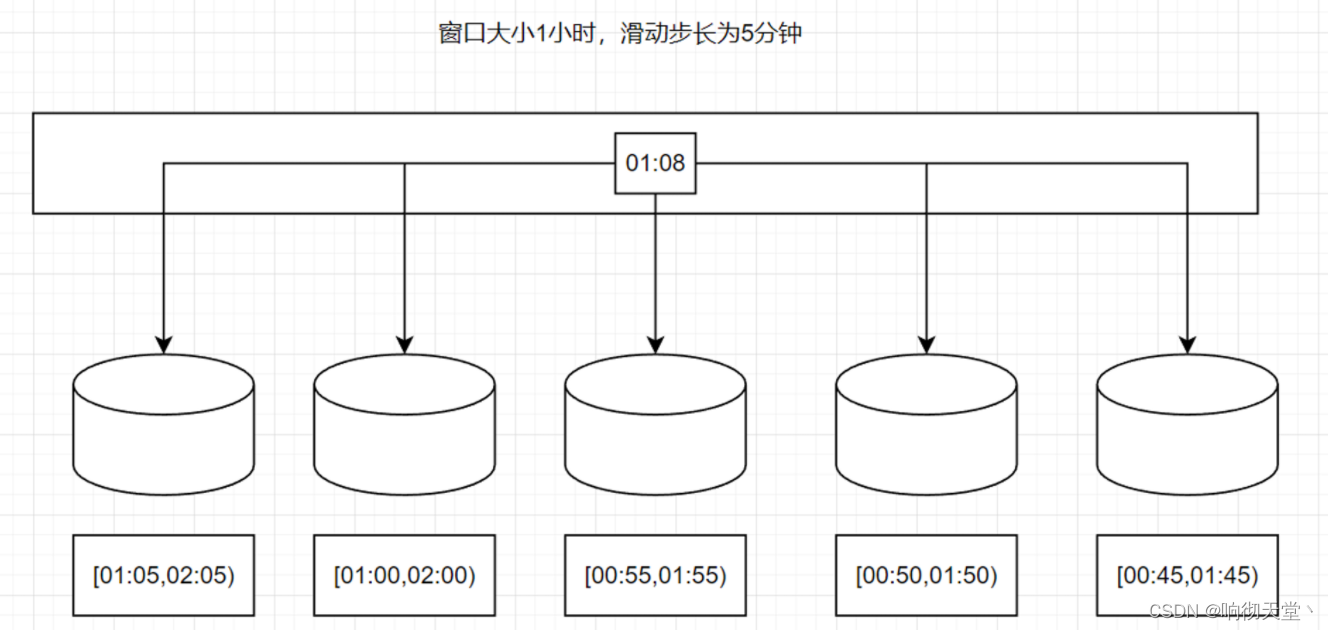
我们可以看到,当滑动步长小于窗口大小时,滑动窗口就会出现重叠,这时数据也可能会被同时分配到多个窗口中。而具体的个数,就由窗口大小和滑动步长的比值(size/slide)来决
定。如图 6-18 所示,滑动步长刚好是窗口大小的一半,那么每个数据都会被分配到 2 个窗口里。比如我们定义的窗口长度为 1 小时、滑动步长为 30 分钟,那么对于 8 点 55 分的数据,应该同时属于[8 点, 9 点)和[8 点半, 9 点半)两个窗口;而对于 8 点 10 分的数据,则同时属于[8点, 9 点)和[7 点半, 8 点半)两个窗口。所以,滑动窗口其实是固定大小窗口的更广义的一种形式;换句话说,滚动窗口也可以看作是一种特殊的滑动窗口——窗口大小等于滑动步长(size = slide)。当然,我们也可以定义滑动步长大于窗口大小,这样的话就会出现窗口不重叠、但会有间隔的情况;这时有些数据不
属于任何一个窗口,就会出现遗漏统计。所以一般情况下,我们会让滑动步长小于窗口大小,并尽量设置为整数倍的关系。
在一些场景中,可能需要统计最近一段时间内的指标,而结果的输出频率要求又很高,甚至要求实时更新,比如股票价格的 24 小时涨跌幅统计,或者基于一段时间内行为检测的异常报警。这时滑动窗口无疑就是很好的实现方式。
3 窗口API
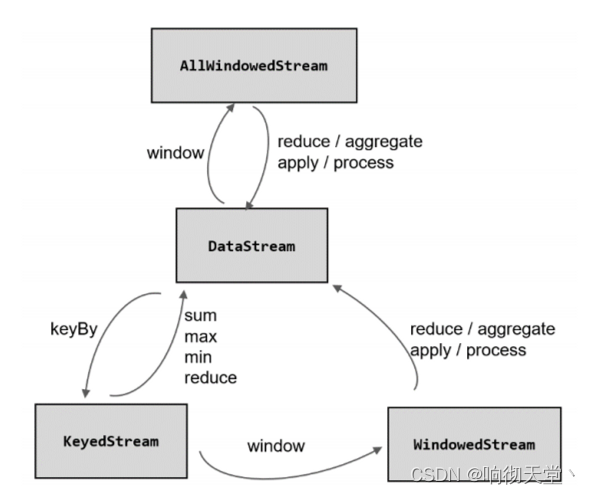
3.1 按键分区窗口(Keyed Windows)
经过按键分区 keyBy 操作后,数据流会按照 key 被分为多条逻辑流(logical streams),这就是 KeyedStream。基于 KeyedStream 进行窗口操作时, 窗口计算会在多个并行子任务上同时
执行。相同 key 的数据会被发送到同一个并行子任务,而窗口操作会基于每个 key 进行单独的处理。所以可以认为,每个 key 上都定义了一组窗口,各自独立地进行统计计算。
在代码实现上,我们需要先对 DataStream 调用.keyBy()进行按键分区,然后再调用.window()定义窗口。
stream.keyBy(...) .window(...)
3.2 非按键分区(Non-Keyed Windows)
如果没有进行 keyBy,那么原始的 DataStream 就不会分成多条逻辑流。这时窗口逻辑只能在一个任务(task)上执行,就相当于并行度变成了 1。所以在实际应用中一般不推荐使用这种方式。
在代码中,直接基于 DataStream 调用.windowAll()定义窗口。
stream.windowAll(...)
3.3 代码中窗口 API 的调用
窗口操作主要有两个部分:窗口分配器(Window Assigners)和窗口函数(Window Functions)。
stream.keyBy(<key selector>) .window(<window assigner>) .aggregate(<window function>)
其中.window()方法需要传入一个窗口分配器,它指明了窗口的类型;而后面的.aggregate()方法传入一个窗口函数作为参数,它用来定义窗口具体的处理逻辑。窗口分配器有各种形式,而窗口函数的调用方法也不只.aggregate()一种,另外,在实际应用中,一般都需要并行执行任务,非按键分区很少用到,所以我们之后都以按键分区窗口为例;如果想要实现非按键分区窗口,只要前面不做 keyBy,后面调用.window()时直接换成.windowAll()就可以了。
3.4 滚动处理时间窗口
窗口分配器由类 TumblingProcessingTimeWindows 提供,需要调用它的静态方法.of()。
stream.keyBy(...).window(TumblingProcessingTimeWindows.of(Time.seconds(5))).aggregate(...)
这里.of()方法需要传入一个 Time 类型的参数 size,表示滚动窗口的大小,我们这里创建了一个长度为 5 秒的滚动窗口。另外,.of()还有一个重载方法,可以传入两个 Time 类型的参数:size 和 offset。第一个参数当然还是窗口大小,第二个参数则表示窗口起始点的偏移量,用这个偏移量可以处理时区。
例如:我们所在的时区是东八区,也就是 UTC+8,跟 UTC 有 8小时的时差。我们定义 1 天滚动窗口时,如果用默认的起始点,那么得到就是伦敦时间每天 0点开启窗口,这时是北京时间早上 8 点。那怎样得到北京时间每天 0 点开启的滚动窗口呢?只要设置-8 小时的偏移量就可以了。
.window(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8)))
3.5 滑动处理时间窗口
窗口分配器由类 SlidingProcessingTimeWindows 提供,同样需要调用它的静态方法.of()。
这里.of()方法需要传入两个 Time 类型的参数:size 和 slide,前者表示滑动窗口的大小,后者表示滑动窗口的滑动步长。我们这里创建了一个长度为 10 秒、滑动步长为 5 秒的滑动窗口。
滑动窗口同样可以追加第三个参数,用于指定窗口起始点的偏移量,用法与滚动窗口完全一致。
stream.keyBy(...).window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))).aggregate(...)
4 窗口函数
定义了窗口分配器,我们只是知道了数据属于哪个窗口,可以将数据收集起来了;至于收集起来到底要做什么,其实还完全没有头绪。所以在窗口分配器之后,必须再接上一个定义窗
口如何进行计算的操作,这就是所谓的“窗口函数”(window functions)。经窗口分配器处理之后,数据可以分配到对应的窗口中,而数据流经过转换得到的数据类型是 WindowedStream。这个类型并不是 DataStream,所以并不能直接进行其他转换,而必须进一步调用窗口函数,对收集到的数据进行处理计算之后,才能最终再次得到 DataStream。
4.1 增量聚合函数(incremental aggregation functions)
4.1.1 归约函数(ReduceFunction)
将窗口中收集到的数据两两进行归约。当我们进行流处理时,就是要保存一个状态;每来一个新的数据,就和之前的聚合状态做归约,这样就实现了增量式的聚合。
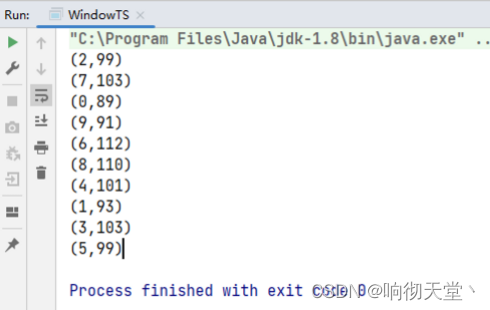
统计每一小时用户的访问量:
package com.rosh.flink.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@AllArgsConstructor
@NoArgsConstructor
@Data
public class UserPojo {
private Integer userId;
private String name;
private String uri;
private Long timestamp;
}
package com.rosh.flink.wartermark;
import com.rosh.flink.pojo.UserPojo;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.security.NoSuchAlgorithmException;
import java.security.SecureRandom;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
public class WindowTS {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<UserPojo> dataDS = env.fromCollection(getUserLists());
//生成有序水位线
SingleOutputStreamOperator<UserPojo> orderStreamDS = dataDS.assignTimestampsAndWatermarks(WatermarkStrategy.<UserPojo>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<UserPojo>() {
@Override
public long extractTimestamp(UserPojo element, long recordTimestamp) {
return element.getTimestamp();
}
}));
//聚合
SingleOutputStreamOperator<Tuple2<Integer, Long>> userDS = orderStreamDS.map(new MapFunction<UserPojo, Tuple2<Integer, Long>>() {
@Override
public Tuple2<Integer, Long> map(UserPojo value) throws Exception {
return Tuple2.of(value.getUserId(), 1L);
}
});
//开窗统计每1小时用户访问了多少次
SingleOutputStreamOperator<Tuple2<Integer, Long>> resultDS = userDS.keyBy(tuple -> tuple.f0)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.reduce(new ReduceFunction<Tuple2<Integer, Long>>() {
@Override
public Tuple2<Integer, Long> reduce(Tuple2<Integer, Long> value1, Tuple2<Integer, Long> value2) throws Exception {
value1.f1 = value1.f1 + value2.f1;
return value1;
}
});
resultDS.print();
env.execute("WarterMarkTest");
}
private static List<UserPojo> getUserLists() throws NoSuchAlgorithmException {
List<UserPojo> lists = new ArrayList<>();
Random random = SecureRandom.getInstanceStrong();
for (int i = 1; i <= 1000; i++) {
String uri = "/goods/" + i;
int userId = random.nextInt(10);
//有序时间
UserPojo userPojo = new UserPojo(userId, "name" + userId, uri, (long) (1000 * i));
//无序时间
lists.add(userPojo);
}
return lists;
}
}
4.1.2 聚合函数(AggregateFunction)
ReduceFunction 可以解决大多数归约聚合的问题,但是这个接口有一个限制,就是聚合状态的类型、输出结果的类型都必须和输入数据类型一样。这就迫使我们必须在聚合前,先将数
据转换(map)成预期结果类型;而在有些情况下,还需要对状态进行进一步处理才能得到输出结果,这时它们的类型可能不同,使用 ReduceFunction 就会非常麻烦。
例如,如果我们希望计算一组数据的平均值,应该怎样做聚合呢?很明显,这时我们需要计算两个状态量:数据的总和(sum),以及数据的个数(count),而最终输出结果是两者的商(sum/count)。如果用 ReduceFunction,那么我们应该先把数据转换成二元组(sum, count)的形式,然后进行归约聚合,最后再将元组的两个元素相除转换得到最后的平均值。本来应该只是一个任务,可我们却需要 map-reduce-map 三步操作,这显然不够高效。
于是自然可以想到,如果取消类型一致的限制,让输入数据、中间状态、输出结果三者类型都可以不同,不就可以一步直接搞定了吗?Flink 的 Window API 中的 aggregate 就提供了这样的操作。直接基于 WindowedStream 调用.aggregate()方法,就可以定义更加灵活的窗口聚合操作。这个方法需要传入一个AggregateFunction 的实现类作为参数。AggregateFunction 在源码中的定义如下:
/**
*
* The type of the values that are aggregated (input values)
* The type of the accumulator (intermediate aggregate state).
* The type of the aggregated result
*
*/
public interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable
{
/**
* 创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次。
*/
ACC createAccumulator();
/**
* 将输入的元素添加到累加器中。这就是基于聚合状态,对新来的数据进行进一步聚合的过程。方法传入两个参数:当前新到的数据 value,和当前的累加器accumulator;
* 返回一个新的累加器值,也就是对聚合状态进行更新。每条数据到来之后都会调用这个方法。
*/
ACC add(IN value, ACC accumulator);
/**
* 从累加器中提取聚合的输出结果。也就是说,我们可以定义多个状态,然后再基于这些聚合的状态计算出一个结果进行输出。比如之前我们提到的计算平均
* 值,就可以把 sum 和 count 作为状态放入累加器,而在调用这个方法时相除得到最终结果。这个方法只在窗口要输出结果时调用。
*/
OUT getResult(ACC accumulator);
/**
* 合并两个累加器,并将合并后的状态作为一个累加器返回。这个方法只在需要合并窗口的场景下才会被调用;最常见的合并窗口(Merging Window)的场景
* 就是会话窗口(Session Windows)。
*/
ACC merge(ACC a, ACC b);
}
所以可以看到,AggregateFunction 的工作原理是:首先调用 createAccumulator()为任务初始化一个状态(累加器);而后每来一个数据就调用一次 add()方法,对数据进行聚合,得到的
结果保存在状态中;等到了窗口需要输出时,再调用 getResult()方法得到计算结果。很明显,与 ReduceFunction 相同,AggregateFunction 也是增量式的聚合;而由于输入、中间状态、输
出的类型可以不同,使得应用更加灵活方便。
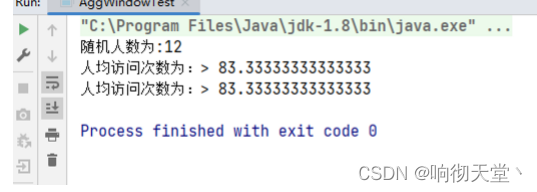
·统计人均访问次数:
package com.rosh.flink.wartermark;
import com.rosh.flink.pojo.UserPojo;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.security.NoSuchAlgorithmException;
import java.security.SecureRandom;
import java.util.*;
public class AggWindowTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<UserPojo> userDS = env.fromCollection(getUserLists()).assignTimestampsAndWatermarks(
WatermarkStrategy.<UserPojo>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<UserPojo>() {
@Override
public long extractTimestamp(UserPojo element, long recordTimestamp) {
return element.getTimestamp();
}
})
);
//统计5秒内,人均访问次数
SingleOutputStreamOperator<Double> resultDS = userDS.keyBy(key -> true)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(new PeopleHourAvgCount());
resultDS.print("人均访问次数为:");
env.execute("AggWindowTest");
}
private static class PeopleHourAvgCount implements AggregateFunction<UserPojo, Tuple2<HashSet<Integer>, Long>, Double> {
/**
* 初始化累加器
*/
@Override
public Tuple2<HashSet<Integer>, Long> createAccumulator() {
return Tuple2.of(new HashSet<>(), 0L);
}
/**
*
*/
@Override
public Tuple2<HashSet<Integer>, Long> add(UserPojo value, Tuple2<HashSet<Integer>, Long> accumulator) {
//distinct userId
accumulator.f0.add(value.getUserId());
//次数+1
accumulator.f1 = accumulator.f1 + 1;
//返回累加器
return accumulator;
}
@Override
public Double getResult(Tuple2<HashSet<Integer>, Long> accumulator) {
return accumulator.f1 * 1.0 / accumulator.f0.size();
}
@Override
public Tuple2<HashSet<Integer>, Long> merge(Tuple2<HashSet<Integer>, Long> a, Tuple2<HashSet<Integer>, Long> b) {
return null;
}
}
/**
* 获取随机人数的1000次访问
*/
private static List<UserPojo> getUserLists() throws NoSuchAlgorithmException {
List<UserPojo> lists = new ArrayList<>();
Random random = SecureRandom.getInstanceStrong();
//获取随机人数
int peopleCount = random.nextInt(20);
System.out.println("随机人数为:" + peopleCount);
for (int i = 1; i <= 1000; i++) {
String uri = "/goods/" + i;
int userId = random.nextInt(peopleCount);
//有序时间
UserPojo userPojo = new UserPojo(userId, "name" + userId, uri, new Date().getTime());
//无序时间
lists.add(userPojo);
}
return lists;
}
}
4.2 全窗口函数(full window functions)
窗口操作中的另一大类就是全窗口函数。与增量聚合函数不同,全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。
ProcessWindowFunction 是 Window API 中最底层的通用窗口函数接口。之所以说它“最底层”,是因为除了可以拿到窗口中的所有数据之外,ProcessWindowFunction 还可以获取到一个“上下文对象”(Context)。这个上下文对象非常强大,不仅能够获取窗口信息,还可以访问当前的时间和状态信息。这里的时间就包括了处理时间(processing time)和事件时间水位线(event time watermark)。这就使得 ProcessWindowFunction 更加灵活、功能更加丰富。事实上,ProcessWindowFunction 是 Flink 底层 API——处理函数(process function)中的一员。
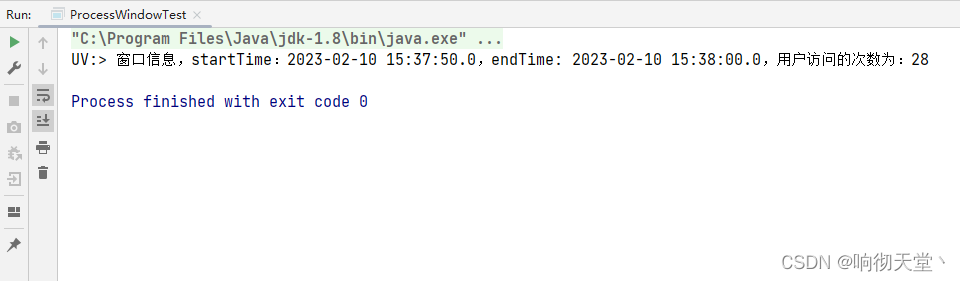
统计10秒访问UV:
package com.rosh.flink.wartermark;
import com.rosh.flink.pojo.UserPojo;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.security.NoSuchAlgorithmException;
import java.security.SecureRandom;
import java.sql.Timestamp;
import java.util.*;
public class ProcessWindowTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<UserPojo> userDS = env.fromCollection(getUserLists());
//水位线
SingleOutputStreamOperator<UserPojo> watermarks = userDS.assignTimestampsAndWatermarks(WatermarkStrategy.<UserPojo>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<UserPojo>() {
@Override
public long extractTimestamp(UserPojo element, long recordTimestamp) {
return element.getTimestamp();
}
}));
//开窗10秒UV统计
SingleOutputStreamOperator<String> resultDS = watermarks.keyBy(key -> true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new UserUVCount());
resultDS.print("UV:");
env.execute("ProcessWindowTest");
}
private static class UserUVCount extends ProcessWindowFunction<UserPojo, String, Boolean, TimeWindow> {
@Override
public void process(Boolean aBoolean, ProcessWindowFunction<UserPojo, String, Boolean, TimeWindow>.Context context, Iterable<UserPojo> elements, Collector<String> out) throws Exception {
//用户集合
HashSet<Integer> hashSet = new HashSet<>();
for (UserPojo user : elements) {
hashSet.add(user.getUserId());
}
//获取时间信息
long start = context.window().getStart();
long end = context.window().getEnd();
String rs = "窗口信息,startTime:" + new Timestamp(start) + ",endTime: " + new Timestamp(end) + ",用户访问的次数为:" + hashSet.size();
out.collect(rs);
}
}
private static List<UserPojo> getUserLists() throws NoSuchAlgorithmException {
List<UserPojo> lists = new ArrayList<>();
Random random = SecureRandom.getInstanceStrong();
int userCount = random.nextInt(100);
for (int i = 1; i <= 1000; i++) {
String uri = "/goods/" + i;
int userId = random.nextInt(userCount);
//有序时间
UserPojo userPojo = new UserPojo(userId, "name" + userId, uri, new Date().getTime());
//无序时间
lists.add(userPojo);
}
return lists;
}
}
4.3 增量聚合和全窗口函数的结合使用
增量聚合函数处理计算会更高效。全窗口函数的优势在于提供了更多的信息,可以认为是更加“通用”的窗口操作。所以在实际应用中,我们往往希望兼具这两者的优点,把它们结合在一起使用。Flink 的Window API 就给我们实现了这样的用法。
在调用 WindowedStream 的.reduce()和.aggregate()方法时,只是简单地直接传入了一个 ReduceFunction 或 AggregateFunction 进行增量聚合。除此之外,其实还可以传入第二个参数:一个全窗口函数,可以是 WindowFunction 或者 ProcessWindowFunction。
// ReduceFunction 与 WindowFunction 结合
public <R> SingleOutputStreamOperator<R> reduce( ReduceFunction<T> reduceFunction, WindowFunction<T, R, K, W> function)
// ReduceFunction 与 ProcessWindowFunction 结合
public <R> SingleOutputStreamOperator<R> reduce( ReduceFunction<T> reduceFunction, ProcessWindowFunction<T, R, K, W> function)
// AggregateFunction 与 WindowFunction 结合
public <ACC, V, R> SingleOutputStreamOperator<R> aggregate(AggregateFunction<T, ACC, V> aggFunction, WindowFunction<V, R, K, W> windowFunction)
// AggregateFunction 与 ProcessWindowFunction 结合
public <ACC, V, R> SingleOutputStreamOperator<R> aggregate( AggregateFunction<T, ACC, V> aggFunction, ProcessWindowFunction<V, R, K, W> windowFunction)
这样调用的处理机制是:基于第一个参数(增量聚合函数)来处理窗口数据,每来一个数据就做一次聚合;等到窗口需要触发计算时,则调用第二个参数(全窗口函数)的处理逻辑输
出结果。需要注意的是,这里的全窗口函数就不再缓存所有数据了,而是直接将增量聚合函数的结果拿来当作了 Iterable 类型的输入。一般情况下,这时的可迭代集合中就只有一个元素了。
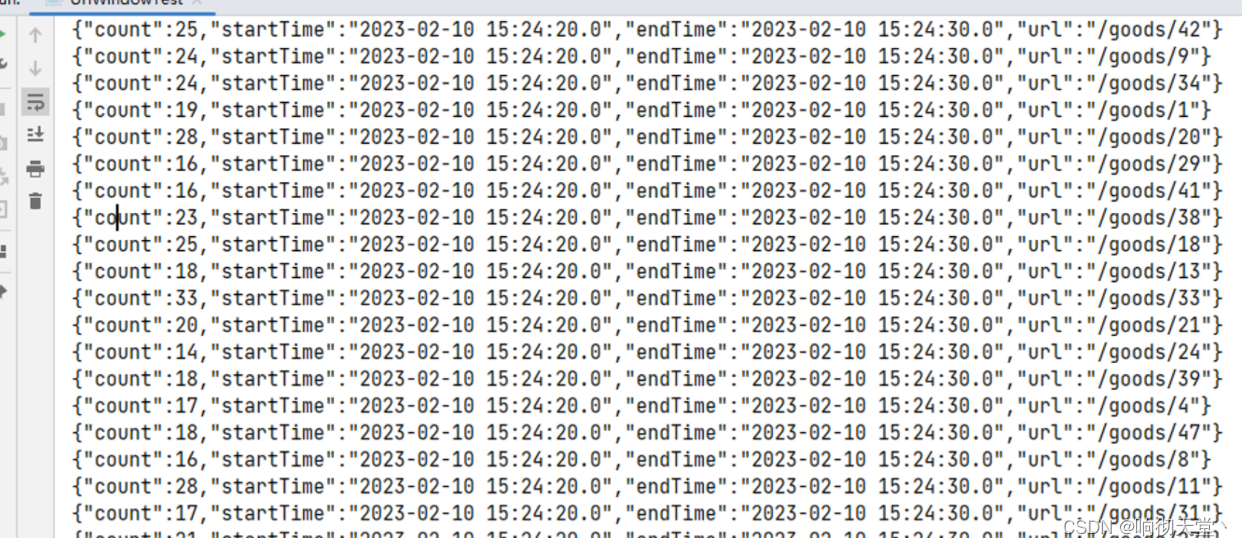
统计10秒的url浏览量:
package com.rosh.flink.wartermark;
import com.alibaba.fastjson.JSONObject;
import com.rosh.flink.pojo.UserPojo;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.security.NoSuchAlgorithmException;
import java.security.SecureRandom;
import java.sql.Timestamp;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Random;
public class UrlWindowTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//读取数据源
DataStreamSource<UserPojo> userDS = env.fromCollection(getUserLists());
//水位线
SingleOutputStreamOperator<UserPojo> waterDS = userDS.assignTimestampsAndWatermarks(WatermarkStrategy.<UserPojo>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<UserPojo>() {
@Override
public long extractTimestamp(UserPojo element, long recordTimestamp) {
return element.getTimestamp();
}
}));
//url count
SingleOutputStreamOperator<Tuple2<String, Long>> urlDS = waterDS.map(new MapFunction<UserPojo, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(UserPojo value) throws Exception {
return Tuple2.of(value.getUri(), 1L);
}
});
SingleOutputStreamOperator<JSONObject> resultDS = urlDS.keyBy(data -> data.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
value1.f1 = value1.f1 + value2.f1;
return value1;
}
}, new WindowFunction<Tuple2<String, Long>, JSONObject, String, TimeWindow>() {
@Override
public void apply(String s, TimeWindow window, Iterable<Tuple2<String, Long>> input, Collector<JSONObject> out) throws Exception {
Tuple2<String, Long> tuple2 = input.iterator().next();
JSONObject jsonObject = new JSONObject();
jsonObject.put("url", tuple2.f0);
jsonObject.put("count", tuple2.f1);
new Timestamp(window.getStart());
jsonObject.put("startTime", new Timestamp(window.getStart()).toString());
jsonObject.put("endTime", new Timestamp(window.getEnd()).toString());
out.collect(jsonObject);
}
});
resultDS.print();
env.execute("UrlWindowTest");
}
private static List<UserPojo> getUserLists() throws NoSuchAlgorithmException {
List<UserPojo> lists = new ArrayList<>();
Random random = SecureRandom.getInstanceStrong();
for (int i = 1; i <= 1000; i++) {
//随机生成userId、goodId
int userId = random.nextInt(100);
int goodId = random.nextInt(50);
String uri = "/goods/" + goodId;
//有序时间
UserPojo userPojo = new UserPojo(userId, "name" + userId, uri, new Date().getTime());
//无序时间
lists.add(userPojo);
}
return lists;
}
}

大数据从业者之家,一起探索大数据的无限可能!
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)